
redis
Operational
Assess your knowledge
Learning Objectives
- Recognize the different deployment methods and architecture
- Define appropriate system requirements for redis
- Understand CRUD methodology and how it relates to redis
- Install and configure redis
- Implement persistence and replication within redis deployments
- Integrate redis within your application stack
Deployment Methods and Architecture
Deployment Methods
 Stand Alone
Stand Alone
- Installed on a single node
- No failover/redundancy
- Dev environments only
App Server
Redis Server
- Installed on two or more nodes with one master and one or more slaves
- Slaves replicate from the master or other slaves
- Can be used to scale read performance
- No automatic failover
Master/Slave

Sentinel
- Automates the failover of Master/Slave deployments
- Separate processes that run alongside and monitor Redis on each node
- All slaves replicate from the master
- Recommend an odd number of slave nodes with a minimum of three for proper election of a new master
Clustering
- Will be included with Redis 3.0.0 (still in beta)
- Designed for high availability, high performance, and linear scalability
- Key space is split into 16384 slots, which are distributed between multiple master nodes
- Recommended limit of 1000 master nodes (actual maximum is 16384)
- Each master can have multiple slaves for added redundancy
- Slaves are automatically promoted if a master fails
Architecture
Caching Server
- Redis sits alongside your application servers
- Read requests are first sent to Redis
- If the data doesn’t exist in the cache, the request is sent to your primary datastore
- Results from the primary datastore as well as write requests are saved into Redis to serve future requests
- A TTL (time to live) value can be assigned to each key so that cached content automatically expires
Redis Caching

Message Queue
- Application servers insert messages into a Redis List
- Worker nodes read the next value in the List and perform the requested work
- Results are saved to your primary datastore
- App servers utilize the results saved in the primary datastore
- The primary datastore could also be Redis!
Message Queue

Primary Datastore
- Uses Sentinel or Clustering for high availability and scalability
- App servers can send read requests to slave nodes for scalable read performance
- Persistence should be enabled to avoid data loss in the event of a complete outage
Primary Datastore

Scalable Production Config

System Requirements
Where can Redis run?
Linux, OSX, OpenBSD, NetBSD, FreeBSD
- Written in ANSI C
- Works in most POSIX systems
Windows
- No official support for Windows builds
- Microsoft develops and maintains a Win32-64 experimental version of Redis.
Memory Considerations
- Lots of RAM
- Example: 1 Million keys with the key being the natural numbers from 0 to 999999 and the string "Hello World" as value uses 100MB on my Intel MacBook (32bit)
- 64 bit vs 32 bit systems
Single Threaded
- CPU speed nearly irrelevant
- No benefit from multiple cores.
Install and Configure Redis
Setup
Lab: Setup
For setup you will need to acquire login information for the box you are working on for the lab.
- Log into dojo to get the address and login credentials for your lab box.
- SSH as your user into the the lab machine
- Ensure your user has sudo access
Install
Lab: Install
This installation procedure will walk you through installing the current stable version of Redis on an Ubuntu 12.04 LTS server.
-
Add the redis server PPA to the server’s apt configuration
add-apt-repository ppa:chris-lea/redis-server - When prompted with: “Press [ENTER] to continue or ctrl-c to cancel adding it”
- Update the apt cache
- Install the redis server
Test
Lab: Test
Verify the server process is installed and operational.
- Open the redis cli
- Set a key
- Get the key to verify it was set
- The returned value should be “1”
Set Hints
Security
Redis comes by default in it’s least secure configuration.
- There is no access password
- The server process is bound to the public interface.
- There is no encryption.
Encryption
- Encryption does not exist in the Redis server nor in it’s client
- All data is sent in the clear
- An SSL proxy can be used to protect the data being sent between the Redis client and server but this process lives outside of Redis’ knowledge.
Common Configuration
Lab: Setting an Access Password I
- Open ‘/etc/redis/redis.conf’ in your favorite text editor (which *should* be vi if you have any self respect)
- Find the line that is commented out but contains: requirepass foobared
- Uncomment the line and set the password to something super secure
- Restart the redis server
Lab: Setting an Access Password II
- Open ‘/etc/redis/redis.conf’ in your favorite text editor (which *should* be vi if you have any self respect)
- Find the line that is commented out but contains: bind 127.0.0.1
- Uncomment that line, save the file and exit the editor.
- Restart the redis server
Lab: Test the new configuration
- Log into redis on the localhost address
- Authenticate
- Set a key
- Get the key to verify it was set.
- The returned value should be “1”
CRUD Operations in Redis
What is CRUD?
C reate R ead U pdate D elete
Data Types
Strings
Strings are the most basic kind of Redis value. Redis Strings are binary safe, this means that a Redis string can contain any kind of data, for instance a JPEG image or a serialized Ruby object.
String Commands

SET Key Value = Create
Redis Lists are simply lists of strings, sorted by insertion order. It is possible to add elements to a Redis List pushing new elements on the head (on the left) or on the tail (on the right) of the list.
List

[A, B, C, D]
List Commands

LPUSH Key Value = Create and Update
RPOP Key = Delete
Redis Sets are an unordered collection of Strings. It is possible to add, remove, and test for existence of members in O(1) (constant time regardless of the number of elements contained inside the Set).
Set

{A, B, C, D}
Set Commands

SMEMBERS myset = Read
Redis Hashes are maps between string fields and string values, so they are the perfect data type to represent objects (eg: A User with a number of fields like name, surname, age, and so forth):
Hash

{key:value}
{field1: “A”, field2: “B”...}
Hash Commands

HGET myhash field1 = Read
Redis Sorted Sets are, similar to Redis Sets, non repeating collections of Strings. The difference is that every member of a Sorted Set is associated with score, that is used in order to take the sorted set ordered, from the smallest to the greatest score. While members are unique, scores may be repeated.
Sorted Set

{value:score}
{C:1, D:2, A:3, B:4}
Sorted Set Commands
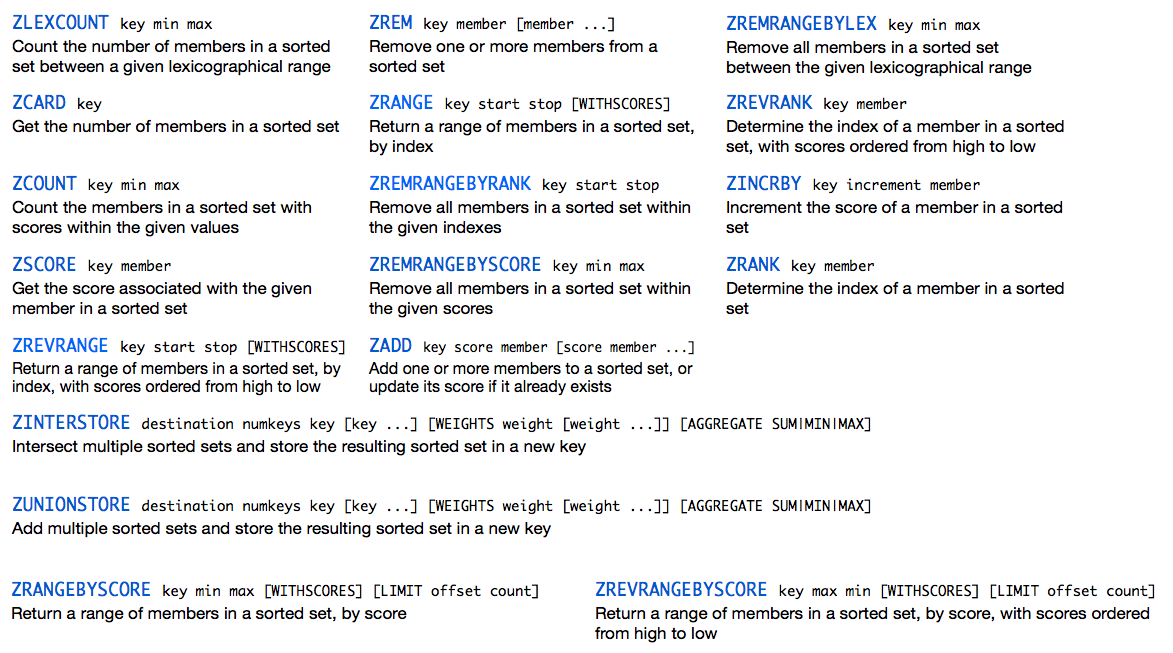
ZINCBY key increment member = Update
ZREM Key Member = Delete
Lab
- Login to a server which is running Redis
- From the CLI perform a number of CRUD operations; like the ones we just saw.
- Attempt the following:
- Add an Element to the Right end of a list
- Create a list of your friends names and return them all
- Set a string to 1 and increment it by 10
- Create a sorted set of your top 3 movies sorted by their runtime
- Setup a hash table and return all elements
Persistence and Replication
Two Forms of Persistence:
- RDB - Redis Dump
- AOF - Append Only File



 Using RDB
Using RDB


 Using AOF
Using AOF
Lab: Setup
- Open two terminals to the server.
- Stop the running instance of redis
- In one run the command “redis-server”. It should show the server output on stdout. Keep this window open so you can observe the changes as they happen.
- Run all following commands in the second terminal.
Lab: RDB part 1
- run “redis-cli config get save”. This will show current persistence settings.
- run redis-cli config set save "” (note the double double quote)
-
create dozens of keys in redis:
for x in `seq 20`; do redis-cli set test-key-$x ‘foo’; done - Observe in the first terminal that there is no entries about saving the RDB.
LAB: RDB part 2
-
run redis-cli config set save ‘5 10’
to re-enable RDB persistence - Create 20 changes: for x in `seq 20`; do redis-cli set test-key2-$x ‘foo’; done
- Observe log entries in the first terminal indicating the RDB file was saved
Lab: AOF
- AOF is disabled by default. Run “redis-cli config set appendonly yes” to enable it.
- Observe the output from the first terminal indicating the AOF file was created.
Replication
Redis Replication
- Master/Slave Replication
- Chained replication
Configuring Replication
- Slave of server port
- This directive will tell the redis instance to treat the given server on the given port connection as the master.
- Using “slaveof no one” promotes the node to a master.
Lab: Setup
- Open three terminals to the server
- In the first terminal run “redis-server”
- In the second terminal run “redis-server --port 6380”
Lab: Replication
- In the third terminal run “redis-cli -p 6380 slaveof localhost 6379”
- Observe the server output in terminals 1 & 2. Note the second instance will slave to the first. When replication has finished (should be instant), continue.
- In the third terminal run “redis-cli set foo bar” to create a key.
- Run “redis-cli -p 6380 get foo”. This will result in “bar” showing. This demonstrates the slave is in sync.
- Now run the following commands to see and compare the configuration/replication status:
- redis-cli info replication
- redis-cli -p 6380 info replication
Redis Availability
Redis Sentinel
Redis Sentinel | What it is
- A failover monitor for Redis
- An option for the redis-server binary
- Manages the running configuration of master with one or more slaves
Redis Sentinel | What it doesn't do
- Manage client connections
- Store configuration changes to disk
Sentinel Nodes
- Should be run not on the master.
- Could be run from slaves
- Best run from client nodes and slaves.
Lab: redis-sentinel deployment
Setup
- Open ## terminals to the server
- Terminal 1 run “redis-server”
- Terminal 2 run “redis-server --port 6380 --slaveof localhost 6379”
- Terminal 3 run “redis-server --port 6381 --slaveof localhost 6379”
Goal: Configure and confirm A redis-sentinel deployment
Lab: redis-sentinel deployment
- Terminal 4 create a file named sentinel-1.conf with the following contents:
- port 26379
- sentinel monitor mymaster 127.0.0.1 6379 2
- sentinel down-after-milliseconds mymaster 3000
- sentinel parallel-syncs mymaster 1
- sentinel failover-timeout mymaster 180000
Lab: redis-sentinel deployment
- Terminal 4 create a file named sentinel-2.conf with the following contents:
- port 26380
- sentinel monitor mymaster 127.0.0.1 6379 2
- sentinel down-after-milliseconds mymaster 3000
- sentinel parallel-syncs mymaster 1
- sentinel failover-timeout mymaster 180000
Lab: redis-sentinel deployment
- Terminal 4 create a file named sentinel-3.conf with the following contents:
- port 26381
- sentinel monitor mymaster 127.0.0.1 6379 2
- sentinel down-after-milliseconds mymaster 3000
- sentinel parallel-syncs mymaster 1
- sentinel failover-timeout mymaster 180000
Lab: redis-sentinel deployment
- Terminal 5 run “redis-server sentinel-1.conf --sentinel”
- Terminal 6 run “redis-server sentinel-2.conf --sentinel”
- Terminal 7 run “redis-server sentinel-3.conf --sentinel”
Lab: redis-sentinel deployment
- At this point you should have three terminals running an instance of Redis, three terminals running an instance of sentinel, and one to run commands in.
- In each of your sentinel instances’ output you should see output like the following:
+slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379
+slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
+sentinel sentinel 127.0.0.1:26380 127.0.0.1 26380 @ mymaster 127.0.0.1 6379
Lab: Kill the Master
Have at least one sentinel window visible and, from the command terminal, issue the following command:
redis-cli debug segfault
Lab: Kill the Master
At this point you should see the master die. You will then see lines similar to the following in your setinels’ output:
+sdown master mymaster 127.0.0.1 6379
+new-epoch 1
+vote-for-leader f8e45651835456013ec43c8681bed81329ac457c 1
+odown master mymaster 127.0.0.1 6379 #quorum 3/2
+switch-master mymaster 127.0.0.1 6379 127.0.0.1 6380
+slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6380
+slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6380
+sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6380
Lab: Restart the Original Master
- Now you will restart the original master.
- Go to your master’s terminal (should be terminal 1). You will know you have the right one by the fact that it will show it died do to a segfault.
- Restart it with the following command:
“redis-server”
Lab: Restart the Original Master
Upon starting, the sentinels will tell it it is a slave and reconfigure it. You will see output similar to the following to show this:
-sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6380
+convert-to-slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6
Redis Integration

Application Stack
Redis into PHP Stack

Session Handler
Easiest way to implement Redis into your [PHP] stack is by using the Redis session handler
Enabling Redis Session Handler in your PHP Stack
- Compile the PHP extension for Redis to enable the session handler
- Once downloaded and extracted, enter the directory and run:
phpize
./configure
make
sudo make install
Enabling Redis Session Handler in your PHP Stack
Once installed, you will need to edit your php.ini and add the line:
extension=redis.so
Enable the session save handler in your php.ini by changing the session save handler and path:
session.save_handler = redis
session.save_path = 'tcp://localhost:6379'

Magento can use Redis for...
- Sessions
-
Cache
-
Full Page Cache (Enterprise only)
Why Redis?
- Fastest and most efficient backend for Magento.
- Can be shared for multiple load-balanced nodes, and supersedes the use of Memcache for Magento cache backend.
-
Also used for the <slow_backend>
, unlike with Memcache, so all aspects of cache are in memory.

Where should Redis live?
How to configure Redis for Magento?
https://one.rackspace.com/pages/viewpage.action?title=Redis+for+Magento&spaceKey=MGC
Redis with MongoDB

Redis and Mongo make a great match


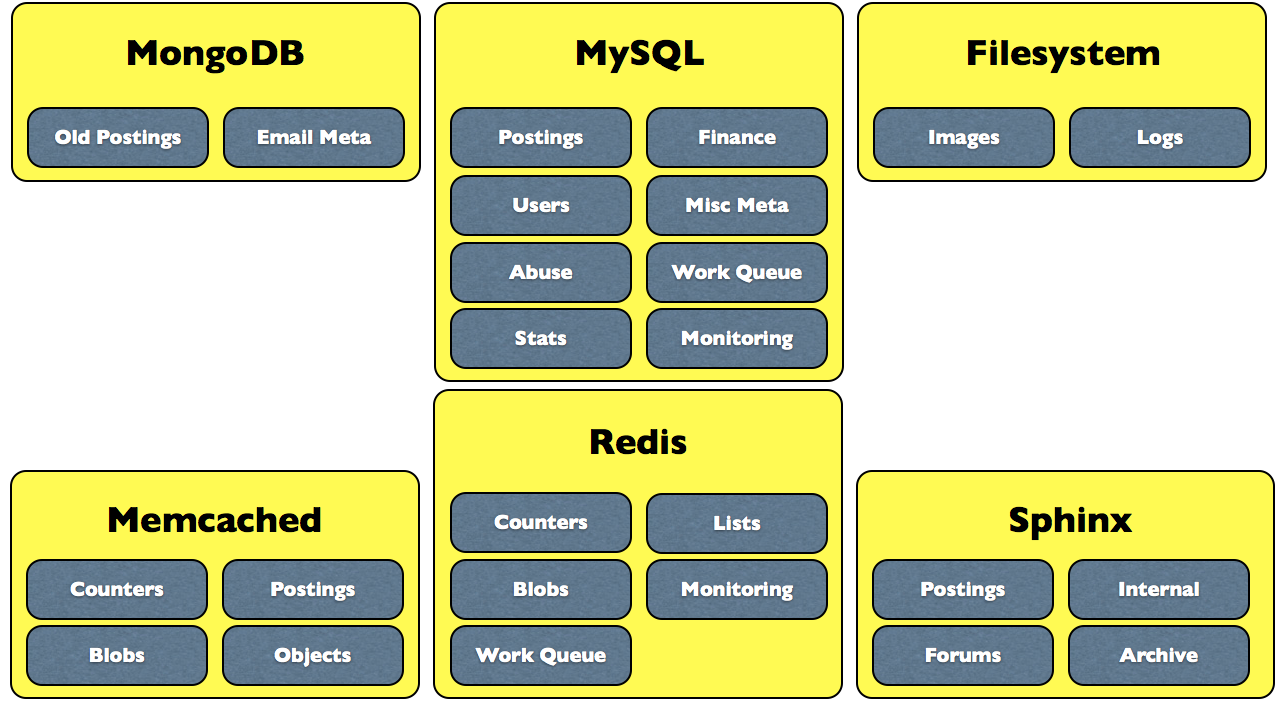
Data Storage at Craigslist
- MySQL
-
Memcached
- Redis
- MongoDB
- Sphinx
- Filesystem

Redis with Celery

Celery
- Celery is a simple, flexible and reliable distributed system to process vast amounts of messages, while providing operations with the tools required to maintain such a system.
-
It’s a task queue with focus on real-time processing, while also supporting task scheduling.
Installation
For the Redis support you have to install additional dependencies. You can install both Celery and these dependencies in one go using the celery[redis] bundle:
$ pip install -U celery[redis]
Configuration
Configuration is easy, just configure the location of your Redis database:
BROKER_URL = 'redis://localhost:6379/0'
Where the URL is in the format of:
redis://:password@hostname:port/db_number
all fields after the scheme are optional, and will default to localhost on port 6379, using database 0.
Visibility Timeout
The visibility timeout defines the number of seconds to wait for the worker to acknowledge the task before the message is redelivered to another worker.
This option is set via the BROKER_TRANSPORT_OPTIONS setting:
BROKER_TRANSPORT_OPTIONS = {
'visibility_timeout'
: 3600} # 1 hour.
The default visibility timeout for Redis is 1 hour.
Results
If you also want to store the state and return values of tasks in Redis, you should configure these settings:
CELERY_RESULT_BACKEND = 'redis://localhost:6379/0'
Resque
What is Resque?
- Resque is a Redis-backed library for creating background jobs, placing those jobs on multiple queues, and processing them later.
- Background jobs can be any Ruby class or module that responds to perform.
- Your existing classes can easily be converted to background jobs or you can create new classes specifically to do work. Or, you can do both.
- Common use cases include sending emails and processing data.
Resque comprises three parts:
- A Ruby library for creating, querying, and processing jobs
- A Rake task for starting a worker which processes jobs
- A Sinatra app for monitoring queues, jobs, and workers
Setting up Resque with Rails and Redis to Go

Set up Rails
$ sudo gem install rails --pre
Create the Application
$ rails new cookie_monster
$ cd cookie_monster
Modify the Gemfile to include Resque
source 'http://rubygems.org'
gem 'rails', '3.0.0.rc'
gem 'sqlite3-ruby', :require => 'sqlite3'
gem 'resque'
gem 'SystemTimer'
Install all of the gems and dependencies using Bundler.
$ bundle install
Set up Redis to Go
ENV["REDISTOGO_URL"] ||= "redis://username:password@host:1234/"
(ENV["REDISTOGO_URL"])
Resque.redis = Redis.new(:host => uri.host, :port => uri.port, :password => uri.password)
Create the job named Consume in app/jobs/eat.rb
module Eat
@queue = :food
def perform(food)
puts "Ate #{food}!"
end
end
Inside config/initializers/resque.rb place the following code so that app/jobs/eat.rb is loaded.
Dir["#{Rails.root}/app/jobs/*.rb"].each { |file| require file }
Enqueue the Job: Create a controller named eat.
$ rails g controller eat
Create a route for the controller in config/routes.rb
CookieMonster::Application.routes.draw do
match 'eat/:food' => 'eat#food'
end
Create the action in the controller.
class EatController < ApplicationController
def food Resque.enqueue(Eat, params[:food]) render :text => "Put #{params[:food]} in fridge to eat later."
end
end
Sidekiq
Sidekiq
- Simple, efficient background processing for Ruby
- Redis provides data storage for Sidekiq. It holds all the job data along with runtime and historical data to power Sidekiq's Web UI

Setting the Location of your Redis server for Sidekiq
using Sidekiq's configure blocks
- By default, Sidekiq assumes Redis is located at localhost:6379
- This is fine for development but for many production deployments you will probably need to point Sidekiq to an external Redis server
using Sidekiq's configure blocks
- to configure the location of Redis, you must define both the Sidekiq.configure_server and Sidekiq.configure_client blocks
- To do this throw the following code into config/initializers/sidekiq.rb
Sidekiq.configure_server do |config|
config.redis = { :url => 'redis://redis.example.com:7372/12', :namespace => 'mynamespace' }
end
Sidekiq.configure_client do |config|
config.redis = { :url => 'redis://redis.example.com:7372/12', :namespace => 'mynamespace' }
end
Application Frameworks




Lua
- Lua is a powerful, fast, lightweight, embeddable scripting language.
- Redis includes server-side scripting with the Lua programming language. This lets you perform a variety of operations inside Redis, which can both simplify your code and increase performance.
node_redis
- This is a complete Redis client for node.js. It supports all Redis commands, including many recently added commands like EVAL from experimental Redis server branches.
redis-rb
- A Ruby client library for Redis.
- Tries to match Redis' API one-to-one, while still providing an idiomatic interface. It features thread-safety, client-side sharding, pipelining, and an obsession for performance.
redis-py
- The Python interface to the Redis key-value store.
Assess your knowledge
A massive thanks to the content dev team...
Bill Anderson
Chris Caillouet
Chris Old
Daniel Morris
Daniel Salinas
David Grier
Joe Engel
Juan Montemayor
Leonard Packham
Mark Lessel
Matthew Barker
Redis Operational
By Rackspace University




