Understanding and Applying Embedding Vectors in AI Solutions
Rainer Stropek
Passionate software developer
IT-Entrepreneur, CoderDojo-Mentor, Teacher
software architects gmbh
rainer@software-architects.at
https://rainerstropek.me
https://bit.ly/oop-embeddings

What are Embedding Vectors?
- On a scale between 0 and 10, how open are you to new experiences?
- What about Agreeableness ("Verträglichkeit")?
- Conscientiousness ("Pflichtbewusstsein")?
- Extraversion ("Extrovertiertheit")?
100
100
- We can use these personality embeddings for:
- Sorting based on similarity
- Clustering
- etc.
Example: Personality Embeddings
See also: The Illustrated Word2vec
Working With Vectors
- Cosine simiarity
- OpenAI Embeddings are normalized -> just dot product
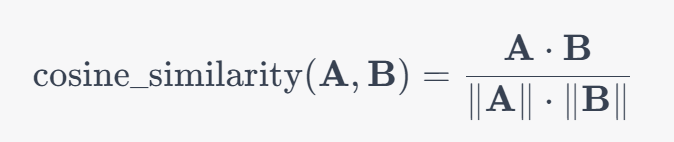
- Getting an embedding vector with OpenAI
POST https://oai-4.openai.azure.com/openai/deployments/embeddings/
embeddings?api-version=2023-03-15-preview
api-key: {{$dotenv OAI_API_KEY}}
{
"input": "Here is the text for which you want to calculate the vector",
"model": "text-embedding-3-large"
}
Working With Vectors
| Word/Phrase 1 | Word/Phrase 2 | Cosine Similarity |
|---|---|---|
| king | queen | 0.9154 |
| king | König | 0.8854 |
| king | frog | 0.8209 |
| king | programming language | 0.7570 |
Embedding Vectors
- LLMs can convert text into vectors
- OpenAI: 1536 dimensions
- Similarity of vector reflects similarity of text
- Independent of language
- Based on meaning, not technical difference of characters
- Areas of application (examples)
- Find duplicates
- Clustering
- Search for relevant data in databases (vector search)
- Can be combined with other search techniques
OpenAI
ChatGPT
End User
- Rebuilding ChatGPT is boring and meaningless
- Exception: Customized ChatGPT version embedded in company network
- What we want:
- Specific behavior
- Integration of app-specific logic and data (structured or unstructured)
- Smart automation of processes
Application Programming Interface (API)
Model
Messages
(Chat History)
System, User, Assistant, Function
Functions
Options
OpenAI
Choices
Usage
POST https://oai-4.openai.azure.com/openai/deployments/
complete-4/chat/completions?api-version=2023-09-01-preview
api-key: {{$dotenv OAI_API_KEY}}
Content-Type: application/json
{
"messages": [
{
"role": "system",
"content": "You are a salesperson at a car dealer."
},
{
"role": "user",
"content": "Hi! I am unsure if I should buy a van or a sports car. What do you think?"
}
]
}OpenAI
Application
End User
Retrieval Augmented Generation (RAG)
- Query
- Full-text search
- Vector search
- ...
Question,
Query,
Command,
...
DB
Prompt
RAG With C#
- NuGet Packages
-
Azure.AI.OpenAI
-
Azure.Identity
-
Azure.Search.Documents
-
// Generate embeddings
async Task<float[]> GenerateEmbeddings(string text, OpenAIClient openAIClient)
{
var response = await openAIClient.GetEmbeddingsAsync(
new EmbeddingsOptions(embeddingsDeployment, [text]));
return response.Value.Data[0].Embedding.ToArray();
}
RAG With C#
// Generate the embedding for the query
var queryEmbeddings = await GenerateEmbeddings(query, openAIClient);
// Perform the vector similarity search
var searchOptions = new SearchOptions
{
VectorSearch = new()
{
Queries =
{
new VectorizedQuery(queryEmbeddings)
{
Fields = { "contentVector" }, Exhaustive = true, KNearestNeighborsCount = 3
}
},
}
};
SearchResults<SearchDocument> response = await searchClient.SearchAsync<SearchDocument>(null, searchOptions);
Build prompt from results
Document Processing
Why Document Pre-Processing?
- Split documents in segments to avoid hitting token limits
- Handle large documents that would exceed token limits
-
Split documents in segments to reduce costs
- Feed smaller text chunks to the LLM
- Completion requests use fewer tokens, i.e. cost less
- Format conversion
- Convert non-text formats (e.g. scans, PDFs) into text
- ⚠️ Can be difficult because of complex layout 🔗
Segmentation Strategies
- Fixed-length Segmentation
- Simple, but naive
- Semantic Segmentation
- Sentences, paragraphs, sections
- Topic-based segmentation
- Split based on identified topics or thematic shifts
- Query-based segmentation
- Useful if typical queries are known upfront
- Hybrid approaches
- Combine some of the strategies mentioned above
Challenges and Solutions
- Context Preservation
- Include key information at the beginning of each new segment
- E.g. titles, tags, keywords, summaries
Living with the Volkswagen ID.4
[...]
First impressions first
The ID.4 we’ve been testing was in the entry-level Life trim level but fitted with the bigger 77kWh
battery pack and the mid-level 204hp single electric motor of the Pro Performance drivetrain.
At £44,480 on the road – and £47,595 with options as tested – it’s towards the lower end of
what you can spend on one of these.
[...]
How difficult was it to keep charged?
[...] This in combination with the increasingly colder weather – no EV likes the cold – saw
the theoretical real-world range drop from around 260 miles when the ID.4 arrived to around 220 miles
after a few weeks of my custodianship. A far cry from the WLTP claim of 328 miles. [...]Challenges and Solutions
[...]
What is the ID.4 like to live with then?
Day-to-day, it’s largely been brilliant. There is something undeniably conscience-easing
about pottering about the place in an electric vehicle, especially in Cambridge, among all
the cyclists and electric scooters. I do a lot of short urban journeys ferrying the kiddo
around, and not having to fire up a combustion engine – particularly on trips so short they
never even get through the warm-up phase – has been wonderful. But that, of course, is a
plus point you can apply to almost any EV.
[...]
How difficult was it to keep charged?
[...]
Journeys outside of this routine required a little more thinking ahead. Given I figured it
best to try and avoid stopping for 40 minutes to charge while travelling with the tiny terror,
this often meant making a dedicated trip to charge the car at Cambridge Services ahead of time.
[...]
Challenges and Solutions
- Add overlaps
- End of one segment slightly overlaps with the beginning of the next
-
Knowledge Base Integration
- Reference external knowledge base with essential information
- Document-level processing
- Possible because of high token limits of new LLMs
- Resource and cost-intensive
- Pre-selecting documents based on titles, abstracts, and/or keywords
- Make document-level processing possible
- Reduce computational load
- Manual pre-processing
What About OpenAI GPTs
and Assistants?
Thank you for your attention!
Develop AI Powered Apps with OpenAI Embeddings
By Rainer Stropek




