Raíra Marotta
Estatística
Curso Big Data e Data Science
Aula 2 - Estatística Descritiva
Estatística Descritiva
- É em geral utilizada no início da análise de dados.
- Tem como objetivo tirar conclusões de forma simples através de gráficos e tabelas que representem de forma resumida uma (possivelmente) grande massa de dados.
- Exemplo: considere interesse em estudar a eficácia de uma nova escova dental infantil. Os dados obtidos em um experimento serão apresentados a seguir.
Estatística Descritiva
## No R
x.antes = c(2.18, 2.05, 1.05, 1.95, 0.28, 2.63, 1.50, 0.45, 0.70, 1.30, 1.25, 0.18, 3.30,
1.40, 0.90, 0.58, 2.50, 2.25, 1.53, 1.43, 3.48, 1.80, 1.50, 2.55, 1.30, 2.65)
x.depois = c(0.43, 0.08, 0.18, 0.78, 0.03, 0.23, 0.20, 0.00, 0.05, 0.30, 0.33, 0.00, 0.90,
0.24, 0.15, 0.10, 0.33, 0.33, 0.53, 0.43, 0.65, 0.20, 0.25, 0.15, 0.05, 0.25)
# Gráfico
par(mfrow=c(1,2), mar=c(4,4,1,0.5))
hist(x.antes,prob=1,xlab="índice de placa bacteriana",main="Histograma: antes",
xlim=c(0,4),nclass=4,col="gray50")
hist(x.depois,prob=1,xlab="índice de placa bacteriana",main="Histograma: depois",
xlim=c(0,4),nclass=4,col="gray50")
Variável: Característica do elemento investigado no estudo de interesse.

Estatística Descritiva
VARIÁVEIS QUALITATIVAS têm como possíveis realizações qualidades ou atributos do indivíduo em estudo. Exemplos: sexo, estado civil, grau de instrução, etc...
As variáveis qualitativas podem ser classificadas como:
- Nominais: não existe ordenação nas possíveis realizações da variável de interesse. Exemplos: religião, estado civil, sexo...
- Ordinais: existem ordenações nas possíveis realizações da variável de interesse. Exemplos: classe social (baixa, média, alta).
Estatística Descritiva
VARIÁVEIS QUANTITATIVAS tem como possíveis realizações os resultados de uma contagem ou mensuração.
As variáveis quantitativas podem ser classificadas como:
- Discretas: os possíveis resultados formam um conjunto finito ou infinito enumerável e que resultam, frequentemente, de uma contagem. Exemplos: número de filhos em uma família (0,1,2,...).
- Contínuas: os possíveis resultados formam um conjunto infinito não enumerável, ou seja, pertencem a um intervalo de R e resultam de uma mensuração. Exemplos: altura, peso...
Estatística Descritiva
Observações Importantes
Note que, dependendo da maneira como a variável é medida, ela pode ser classificada de formas diferentes.
Exemplo: a variável idade se medida em anos poderia ser classificada como quantitativa discreta enquanto se medimos anos e dias (2,4 anos, 3,2 anos) podemos classificá-la como quantitativa contínua.
Por que é preciso classificar as variáveis de interesse corretamente?
Porque as técnicas usadas para resumir e analisar os dados dependem do tipo de variável em estudo.

Estatística descritiva
Qual é o tipo das seguintes variáveis?
- Índice da BOVESPA
- Número de casos de dengue no Rio de Janeiro
- Regiões do Brasil
- Conceito final no curso de Estatística (A,B,C ou D)
- Prêmio de seguros
- Proporção de eleitores do Bolsonaro
- Escolaridade dos brasileiros
Análise gráfica
Quais gráficos utilizar se as variáveis forem...
- QUALITATIVAS?
2. QUANTITATIVAS?
barras, pizza (setor)
histograma, linhas, dispersão

Fonte: Censo demográfico - IBGE, 2000.

Fonte: Pnad - IBGE.
Análise gráfica no R
1. Gráfico de barras
Arquivo: "Pesquisa2008.csv".
table(pesq$Escolaridade) # retorna a tabela de frequência da variável "Escolaridade"
# do dataframe "pesq"
barplot(table(pesq$Escolaridade),ylim=c(0,20),xlab="Escolaridade",ylab="Frequência",
main="Alunos por escolaridade")2. Gráfico de pizza
pie(table(pesq$Sexo),main="Alunos por sexo")Análise gráfica no R
3. Histograma
hist(pesq$Peso,main="Distribuição dos alunos por peso (Kg)",xlab="peso (kg)",ylab="Frequência")4. Gráfico de dispersão
plot(pesq$Peso,pesq$Altura,xlab="peso(kg)",ylab="altura (m)",pch=20,
main="Peso (Kg) vs. altura (m)")5. Gráfico de linhas
ano = c(2008,2009,2010,2011,2012,2013,2014,2015,2016,2017)
roubos = c(45,32,16,19,15,31,19,32,31,43)
cel.data = data.frame(ano,roubos)
cel.data
plot(cel.data$ano,cel.data$roubos,type="l",xlab="Ano",ylab="nº roubos de celular",
main="Roubos de celular no centro do Rio \n outubro de cada ano")Medidas de Resumo
Medidas resumo são usadas para resumir ainda mais a informação vinda dos dados, fornecendo valores que representam os dados de forma global.
Medidas de Posição
Média
Mediana
Moda
Medidas de Dispersão
Variância
Desvio-padrão
Amplitude
Intervalo Interquartílico
Média Aritmética
Média aritmética simples: é a soma das observações dividida pelo número de observações

"Ponto de equilíbrio"
\bar{x}=\dfrac{\textrm{soma dos elementos}}{\textrm{número de elementos}} = \frac{\sum_{i=1}^{n}x_i}{n}
## No R:
x = c(0,2,2,3,4,1,1,1,5,6)
x.barra = mean(x)
x.barra
[1] 2.5Média Aritmética
## No R:
library(plotly)
plot_ly(alpha = 0.6) %>%
add_histogram(x = x, histnorm = "probability", showlegend= FALSE)%>%
add_lines(x=c(mean(x),mean(x)), y =c(0,0.4))%>%
add_annotations(x=mean(x), y =0.4, text= "Média")%>%
layout(bargap=0.01)
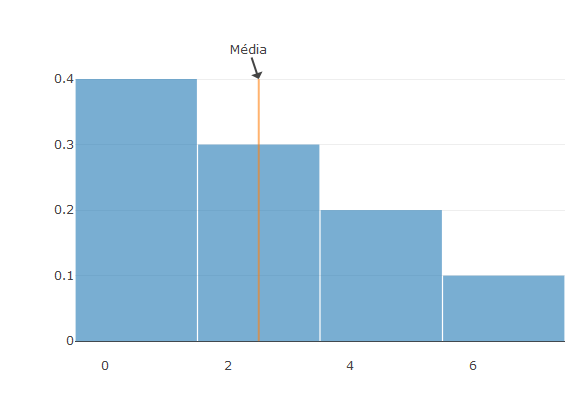
Média
Média Aritmética
Média aritmética ponderada: é a soma ponderada das observações dividida pelo número de observações.
\bar{x}=\dfrac{\textrm{soma dos elementos ponderados}}{\textrm{número de elementos}} = \frac{\sum_{i=1}^{n}f_i x_i}{n}
## No R:
x = c(21,20,25,22,24,23,90)
f = c(4,1,2,2,2,1,1)
x.barra = weighted.mean(x,f)
x.barra
[1] 27.61538Média Aritmética
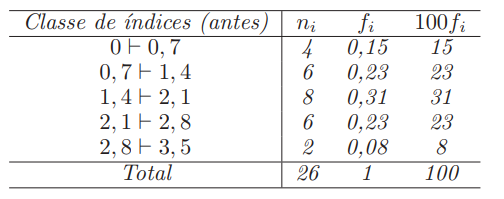
\bar{x} = \frac{(4 \times 0,35) + (6 \times 1,05) + (8 \times 1,75) + (6 \times 2,45) + (2 \times 3,15)}{26} = 1,6423
Assim,
\bar{x} = \frac{n_1p_1 + n_2p_2 + \ldots + n_kp_k}{n}
= f_1p_1 + f_2p_2 + \ldots + f_kp_k = \sum_{i=1}^{k}f_ip_i
Mediana
Mediana: Observação que ocupa a posição central nos dados ordenados em ordem crescente.
Mediana
\tilde{x}=x_{(\frac{n+1}{2})}, \textrm{se $n$ impar}
\textrm{Sejam os dados ordenados } x_{(1)} < x_{(2)} < \ldots < x_{(n)},
\tilde{x}=\dfrac{x_{(\frac{n}{2})}+x_{(\frac{n}{2}+1)}}{2}, \textrm{se $n$ par}
## No R:
aux.mediana <- sort(x)
[1] 0 1 1 1 2 2 3 4 5 6
median(aux.mediana)
[1] 2
median(x)
[1] 2Mediana
## No R:
plot_ly(alpha = 0.6) %>%
add_histogram(x = x, histnorm = "probability", showlegend= FALSE)%>%
add_lines(x=c(mean(x),mean(x)), y =c(0,0.4), showlegend= FALSE)%>%
add_lines(x=c(median(x),median(x)), y =c(0,0.4), showlegend= FALSE)%>%
add_annotations(x=mean(x), y =0.42, text= "Média")%>%
add_annotations(x=median(x), y =0.40, text= "Mediana")%>%
layout(bargap=0.01)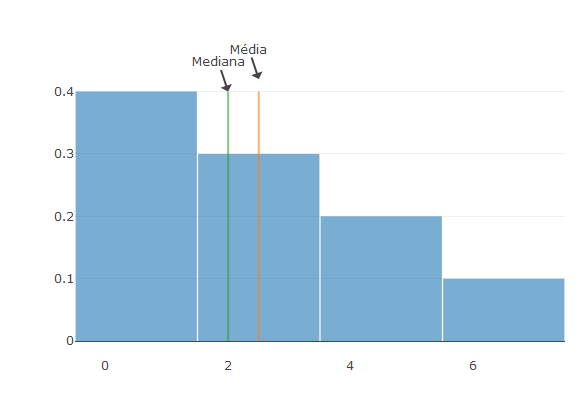
Média
Mediana
Mediana
- Qual a classe que conta com 50% + 1 observações?
Nela se encontra a mediana!!
Mediana x Média
A média é afetada por valores extremos (altos ou baixos).

Fonte: Pnad/2017 - IBGE.
Distribuição da renda domiciliar per capita por cor - Brasil 2017
Moda
Moda: realização mais frequente nos dados.

# No R
aux.moda <- unique(x)
moda <- aux.moda[which.max(tabulate(match(x, aux.moda)))]
[1] 1
library(DescTools)
mod = Mode(x)
mod
[1] 1Moda
## No R:
plot_ly(alpha = 0.6) %>%
add_histogram(x = x, histnorm = "probability", showlegend= FALSE)%>%
add_lines(x=c(mean(x),mean(x)), y =c(0,0.4), showlegend= FALSE)%>%
add_lines(x=c(median(x),median(x)), y =c(0,0.4), showlegend= FALSE)%>%
add_lines(x=c(moda,moda), y =c(0,0.4), showlegend= FALSE)%>%
add_annotations(x=mean(x), y =0.42, text= "Média")%>%
add_annotations(x=median(x), y =0.40, text= "Mediana")%>%
add_annotations(x=moda, y =0.40, text= "Moda")%>%
layout(bargap=0.01))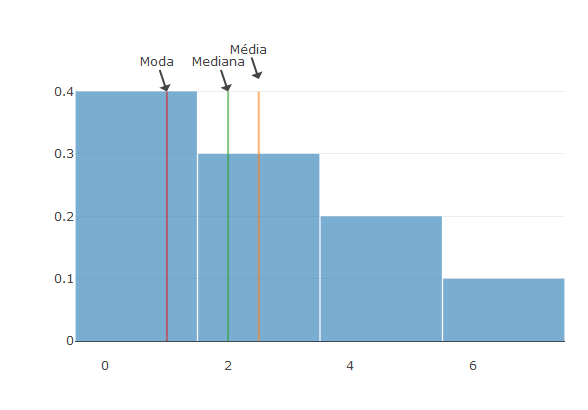
Moda
Mediana
Média
Mediana
Moda
No caso de uma variável contínua, podemos considerar o ponto médio das classes de valores para calcular a moda
Neste exemplo, a moda do índice de placa é 1,75.
Medidas de dispersão
O resumo de um conjunto de dados por uma única medida representativa de posição central esconde a informação sobre a variabilidade.
Grupo A: 3, 4, 5, 6, 7
Grupo B: 1, 3, 5, 7, 9
Grupo C: 5, 5, 5, 5, 5
Grupo D: 2, 5, 5, 7, 6
Grupo E: 4, 5, 5, 6, 5
\bar{x} = 5
Notas de grupos de alunos
Podemos dizer que os grupos têm o mesmo desempenho?

Idade de alunos de 3 turmas
Podemos dizer que as turmas são semelhantes em termos de idade?
Medidas de dispersão
Amplitude: é distância entre o mínimo e o máximo.
\Delta=\textrm{maximo}-\textrm{minimo}=x_{(n)}-x_{(1)}
## No R:
x = c(21,20,25,22,24,25,21,21,23,21,22,24,90)
amplitude = max(x)-min(x) # ou a função range(x)
amplitude
[1] 70- não consegue caracterizar a distribuição dos valores entre o mínimo e o máximo;
- é baseada em duas observações, independentemente do número total de observações.
Limitações:
Variância
Variância: considera os tamanhos dos desvios de cada observação em relação à média.
\sigma^2=\dfrac{\textrm{soma dos desvios ao quadrado}}{\textrm{número total de elementos}}=\dfrac{\sum_{i=1}^{n} (x_i-\bar{x})^2}{n}
Limitações:
- não está na mesma unidade dos dados;
- afetado por valores extremos.
Observação: é possível definir a variância usando o divisor (n-1) no lugar de (n); essa é a diferença entre os conceitos de variância amostral e variância populacional.
Variância
=
## No R:
# Medidas de dispersão ------
grupo_a <- c(3,4,5,6,7)
grupo_b <- c(1,3,5,7,9)
grupo_c <- rep(5,5)
n <- length(grupo_a)
# note que o comando var(x) usa denominador n-1, por isso é necessária uma transformação
mean(grupo_a); mean(grupo_b); mean(grupo_c)
[1] 5; [1] 5; [1] 5
var(grupo_a)*(n-1)/n; var(grupo_b)*(n-1)/n; var(grupo_c)*(n-1)/n
[1] 2; [1] 8; [1] 0
# Outra forma de fazer - desvios com relação a média
desvios_m_a <- grupo_a - mean(grupo_a)
desvios_m_b <- grupo_b - mean(grupo_b)
desvios_m_c <- grupo_c - mean(grupo_c)
var_a = mean(desvios_m_a^2)
[1] 2
var_b = mean(desvios_m_b^2)
[1] 8
var_c = mean(desvios_m_c^2)
[1] 0Variância
=
## No R: Simulando dados ---
sim_x <- rnorm(500,0,1)
sim_y <- rnorm(500,0,2)
sim_z <- rnorm(500,0,3)
plot(density(sim_z, adjust= 2), lwd = 2, ylim=c(0,.5), main = " ")
lines(density(sim_y, adjust= 2), lwd = 2, col = 2)
lines(density(sim_x, adjust= 2), lwd = 2,col = 4)
legend("topright", legend=c("Variância 1", "Variância 2", "Variância 3"), bty="n", cex = 0.8,
lwd =c(2,2,2), col=c(1,2,4))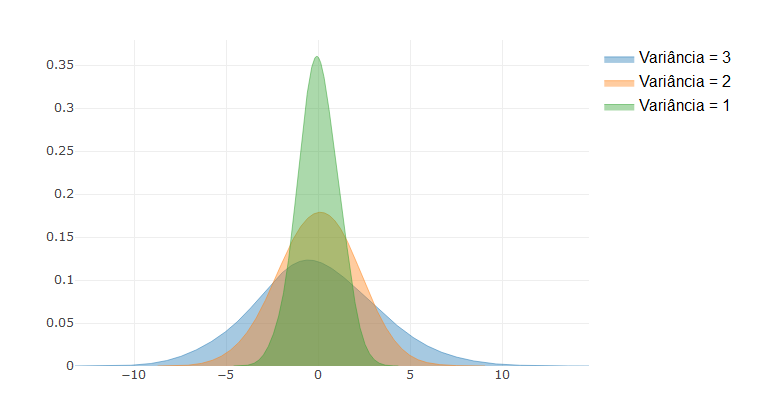
Desvio Padrão
Desvio-padrão: é a raiz quadrada da variância.
\sigma=\sqrt{\sigma^2}=\sqrt{\dfrac{\sum_{i=1}^{n} (x_i-\bar{x})^2}{n}}
## No R:
v = sd(grupo_a) # desvio-padrão amostral
v
[1] 18.81727- Uma forma de se obter uma medida de dispersão com a mesma unidade dos dados.
Coeficiente de variação
Coeficiente de variação: medida de dispersão relativa (adimensional) da variação de um conjunto de dados.
CV=\dfrac{\textrm{desvio-padrão}}{\textrm{média}}\times 100=\dfrac{\sigma}{\bar{x}} \times 100
## No R:
x = c(21,20,25,22,24,25,21,21,23,21,22,24,90)
cv = sd(x)/mean(x)*100
cv
[1] 68.14054- Expressa a variabilidade dos dados retirando a influência da ordem de grandeza da variável.
- interpretado como a variabilidade dos dados em relação à média. Quanto menor o CV mais homogêneo é o conjunto de dados.
Separatrizes
- A média e variância são medidas muito influenciadas por observações discrepantes. Por isso buscamos medidas alternativas tal como a mediana, que é mais robusta.
- Apenas com esses dois valores não temos ideia da simetria ou assimetria da distribuição dos dados.
Principais SEPARATRIZES:
- Quartis
- Decis
- Percentis
Separatrizes
x_{(1)} < x_{(2)} < \ldots < x_{(n)},
1. Quartis



2. Decis
3. Percentis
Sejam os dados ordenados
## No R:
x = c(21,20,25,22,24,25,21,21,23,21,22,24,90)
q = quantile(x,probs=c(0.05,0.1,0.5,0.75))
q
5% 10% 50% 75%
20.6 21.0 22.0 24.0Separatrizes

Fonte: Pnad/2017 - IBGE.
Distribuição da renda domiciliar per capita - Brasil 2017
Separatrizes
Considere os dados sobre os salários (em salários mínimos) de 200 funcionários de uma grande empresa de marketing.
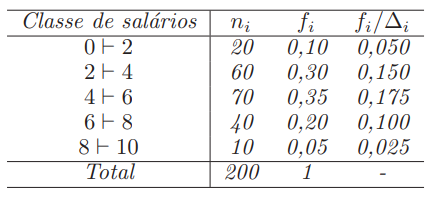
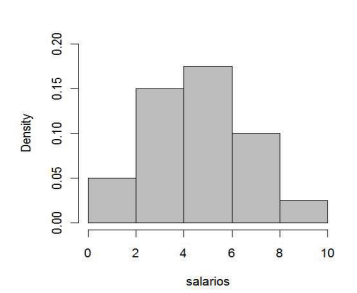
As duas primeiras classes acumulam 40% dos salários. Faltam 10% para termos 50% (que irá corresponder a mediana). Então fazemos:
\frac{6-4}{0,35} = \frac{med(x) - 4}{0,10}
Resultando em med(x) = 4, 57 é a mediana dos salários.
Suponha que a empresa de marketing está em crise e decidiu demitir os funcionário que ganham os 20% salários mais altos. Qual valor de salário deve ser usado para demitir um funcionário?
As três primeiras classes acumulam 75% dos salários. Faltam 5% para termos 80% (que irá corresponder a 20% a partir desse valor). Então fazemos:
Resultando em q(0, 80) = 6, 5. Então se um funcionário recebe mais que 6,5 salários mínimos será demitido de acordo com essa regra.
\frac{8-6}{0,20} = \frac{q(0,80) - 6}{0,05}
Separatrizes
Alguns nomes particulares são usados para alguns quantis mais usados:
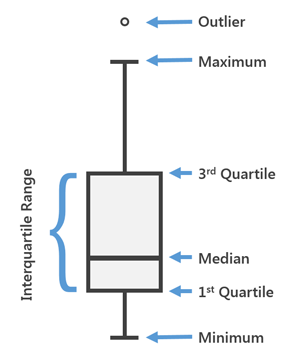
Separatrizes
Desvio Interquartílico
Máximo
Mínimo
Mediana
Outlier
3º Quartil
1º Quartil
- q1 = q(0, 25): primeiro quartil;
- q2 = q(0, 50): mediana;
- q3 = q(0, 75): terceiro quartil;
Assimetria

Moda
Média
Médiana
Moda
Moda
Média
Média
Médiana
Médiana
Assimetria positiva
Assimetria negativa
Distribuição simétrica
Infnet - Aula 2
By Raíra Marotta



