Resiliency in
Distributed Systems
Follow along,
- 18 Products
- 1m+ Drivers
- 300+ Microservices
- 15k+ Cores
- 2 Cloud Providers
- 6 Data centers
- 100+ million bookings per month
Transport, logistics, hyperlocal delivery and payments
Agenda
- Resiliency and Distributed Systems
- Why care for Resiliency ?
- Faults vs Failures
- Patterns for Resiliency
Distributed Systems
Networked Components which communicate and coordinate their actions by passing messages
Troll Definition

Resiliency
Capacity to Recover from difficulties
Why care about Resiliency ?
- Financial Losses
- Losing Customers
- Affecting Customers
- Affecting Livelihood of Drivers
Faults vs Failures
Fault
Incorrect internal state in your system
Faults
- Database slowdown
- Memory leaks
- Blocked threads
- Dependency failure
- Bad Data
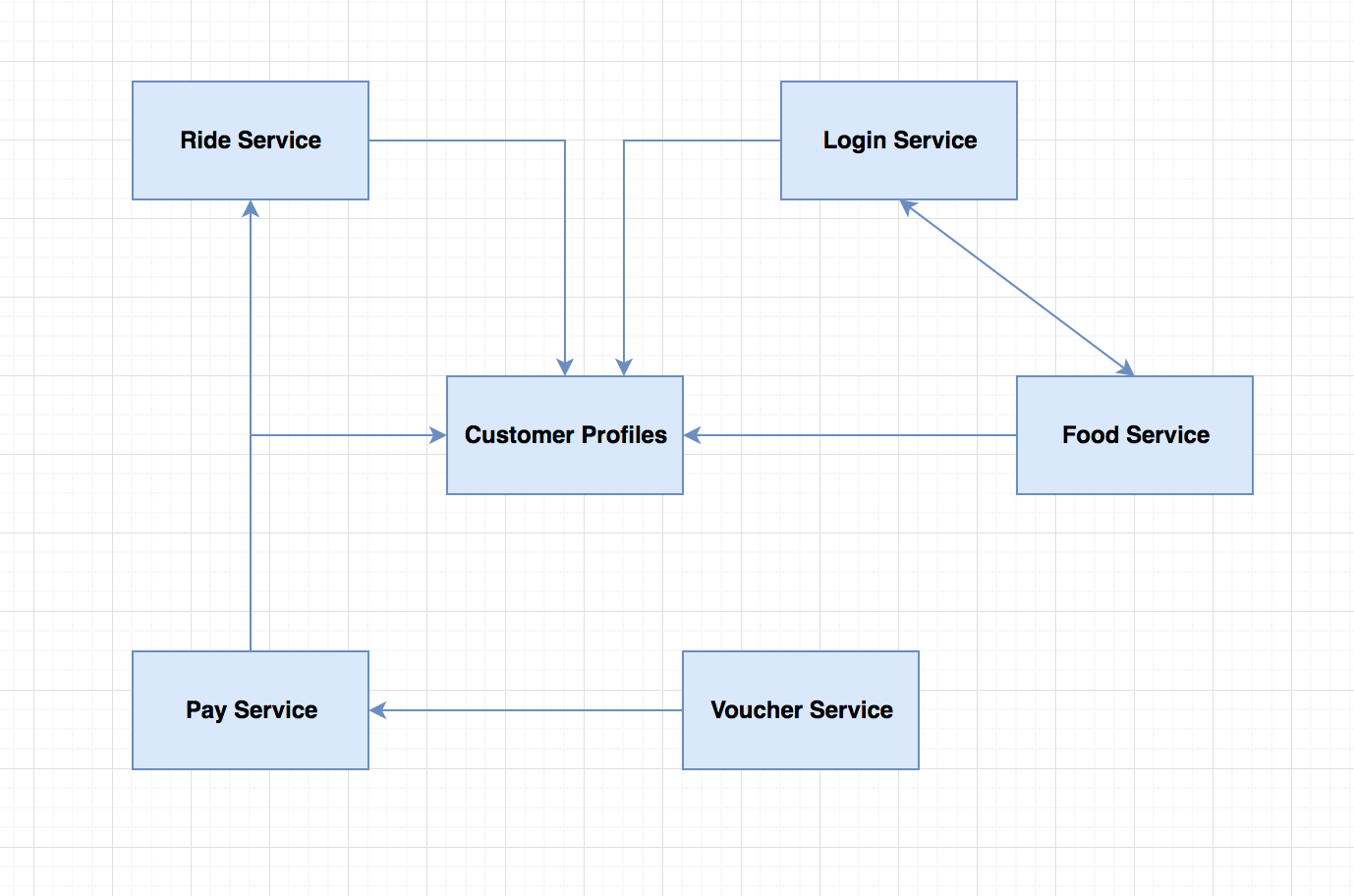
Healthy
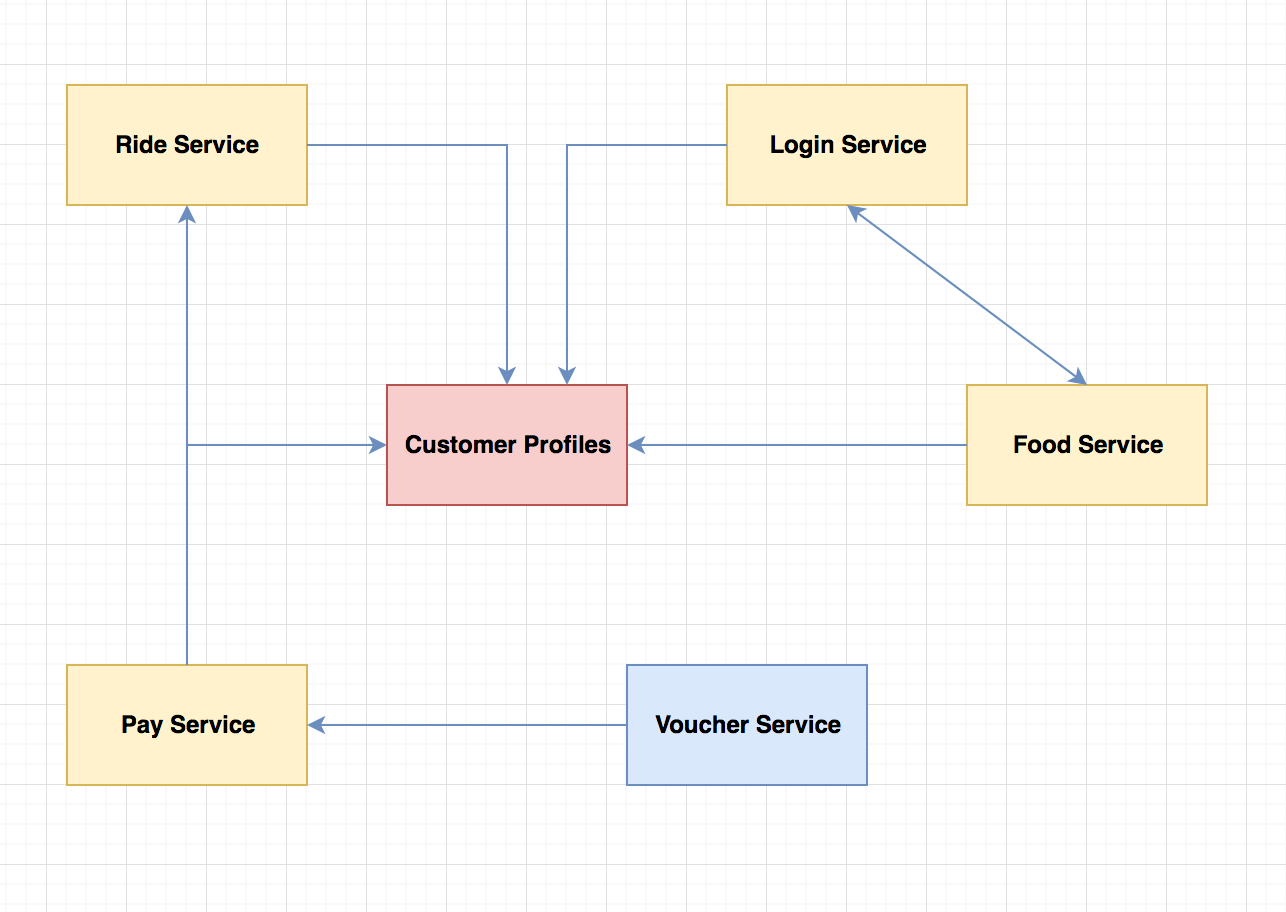
Faults
Failure
Inability of the system to do its intended job
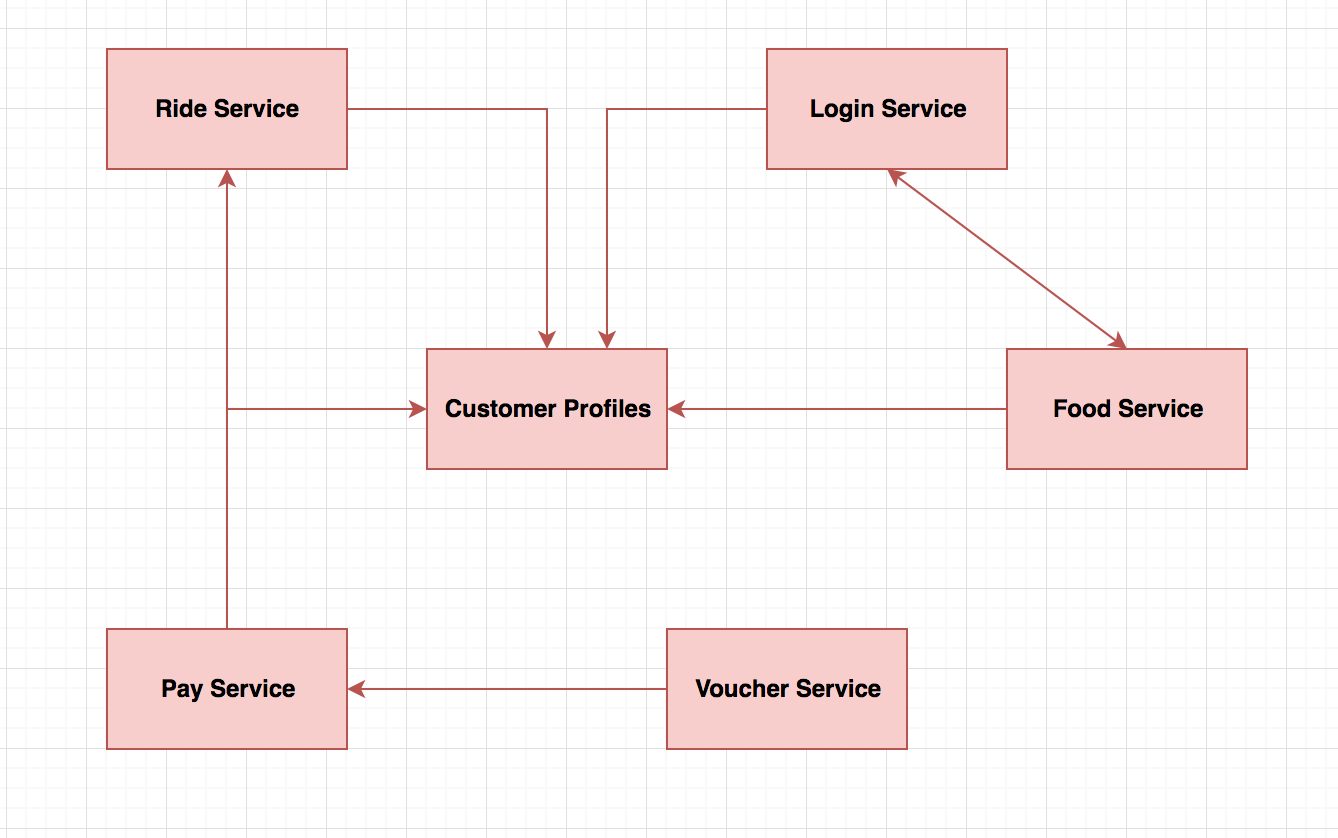
Failures
Resiliency is about preventing faults turning into failures
Resiliency in Distributed Systems is Hard
- Network is unreliable
- Dependencies can always fail
- Users are unpredicatable
Patterns for Resiliency
Heimdall
https://github.com/gojektech/heimdall

#NOCODE
Resiliency Pattern #0
#LessCode
Timeouts
Stop waiting for an answer
Resiliency Pattern #1
Required at Integration Points
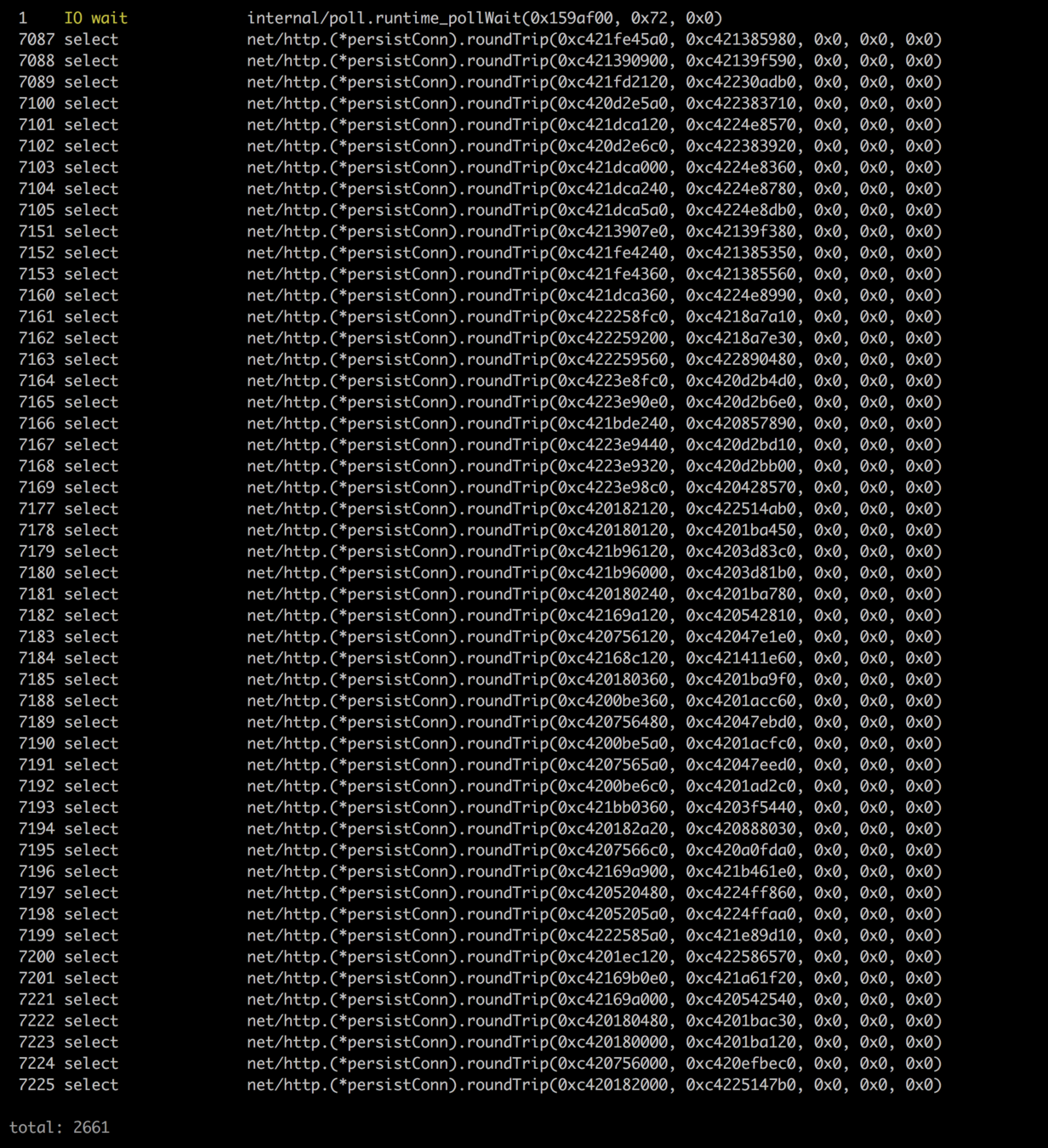
DefaultHTTPClient Waits forever
httpClient := http.Client{}
_, err := httpClient.Get("https://gojek.com/drivers")
Goroutines
httpClient := heimdall.NewHTTPClient(1 * time.Millisecond)
_, err := httpClient.Get("https://gojek.com/drivers",
http.Header{})
Prevents Cascading Failures
Provides Failure Isolation
Timeouts must be based on dependency's SLA
Retries
Try again on Failure
Resiliency Pattern #2
Reduces Recovery time
backoff := heimdall.NewConstantBackoff(500)
retrier := heimdall.NewRetrier(backoff)
httpClient := heimdall.NewHTTPClient(1 * time.Millisecond)
httpClient.SetRetrier(retrier)
httpClient.SetRetryCount(3)
httpClient.Get("https://gojek.com/drivers", http.Header{})Retrying immediately may not be useful
Queue and Retry wherever possible
Idempotency is important
Circuit Breakers
Stop making calls to save systems
Resiliency Pattern #3
State Transitions
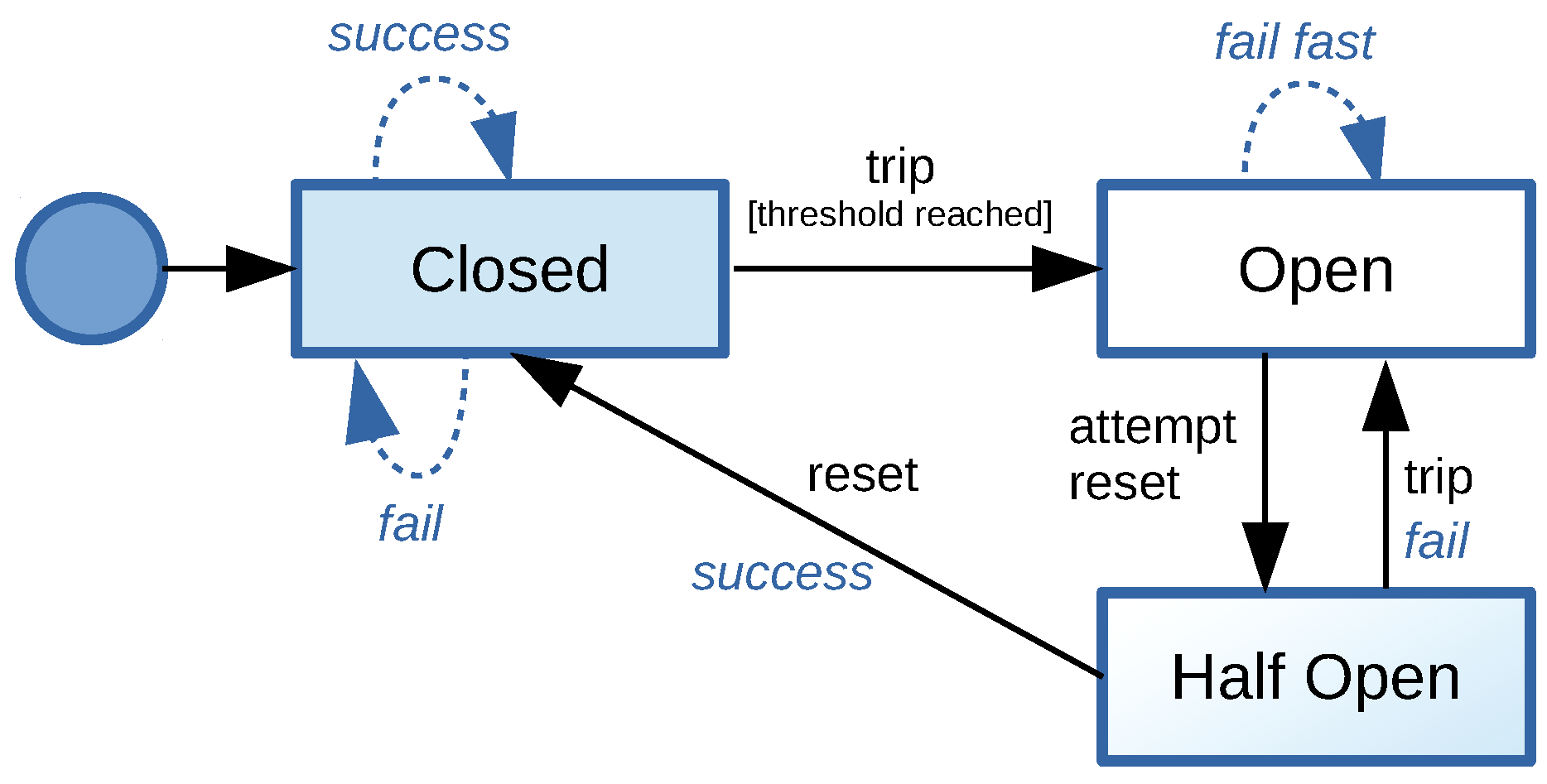
Hystrix
config := heimdall.HystrixCommandConfig{
MaxConcurrentRequests: 100,
ErrorPercentThreshold: 25,
SleepWindow: 10,
RequestVolumeThreshold: 10,
}
hystrixConfig := heimdall.NewHystrixConfig("MyCommand",
config)
timeout := 10 * time.Millisecond
httpClient := heimdall.NewHystrixHTTPClient(timeout,
hystrixConfig)
_, err := httpClient.Get("https://gojek.com/drivers",
http.Header{})
Circumvent calls when system is unhealthy
Guards Integration Points
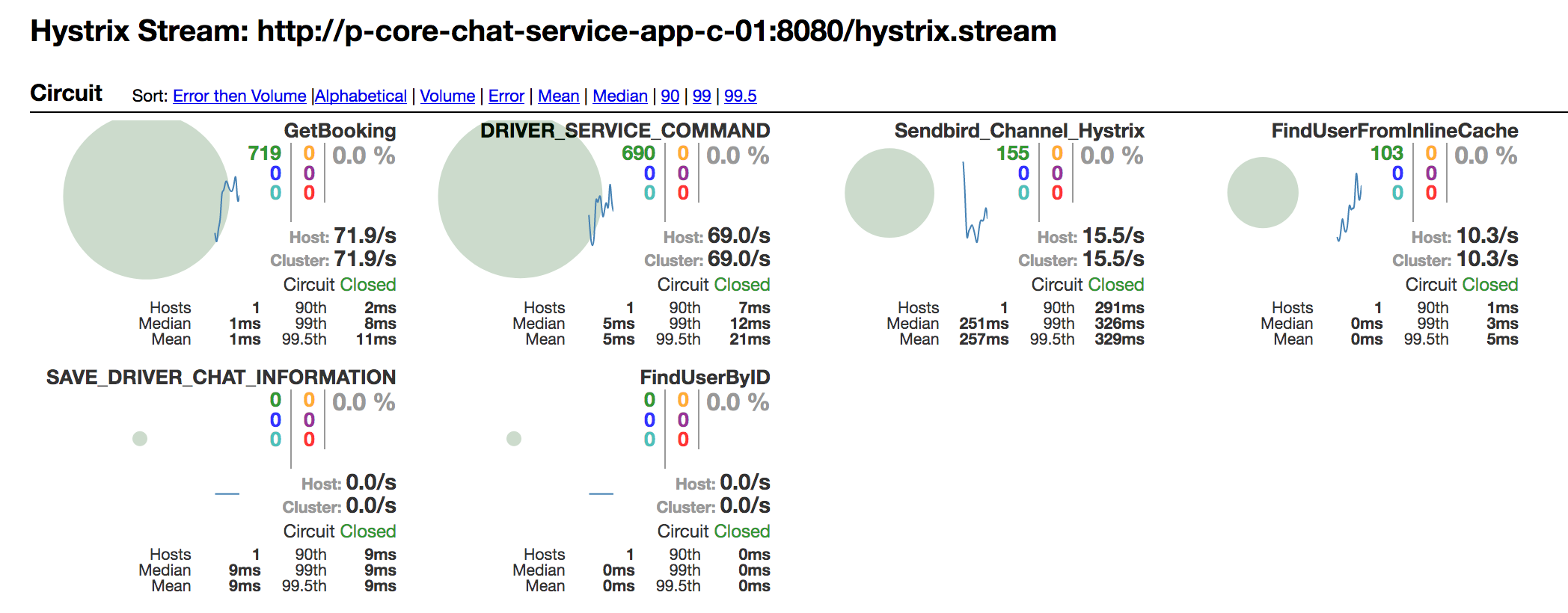
Metrics/Monitoring
Hystrix Dashboards
Fallbacks
Degrade Gracefully
Resiliency Pattern #4
Curious case of Maps Service
Route Distance
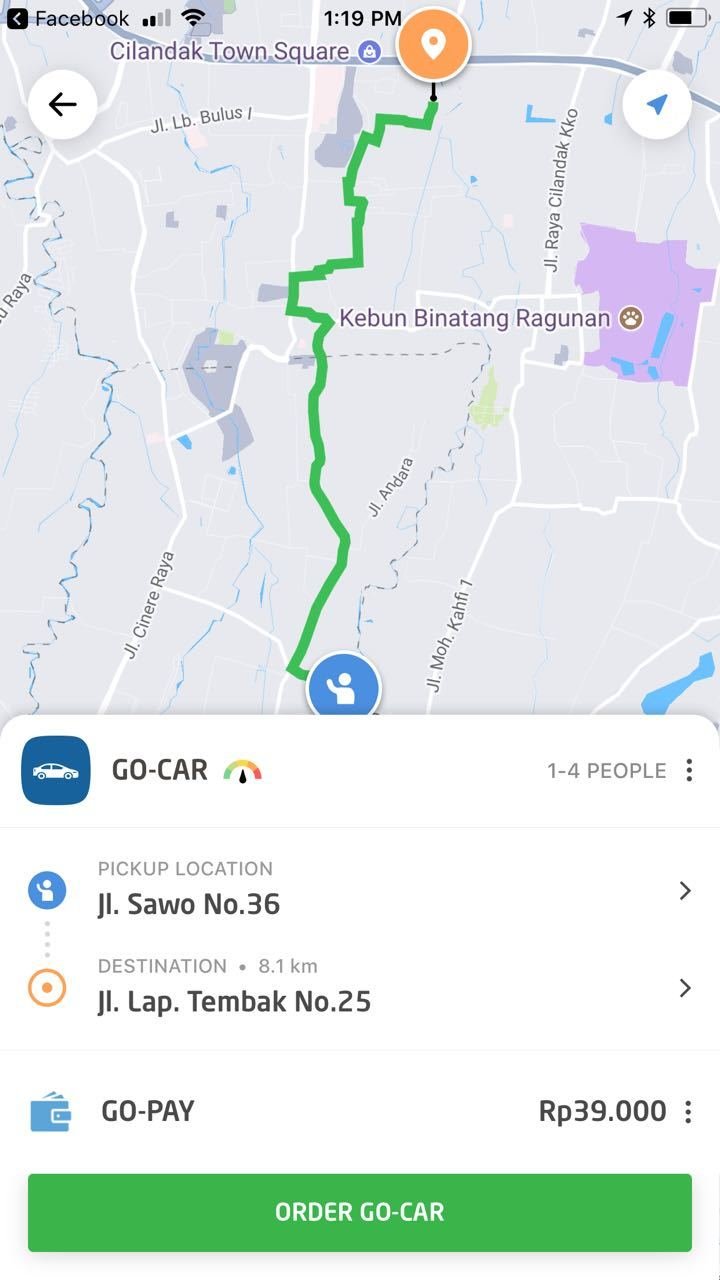
Fallback from Route Distance to Route Approximation
Route Approximation
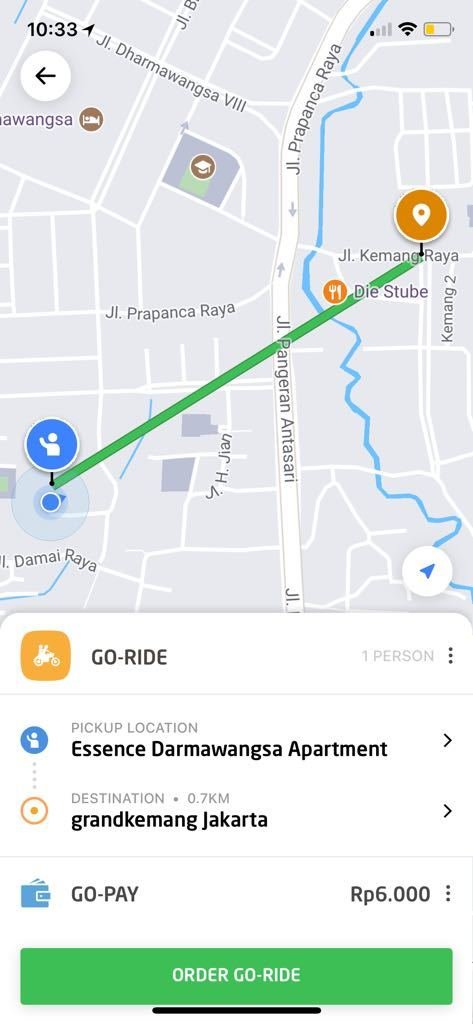
Fallback to a Different Maps Provider
Helps Degrade gracefully
Protect Critical flows from Failure (Ex: Booking Flow)
Think of fallbacks at Integration points
Resiliency Testing
Resiliency Pattern #5
Test and Break
Find Failure modes
Create a Test Harness to break callers
Inject Failures
Unknown Unknowns
Simian Army
- Chaos Monkey
- Janitor Monkey
- Conformity Monkey
- Latency Monkey
More patterns
- Rate-limit/Throttling
- Bulk-heading
- Queuing
- Monitoring/alerting
- Canary releases
- Redundancies
In Conclusion ...
Patterns are no silver bullet
Systems Fail, Deal with it
Design Your Systems for Failure
Recap
- Faults vs Failures
- Timeouts
- Retries
- Circuit Breakers
- Fallbacks
- Resiliency Testing
War Stories
Come meet us ...

References
Questions ?
Resiliency in Distributed Systems
By Rajeev Bharshetty




