Feeding locusts at
🦗 1K QPS 🦗
per restaurant
(while serving quality food)
Guillaume Gelin
ramnes.eu 🇪🇺 🇫🇷



😊
08:30 AM
Bob wakes up.
09:00 AM
Bob arrives at his restaurant.
He is the one taking orders.
10:00 AM
The first client comes in!
11:00 AM
A queue starts.
11:30 AM
Locusts are hungry early.
🙂🖥️🦗🦗 😅🖥️🦗🦗 🙂🖥️🦗🦗 🙂🖥️🦗🦗
12:00 AM
Coworkers arrive! Fiuh.
12:30 AM
Queues are full: global panic!
😱🖥️🦗🦗🦗🦗🦗🦗🦗🦗
😭🖥️🦗🦗🦗🦗🦗🦗🦗🦗
😱🖥️🦗🦗🦗🦗🦗🦗🦗🦗
😱🖥️🦗🦗🦗🦗🦗🦗🦗🦗
12:35 AM
Crisis meeting
🤔
🤔 🤔
🤔
12:40 AM
Bob has an idea...
🤔
😀 🤔
🤔
12:41 AM
What if we used robots?
😀🤖
😎🤖🦗🦗
😍🤖🦗🦗
😎🤖🦗🦗
😎🤖🦗🦗
🦗🦗
🦗🦗
🦗🦗
🦗🦗
🦗🦗
🦗🦗
🦗🦗
🦗🦗
🦗🦗
🦗🦗
🦗🦗
🦗🦗
12:45 AM
Locusts are served much faster,
the queue starts to disappear
13:00 AM
But wait, no!
More and more locusts are coming in...
😱🤖🦗🦗🦗🦗🦗🦗🦗🦗
😭🤖🦗🦗🦗🦗🦗🦗🦗🦗
😱🤖🦗🦗🦗🦗🦗🦗🦗🦗
😱🤖🦗🦗🦗🦗🦗🦗🦗🦗

Scaling Python to
1K QPS
per server
(not doing Hello Worlds)
Quick summary
🦗 = ? 💺🖥️ = ? 😊 = ? 🤖 = ?
It's simple until you
make it complicated.
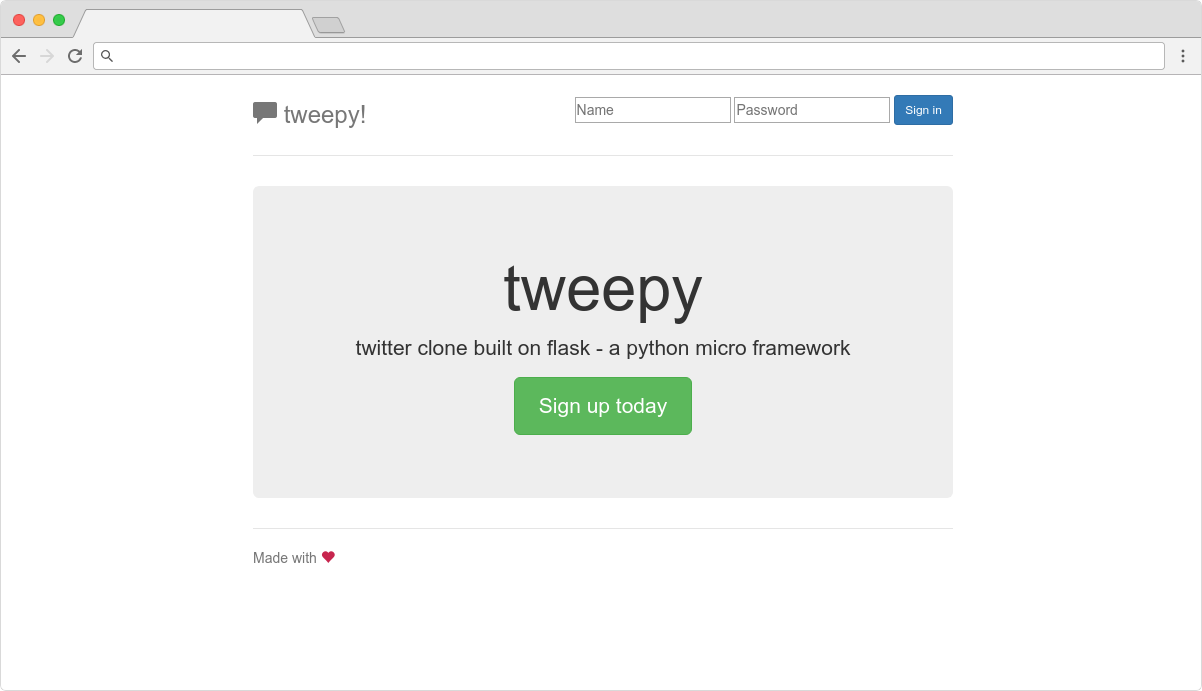
Step 0
Have something to scale
Have something to scale
😊
-
4 CPU - 16 GB
-
Nginx :80 → :5000
-
Flask
-
SQLite
-
Flask-SQLAlchemy
-
Flask-WTF
-
Flask-Bcrypt
-
Register
-
Log in and log out
-
List tweets
-
Write new tweets
-
List all users
-
Follow and unfollow
Step 1
Identify threats and
define a protocol
Indentify threats
Reads
List tweets
List all users
Writes
-
Register
-
Log in and log out
-
Write new tweets
-
Follow and unfollow
Reads
-
List tweets
-
List all users
Writes
-
Register
-
Log in and log out
-
Write new tweets
-
Follow and unfollow
Define a protocol
-
Only one server (no horizontal scaling allowed)
-
Response time's 95% percentile should stay under 2 seconds
-
Failure rate should stay at 0%
-
Register 1x
-
Log in and log out 2x
-
List tweets 200x
-
Write new tweets 20x
-
List all users 5x
-
Follow and unfollow 5x
$ python run.py50 QPS
Step 2
Parallelize


$ uwsgi --http :5000 --processes 4 --file run.py --callable app$ gunicorn --bind :5000 --workers 4 run:app$ cat tweepy.ini
[uwsgi]
master = true
protocol = http
socket = 0.0.0.0:5000
file = run.py
callable = app
processes = 4
$ uwsgi tweepy.ini180 QPS
Stateful versus stateless
Step 3
Check the database usage
Leverage RAM
Paging is hard
but necessary
Explain
Transaction logs
250 QPS
Step 4
Cache reads
There are only two hard things in computer science: cache invalidation
and naming things.
tweets_cache = {}
@app.route("/tweets", methods=["GET"])
def get_tweets():
...
tweets = tweets_cache.get(user_id)
if not tweets:
tweets = query_tweets(...)
tweets_cache[user_id] = tweets
...
@app.route("/tweets", methods=["POST"])
def post_tweets():
...
tweet.save()
tweets_cache.pop(user_id)
...
@cache()
def query_tweets(user_id, ...):
...
@app.route("/tweets", methods=["GET"])
def get_tweets():
...
query_tweets(user_id, ...)
...
@app.route("/tweets", methods=["POST"])
def post_tweets():
...
query_tweets.invalidate(user_id)
...
But, the application is stateful now?

350 QPS
Step 5
Achieve concurrency

In the future:
asyncio + ASGI




CPU versus I/O
Databases writes
550 QPS
Step 6
???
😱🤖🦗🦗🦗🦗🦗🦗🦗🦗
😭🤖🦗🦗🦗🦗🦗🦗🦗🦗
😱🤖🦗🦗🦗🦗🦗🦗🦗🦗
😱🤖🦗🦗🦗🦗🦗🦗🦗🦗
Step 6
Scale vertically!
😎🤖🦗🦗 😎🤖🦗🦗 😎🤖🦗🦗 😎🤖🦗🦗 😎🤖🦗🦗 😎🤖🦗🦗 😎🤖🦗🦗 😎🤖🦗🦗
🦗🦗
🦗🦗
🦗🦗
🦗🦗🦗🦗
🦗🦗
🦗🦗
🦗🦗
🦗🦗
🦗🦗
🦗🦗
🦗🦗🦗🦗
🦗🦗
🦗🦗
🦗🦗
🦗🦗
🦗🦗
🦗🦗
🦗🦗🦗🦗
🦗🦗
🦗🦗
🦗🦗
1K QPS
But remember...
Thank you!
Scaling Python to 1K QPS per server, not doing Hello Worlds
By Guillaume Gelin
Scaling Python to 1K QPS per server, not doing Hello Worlds
I will present a sample web application inspired from the real world (so not an application doing hello worlds) and showcase several ways of scaling it up, layer after layer, doing benchmarks at every step, up to 1000 queries per second — or 86.4 millions per day — on one Amazon server.

