
I Believe I can flaP
Raúl G. Roa Gómez
How to play Flappy Bird and never* lose

Disclaimer
Who's this guy
Lead Software Architect
WE MAKE COMPUTERS DO AMAZING THINGS...
PUT STUFF WHERE THEY BELONG

MAKE THEM UNDERSTAND

I DO MORE
Business & Technical Consultant at ITSS GLOBAL
Banking technology solutions and services to banks and financial institutions
Technical Adviser & Business partner at Digital Reality
Virtual Reality and augmented reality for developing countries.
Technical Adviser at Yoyo
Payment gateway for unbanked individuals
Minor OSS contributor
DevIL, ResIL, fog, emscripten
A LITTLE BIT MORE...
Full Stack Developer (10+ years)
C/C++, Python, Rust, MCP, MCAD and MCSD
2D/3D Game Developer (5+ years)
C/C++, UnrealScript, Lua, GLSL, HLSL, Unreal Engine, Unity
Adjunct Lecturer PUCMM (RSTA, STI) (7 years)
Software Engineering, Programming, Data Structures
DCGames (2003 ― 2005)
Game performance metrics for CS 1.6, Unreal Tournament, Quake 3 and Warcraft: Frozen Throne. Biggest video game related site in the Caribbean. Subsequently acquired by Verizon in 2005.
what's this talk about?
INTELLIGENCE
/ꞮNˈTƐLꞮDƷ(Ə)NS/
THE ABILITY TO ACQUIRE AND APPLY KNOWLEDGE AND SKILLS.
COMPUTERS
+
INTELLIGENCE
=
ARTIFICIAL INTELLIGENCE
WE ARE ADDING MORE COWBELL

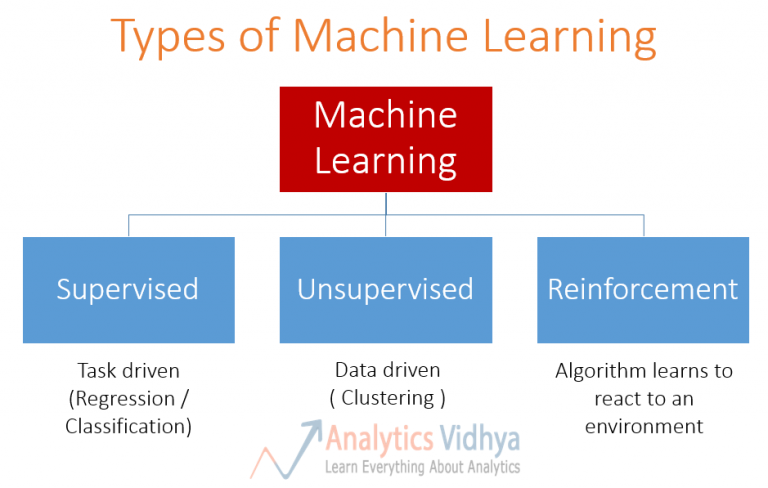
MACHINE LEARNING
machine-learning (ML) is one IMPLEMENTATION of Artificial Intelligence (A.I.), It is a statistical and data-driven approach to creating A.I.
WE WILL DEMONSTRATE THE LATER, BY ANSWERING ONE IMPORTANT QUESTION
to flap
or
to not flap?

But how?
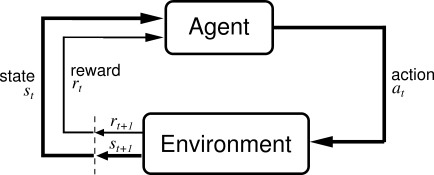
REINFORCEMENT LEARNING
is an area of machine learning inspired by behaviorist psychology, concerned with how software agents ought to take actions in an environment so as to maximize some notion of cumulative reward.
van Otterlo, M.; Wiering, M. (2012)
REINFORCEMENT LEARNING

REINFORCEMENT LEARNING
Specifically...
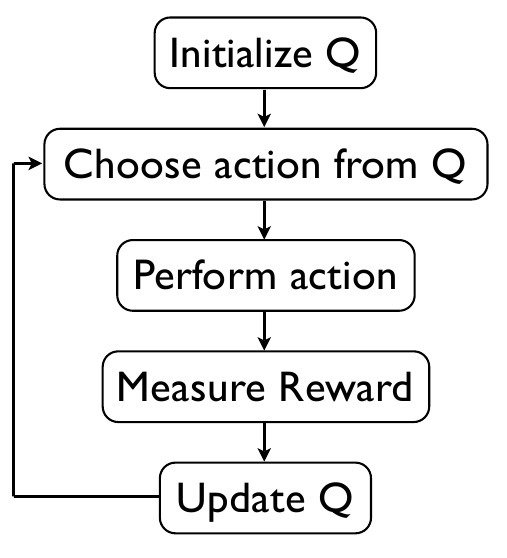
Q-LEARNING
a technique that evaluates which action to take based on an action-value function that determines the value of being in a certain state and taking a certain action in that state.

Q-LEARNING

http://mnemstudio.org/path-finding-q-learning-tutorial.htm

http://mnemstudio.org/path-finding-q-learning-tutorial.htm
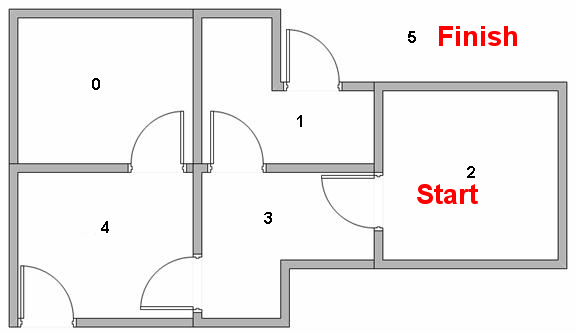
http://mnemstudio.org/path-finding-q-learning-tutorial.htm
http://mnemstudio.org/path-finding-q-learning-tutorial.htm
http://mnemstudio.org/path-finding-q-learning-tutorial.htm
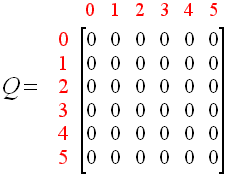
http://mnemstudio.org/path-finding-q-learning-tutorial.htm
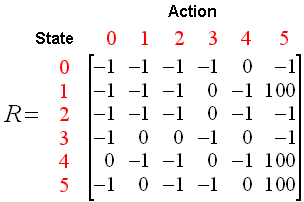
Q-LEARNING
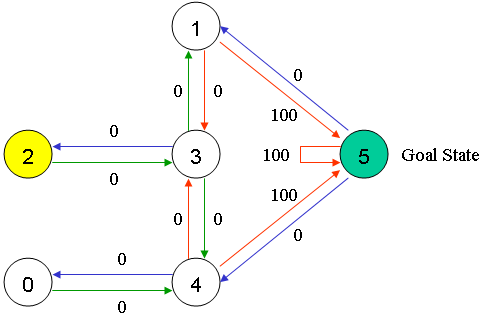
Q(1, 5)
Q(1, 5) =
R(1, 5) + 0.8 * Max[Q(5, 1), Q(5, 4), Q(5, 5)] = 100 + 0.8 * 0 = 100
http://mnemstudio.org/path-finding-q-learning-tutorial.htm

http://mnemstudio.org/path-finding-q-learning-tutorial.htm
Q(1, 5)

http://mnemstudio.org/path-finding-q-learning-tutorial.htm
RINSE AND REPEAT
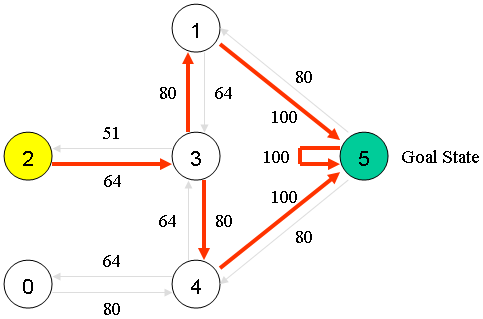
http://mnemstudio.org/path-finding-q-learning-tutorial.htm
UPDATED Q-MATRIX
eeeeeeeeh?

Please show me something!

- Asynchronous Methods for Deep Reinforcement Learning
https://goo.gl/v6QWNY
- What’s the Difference Between Artificial Intelligence, Machine Learning, and Deep Learning?
https://goo.gl/3H6vss
FURTHER READING
I believe I can flap
By Raúl G. Roa Gómez




