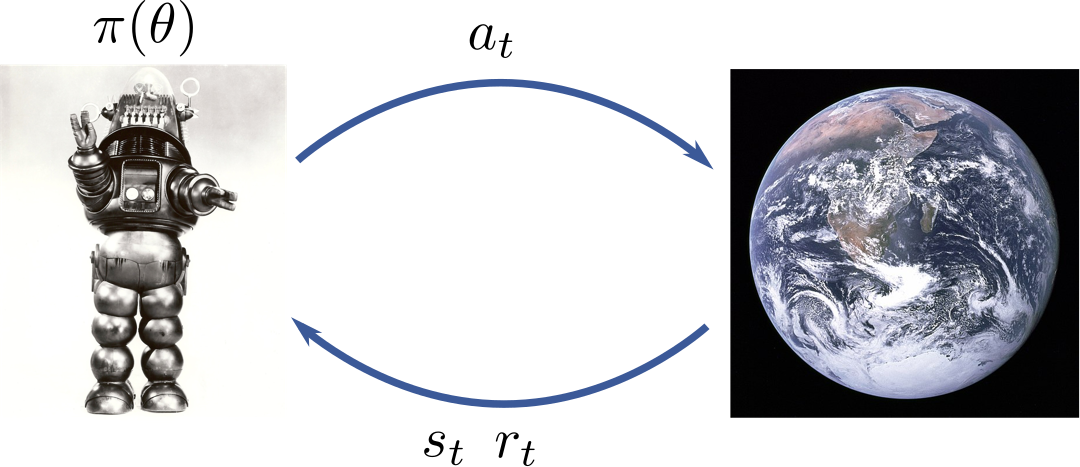
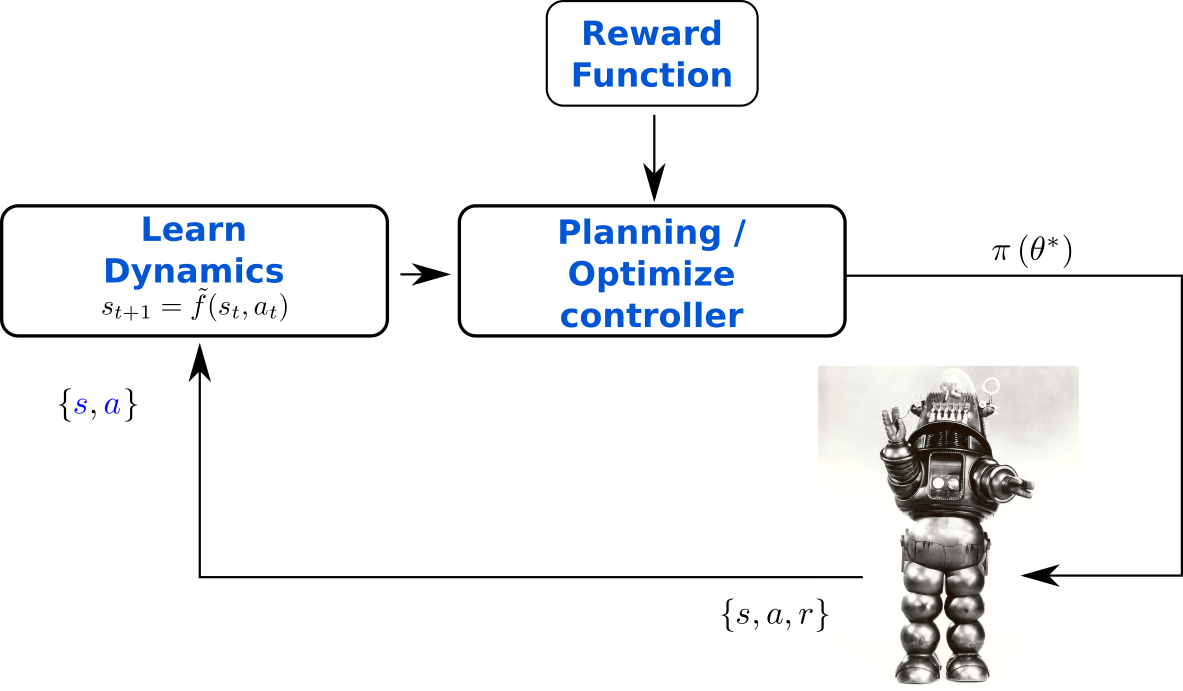







































Roberto Calandra PRO
Full Professor at TU Dresden. Head of the LASR Lab. Working in AI, Robotics and Touch Sensing.
Roberto Calandra
Facebook AI Research
UC Berkeley - 23 October 2019
Local convergence guaranteed*
Simple to implement
Computationally light
Does not generalize
Data-inefficient
No convergence guarantees
Challenging to learn model
Computationally intensive
Data-efficient
Generalize to new tasks
Evidence from neuroscience that humans use both approaches! [Daw et al. 2010]
Chua, K.; Calandra, R.; McAllister, R. & Levine, S.
Deep Reinforcement Learning in a Handful of Trials using Probabilistic Dynamics Models
Advances in Neural Information Processing Systems (NIPS), 2018, 4754-4765
Bansal, S.; Calandra, R.; Xiao, T.; Levine, S. & Tomlin, C. J.
Goal-Driven Dynamics Learning via Bayesian Optimization
IEEE Conference on Decision and Control (CDC), 2017, 5168-5173
There exist models that are wrong, but nearly optimal when used for control
- George E.P. Box
- Roberto Calandra
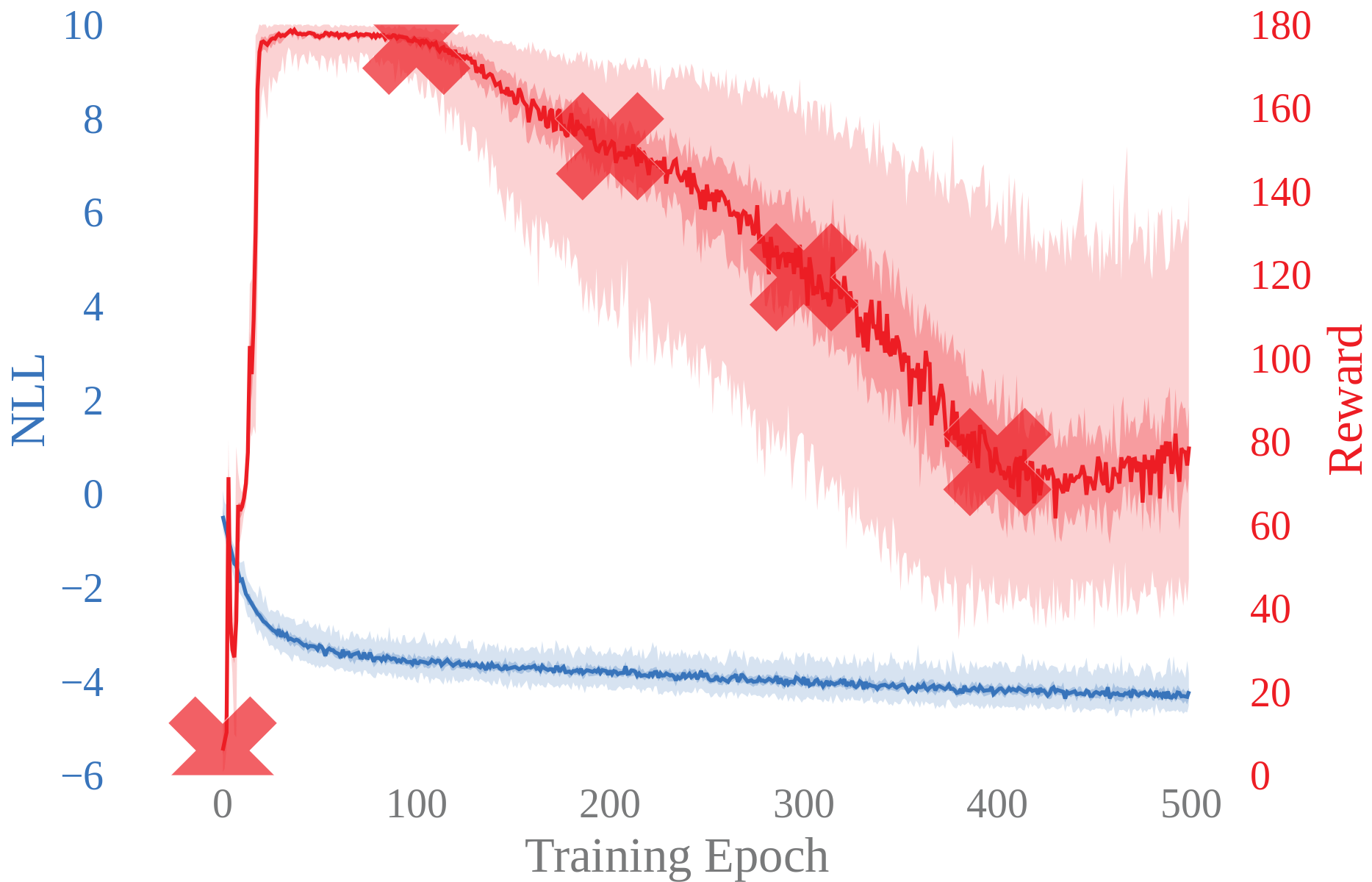
Objective mismatch arises when one objective is optimized in the hope that a second, often uncorrelated, metric will also be optimized.
Negative Log-Likelihood
Task Reward
Deterministic model
Probabilistic model
Historical assumption ported from System Identification
Assumption: Optimizing the likelihood will optimize the reward
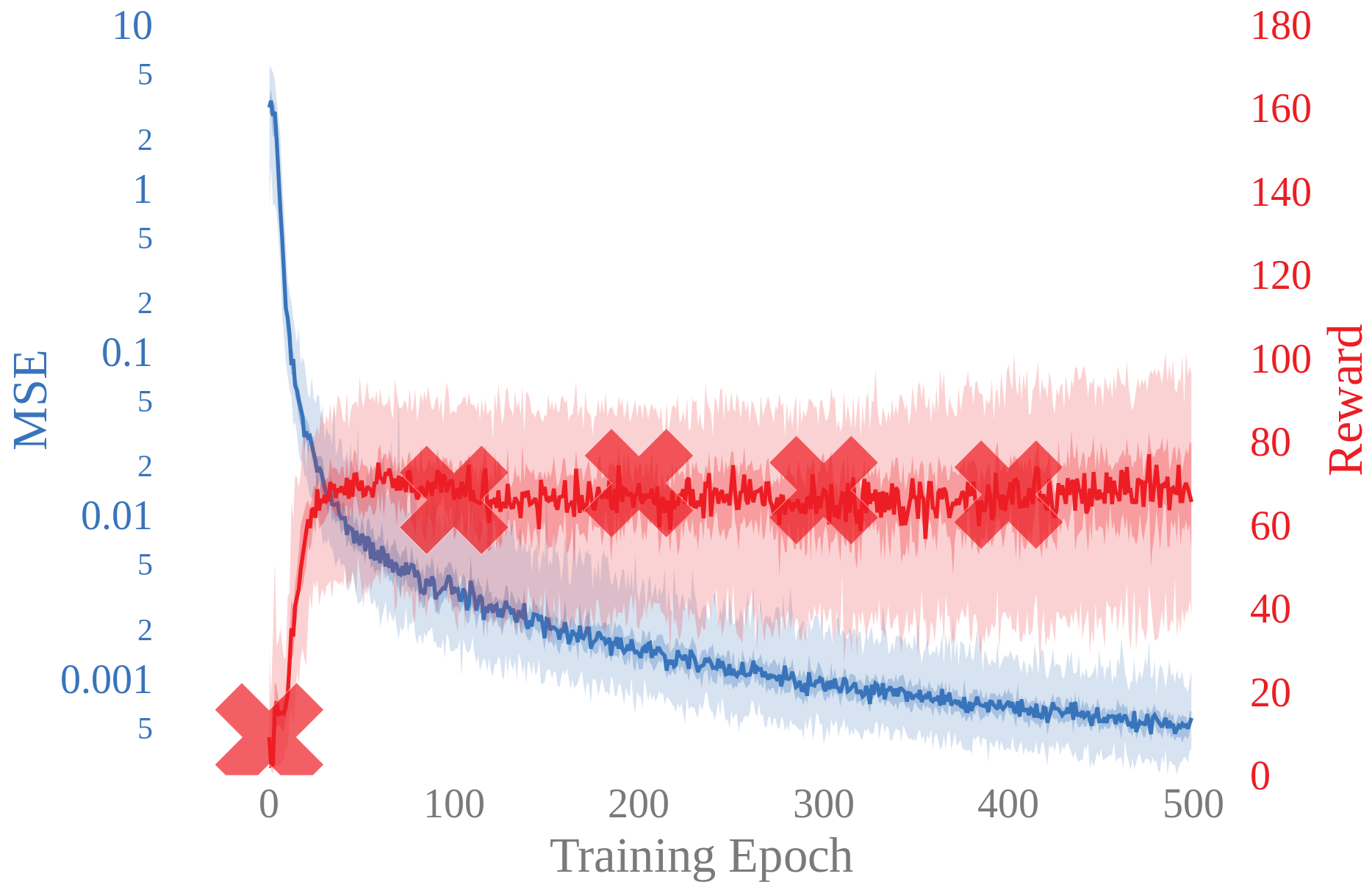
Experimental results show that the likelihood of the trained models are not strongly correlated with task performance
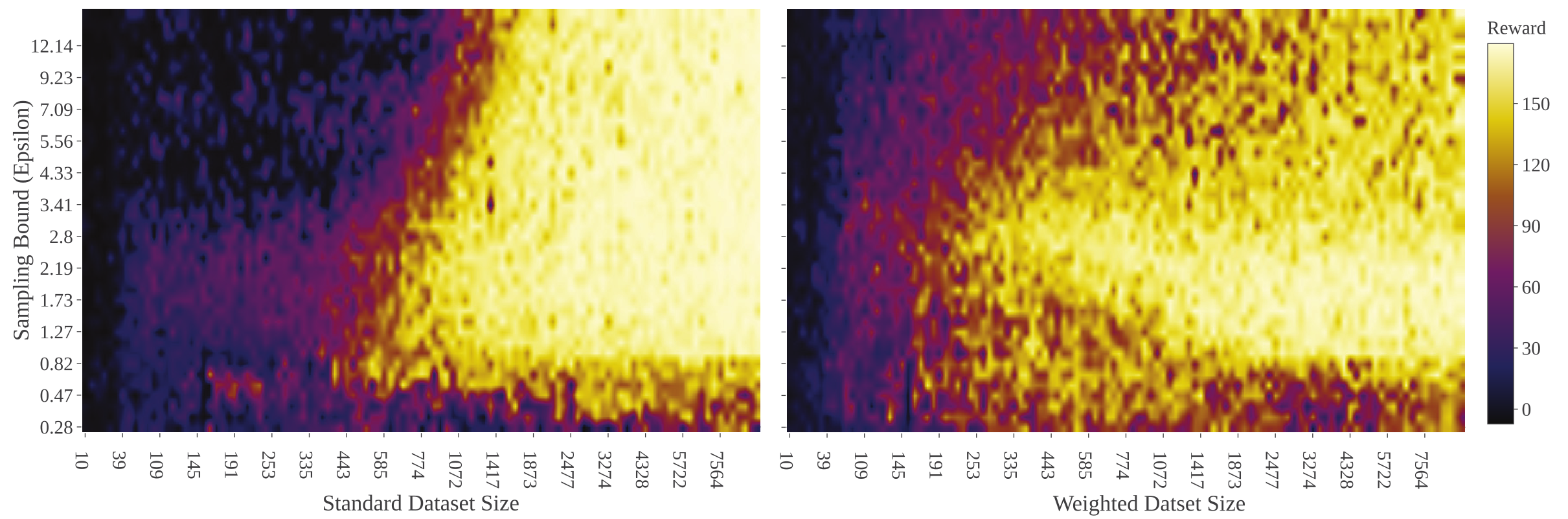
How can we give more importance to data that are important for the specific task at hand?
Our attempt: re-weight data w.r.t. distance from optimal trajectory
Introduced and analyzed Objective Mismatch in MBRL
Lambert, N.; Amos, B.; Yadan, O. & Calandra, R.
Objective Mismatch in Model-based Reinforcement Learning
Under review, Soon on Arxiv, 2019
If you are interested in collaborating, ping me
Bansal, S.; Calandra, R.; Xiao, T.; Levine, S. & Tomlin, C. J.
Goal-Driven Dynamics Learning via Bayesian Optimization
IEEE Conference on Decision and Control (CDC), 2017, 5168-5173
Objective Mismatch in Model-based Reinforcement Learning
Under review, Soon on Arxiv, 2019
How to scale to more complex, unstructured domains?
Robotics
Lambert, N.O.; Drew, D.S.; Yaconelli, J; Calandra, R.; Levine, S.; & Pister, K.S.J.
Low Level Control of a Quadrotor with Deep Model-Based Reinforcement Learning
IEEE Robotics and Automation Letters (RA-L), 2019, 4, 4224-4230
By Roberto Calandra
[Berkeley]



