Data management for LIBRA
🎯Goal: to improve long-term reproducibility of the LIBRA project results
Statement of need:
Typical LIBRA workflow
LSC
Activation Foils
Neutronics model
Tritium model
Diamond detector data
Experimental TBR
Modelled TBR
Mass transport coeff.
Aggreement?
Exp. data
Total T production
Total n production
Models
Statement of need:
we produce a lot of data!
For each run, we produce:
- Run info (timings, date, log...)
- LSC data (tritium)
- Activation foil data (neutron)
- Diamond detector (neutron)
- Tritium model
- Neutronics model(s)
In the future we may also produce:
- OpenFOAM models
- FESTIM models
- Temperature measurements
- New neutron detection data
- Gas system data (flow rates, pressures...)
Statement of need:
it is getting harder and harder to manage data
Raw activation foils counts
no idea where to find them 🤷
Irradiation logs from prev. runs

Sample timings



Now on Google Drive
Now using csv
Raw LSC data

Statement of need:
it is getting harder and harder to manage data


Neutronics models
Scattered across different repos, some are not even under version control
Tritium models
All in calculations repo but hard coded TBRs and foil data
# from OpenMC
calculated_TBR = 1.9e-3 * ureg.particle * ureg.neutron**-1Proposed solution:
Gather everything in one repository per run
Collected raw exp. data


Code, models & analysis (OpenMC script, tritium model...)
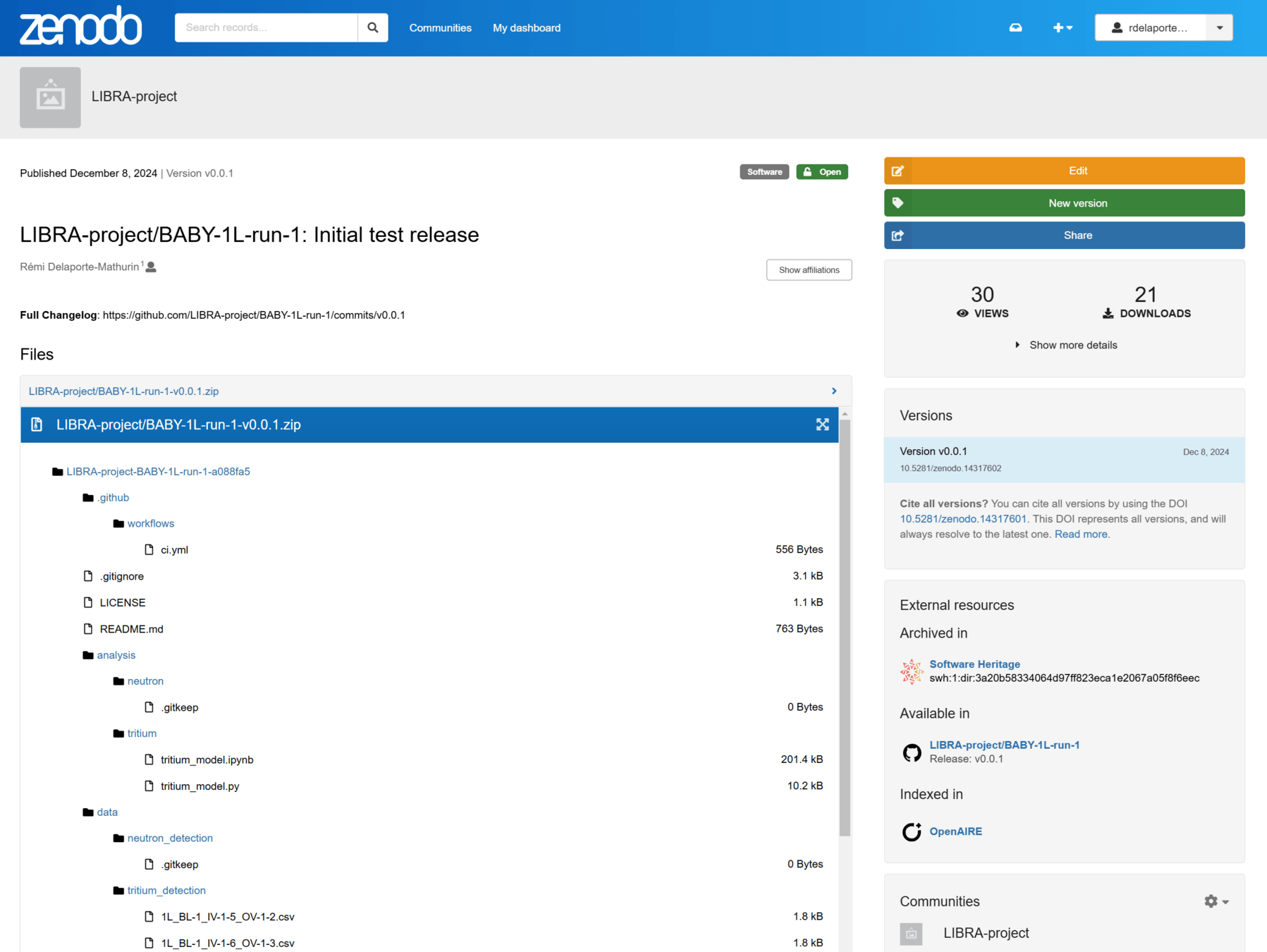
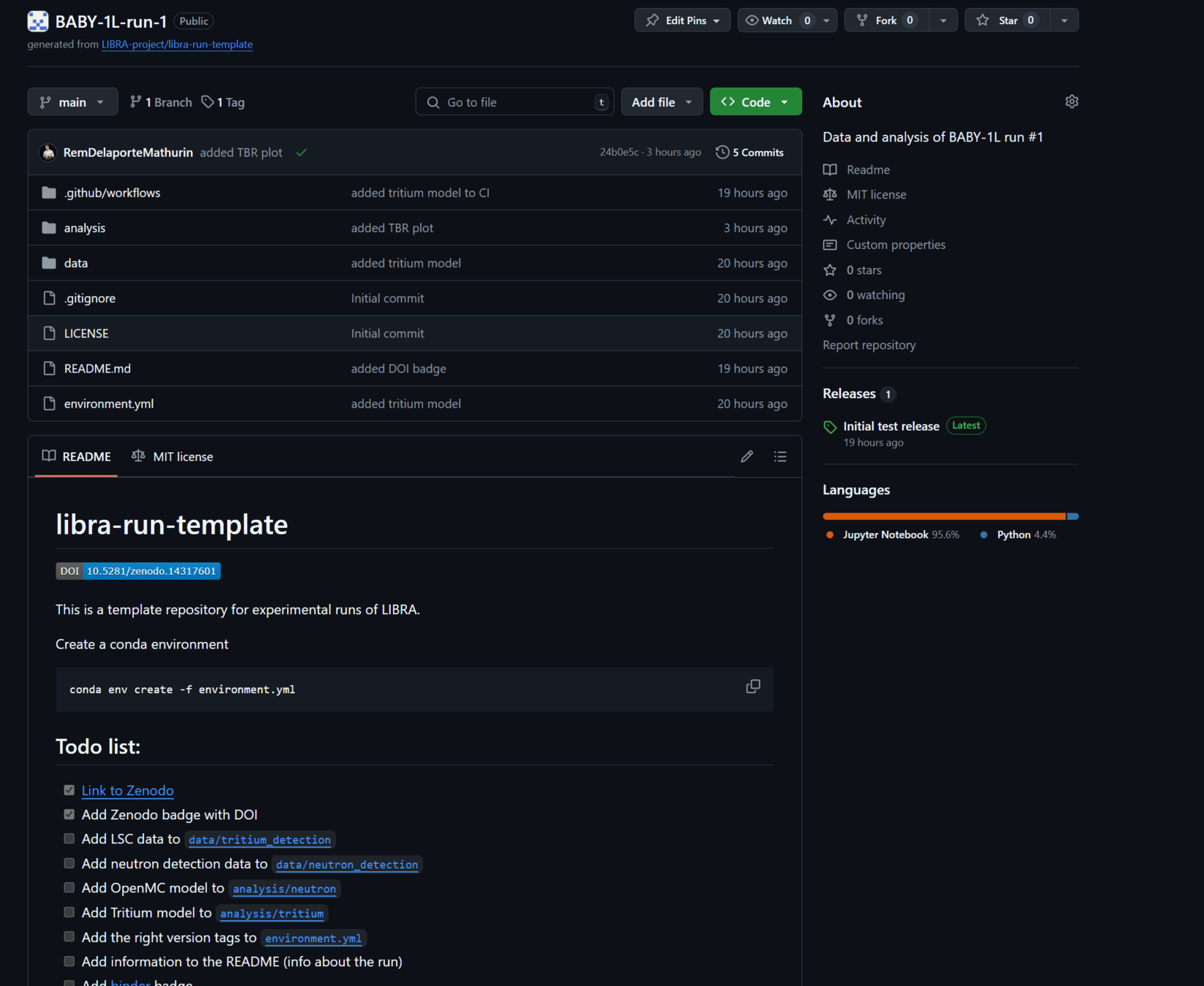
GitHub repository
BABY-1L-run-1

push
push
External libraries:
openmc, libra-toolbox, numpy...

release
v0.1
v1.1
v2.0
preserve
cite
reuse
reproducibility
Data collection
Data processing
Push to GitHub
Release to Zenodo
New run
Reuse
New GitHub repo
Cite
At least once a week
For major releases
The new LIBRA data management workflow
Example for BABY-1L-run-1
What do we need to make this work?
Agreed rules for Data management
- Push data to GitHub at least every N days
- What file formats?
Software engineering team skills
- Version control
- Continuous integration (testing)
- Development environments (eg. conda)
- Let's schedule a team-upskill session
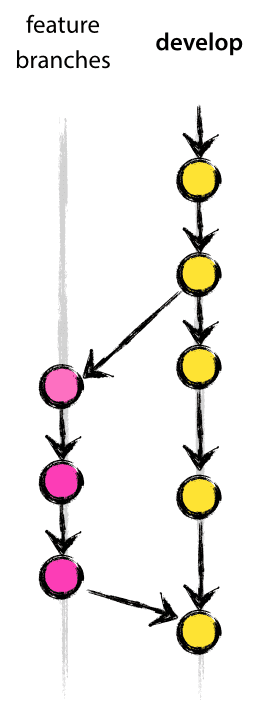
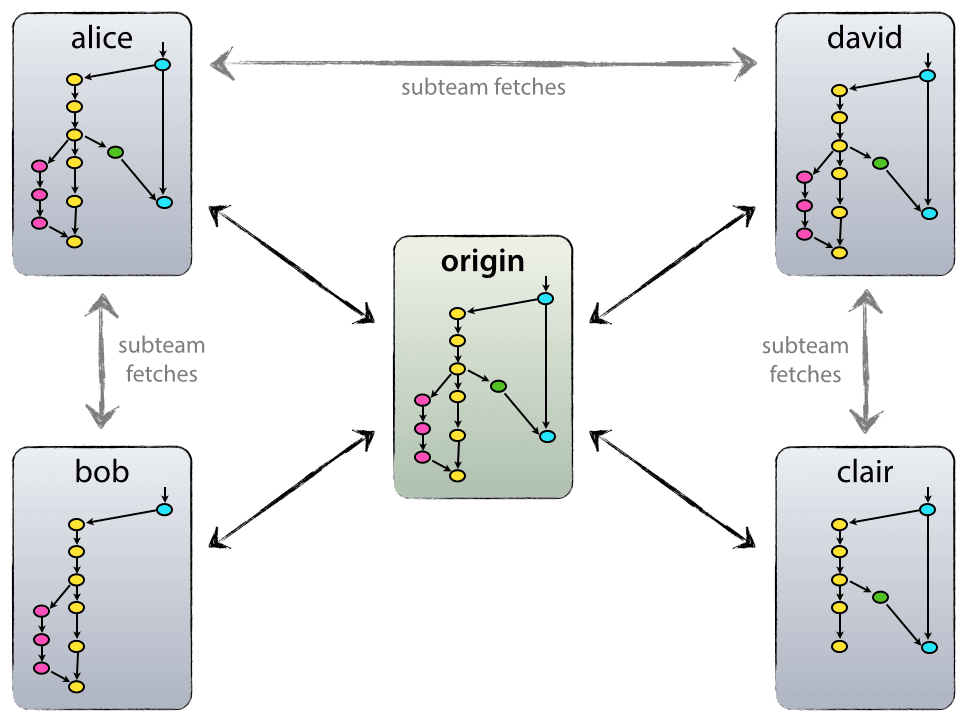
GitHub repository rules
- Branching model
- Release workflow
Roles and responsibilities
- I (Rem) am happy to be responsible for the whole process
- but, every team member must do their part!
Automation
- GitHub template
- Zenodo-GitHub integration
- Zenodo community for LIBRA
Team workshop
Does everyone have a GitHub account
The libra-toolbox package
We will learn:
- What is
libra-toolbox - version control (git)
- GitHub (PRs, branches, forks...)
- Continuous Integration
- How to contribute
The libra-toolbox package
The libra-toolbox package
A few dos and don'ts
- Do push your code regularly (at least once a week)
- Do write tests for your code
- Don't wait for your code to be perfect to push it
- Don't do
git add .!👿 - Don't push to
main,use branches to your advantage!
How to:
- Run the OpenMC model
- Run the tritium release model
- Add new LSC samples
- Push to the GitHub repository
- Release a new version of the repository
- Start a new run from the template
The analysis workflow
We will learn:
- LIBRA analysis
- version control (git)
- semantic versioning
- GitHub (PRs)
- GitHub Codespaces
- Continuous Integration
LSC
Activation Foils
Neutronics model
Tritium model
Diamond detector data
Experimental TBR
Modelled TBR
Mass transport coeff.
Aggreement?
Exp. data
Total T production
Total n production
Models

Reproducible research
How to:
- Make sure my research is reproducible
- Ensure correctness of my code
We will learn:
- conda environments
- Continuous Integration
- GitHub Actions
- Binder
Preserve data
We will learn:
- Zenodo
- Integration with GitHub
- Zenodo LIBRA community: zenodo.org/communities/libra-project/records
More resources
- The Turing Way book: book.the-turing-way.org/
- Python (programming and plotting): swcarpentry.github.io/python-novice-gapminder
- Research Software Development: carpentries-incubator.github.io/python-intermediate-development
- Version control with Git: swcarpentry.github.io/git-novice
LIBRA data management strategy
By Remi Delaporte-Mathurin



