

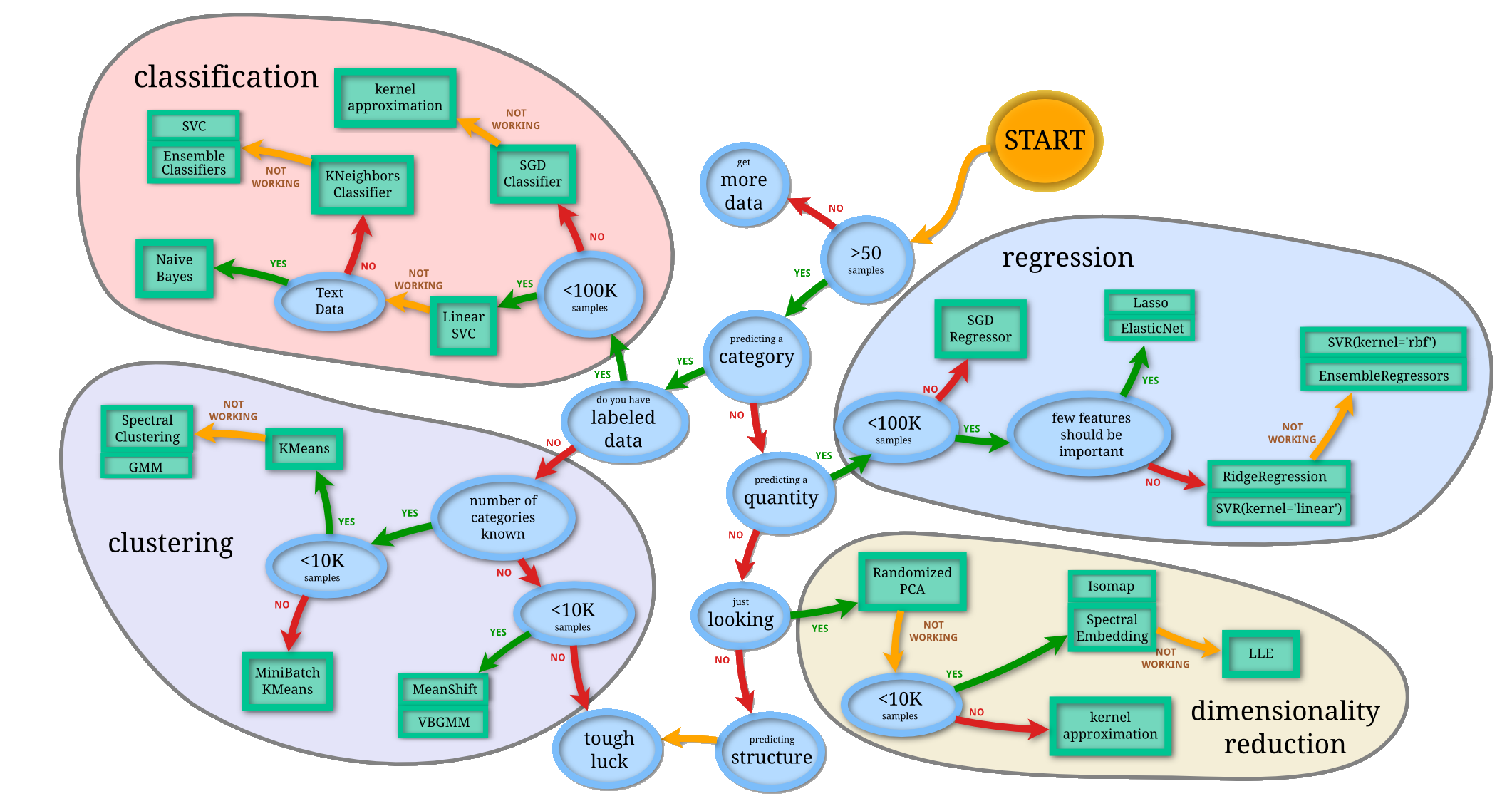

Candidate Bot


Scrape
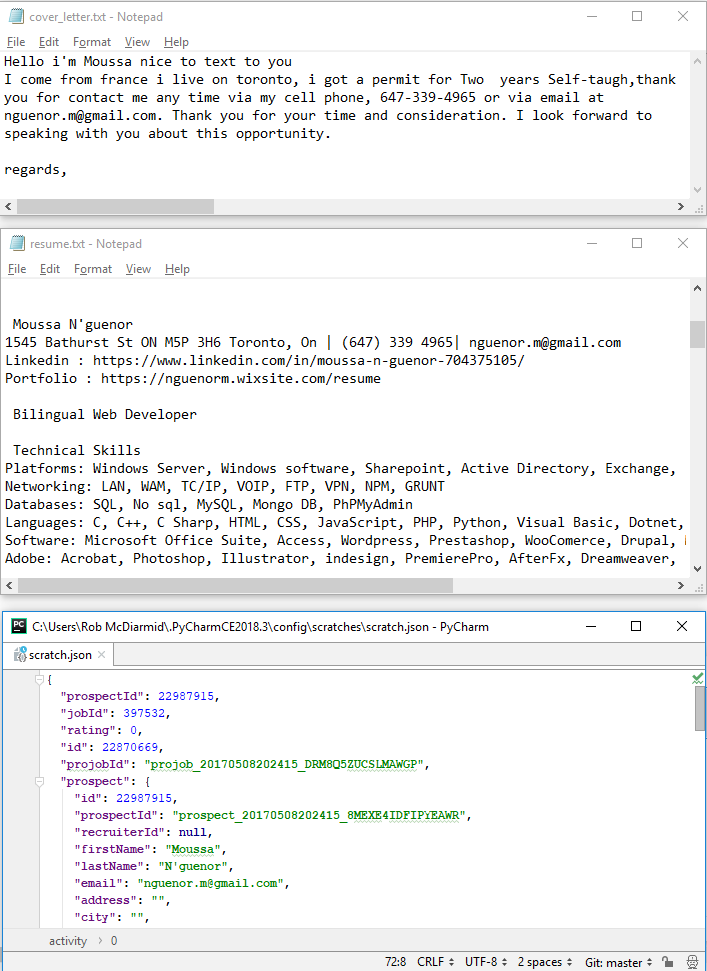
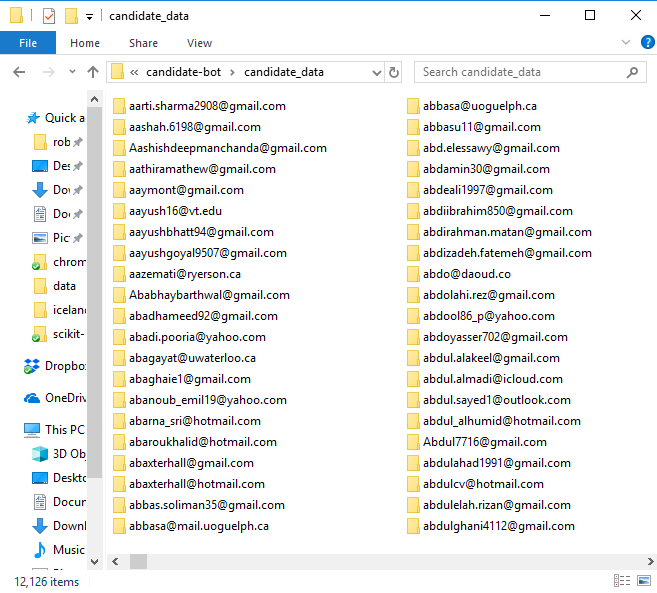
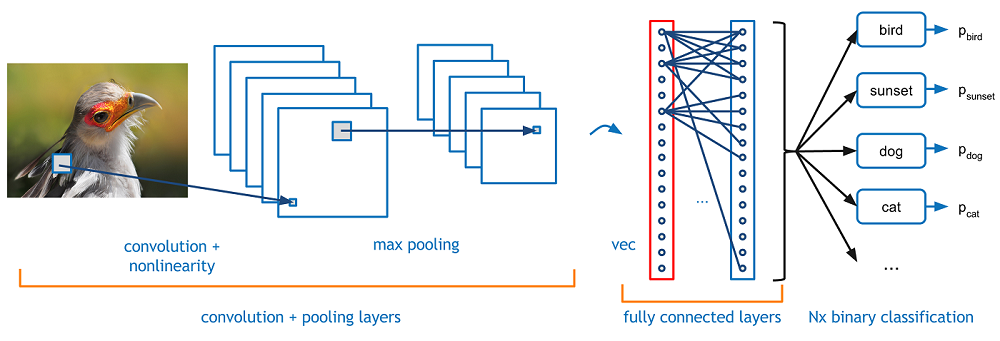
Preprocess
Structured data
Extract City, province, source, apply context

Text data
TF-IDF Vectorization
[0.14, 0, 0, 0.34, 0, 0, 0.33, 0, 0.21, ...]PCA Dimensionality Reduction
[0.91, 0.03, 0.44, 0.82][0, 0, 0, 1, 1, 0, 1, 0.91, 0.03, 0.44, 0.82, 0.33, 0.10, 0.22, 0.81, 0.72, 0.43, 0.80 , 0.01]Train / Predict
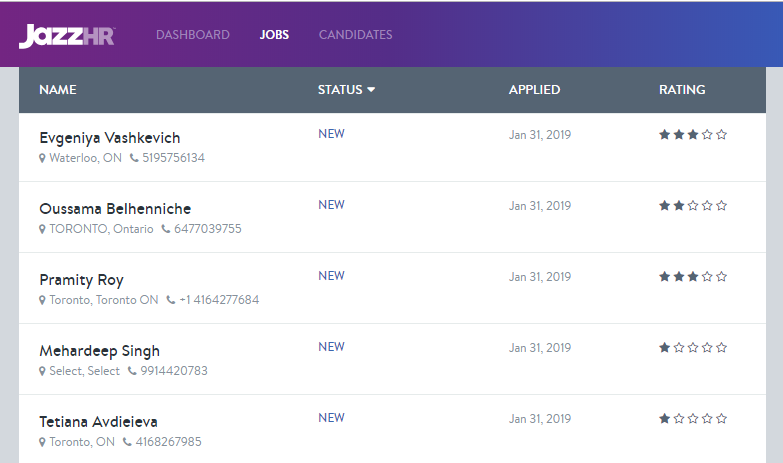

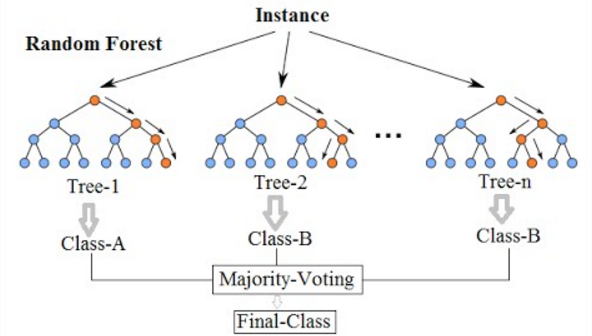
Train with existing
candidates
Predict with new candidates
Classification
Reinforcement Learning
Past data
resume
cover letter
Hired / Not Hired


Future data
resume
cover letter
Hired / Not Hired

1. Observe state
- Who works here
- Who is applying
2. Predict
- What long term affect would each action have on the company
4. Remember
- Record initial state, resulting stat, and immediate affect on the company
3. Act
- hire / fire
5. Train
- Pick samples from memory and train AI to better predict long term affect of the action taken
| Initial State | Action | Result State | Immediate Reward |
|---|---|---|---|
| S1 | A1 | S2 | + $1000 |
| S2 | A2 | S3 | - $520 |
S1
{
A1: "+$1,111,111",
A2: "-$222,222",
A3: "$3"
}Long term reward
longTermReward_{A1} = immedateReward1 + 0.9(immedateReward2 + 0.9(immedateReward3 + ... ))
longTermReward_{A1} = immedateReward1 + 0.9(longTermReward_{A2})
//memory = {state1: S1, action: A1, state2: S2, reward: 1000}
input = [S1]
output = bot.predict(S1) //{A1: 1111111, A2: -222222, A3: 3}
output.A1 = 1000 + 0.9 * max(bot.predict(S2))
bot.train(input, output)deck
By Rob McDiarmid




