Extração de características para impressoras laser utilizando
uma abordagem de deep learning
Prof. Dr. Milton Hirokazu Shimabukuro
Orientador
Robson Cruz
Orientando
Relembrando...
O que buscamos
- Utilizar a estratégia proposta por FERREIRA, 2017;
- Realizar a implementação da estratégia utilizando Python/Tensorflow;
- Avaliar os resultados obtidos com alterações no ambiente experimental
Implementação
- Utilização de Redes Convolucionais para a extração de características;
- Concatenação de vetores de caracteríticas (early fusion);
- Alimentação dos vetores de características para um classificador, em uma estratégia One-vs-One;
- Processo de votação e escolha (late fusion).
Visualmente

Sobre a implementação e execução
O método descrito foi implementado na linguagem Python, se utilizando das bibliotecas Tensorflow, Keras, OpenCV-Python e SKLearn
O algoritmo está sendo executado no cluster do DMC, em nós com um processador Intel(R) Xeon(R) CPU E5-2690 0 @ 2.90GHz, com 32GB de RAM
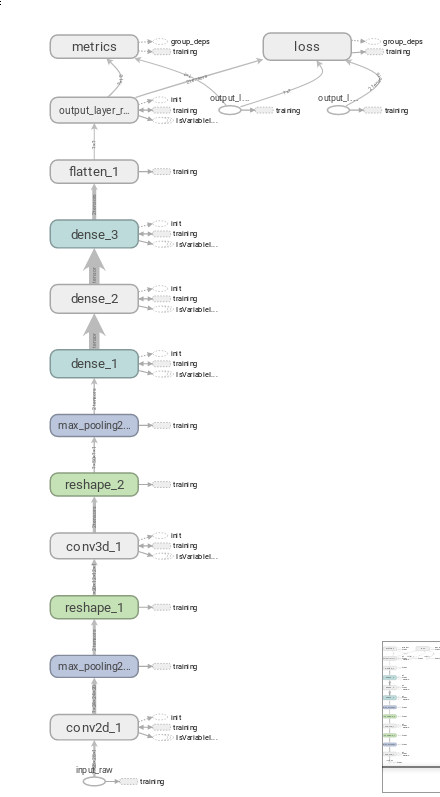
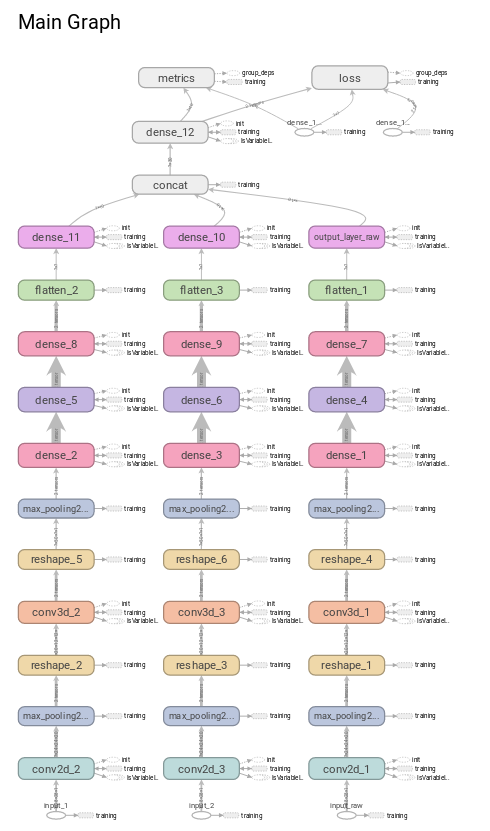
Resultados obtidos
Testes realizados
- Foram realizados testes com diferentes porções do dataset original:
- ~1% = 2500 samples;
- ~10% = 25000 samples;
- ~20% = 50000 samples;
- ~40% = 100000 samples.
- O dataset original para a letra 'e' possui 245000 samples
Acurácia
- A acurácia do modelo original é 97.33%±0.0065;
- Esse resultado foi alcançado com um treinamento de 30 épocas, utilizando batches de 100, e um otimizador SGD com momentum de 0.9, decaimento de 0.0005 e índice de aprendizado inicial de 0.001;
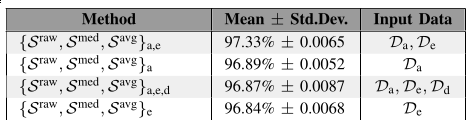
Acurácia
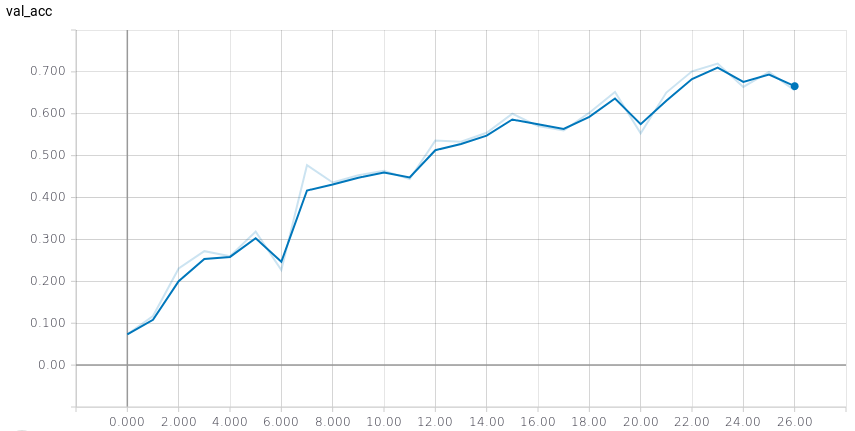
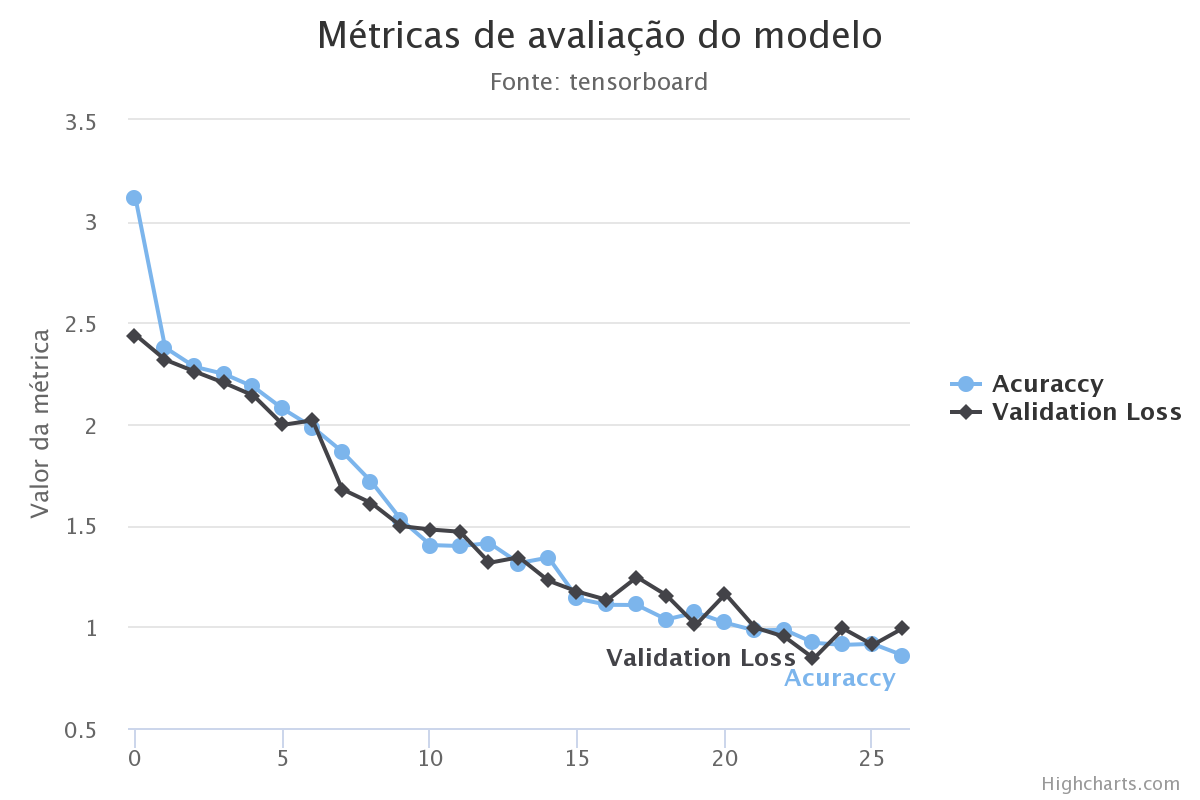
- A implementação do modelo alcançou uma acurácia de 74.17% após 30 épocas, em um teste com 1% do dataset original;
- Os resultados obtidos variaram de 70% a 75%;
- Para alcançar tal resultado foi necessário diminuir o índice de aprendizado de 0.001 para 0.0001;
- Essa acurácia leva em conta apenas até a fase de early-fusion.
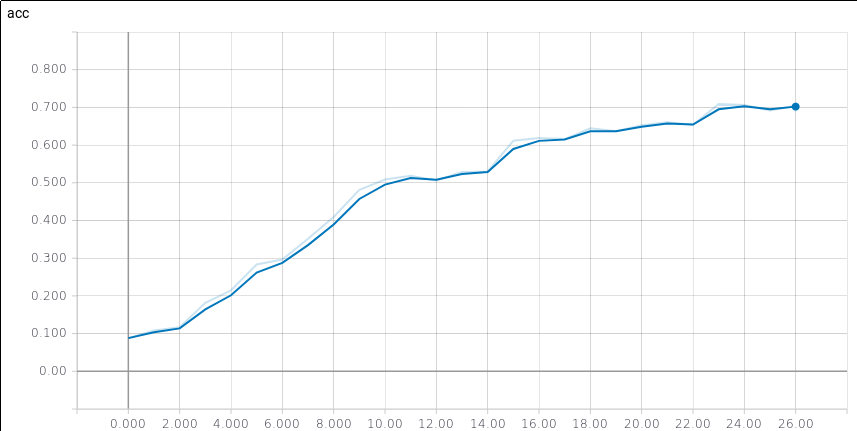
Accuracy
Validation Accuracy
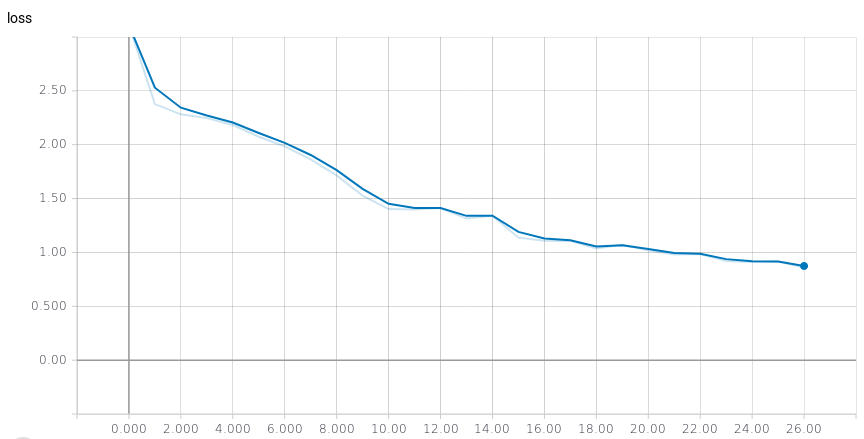
Diminuição do custo de treinamento
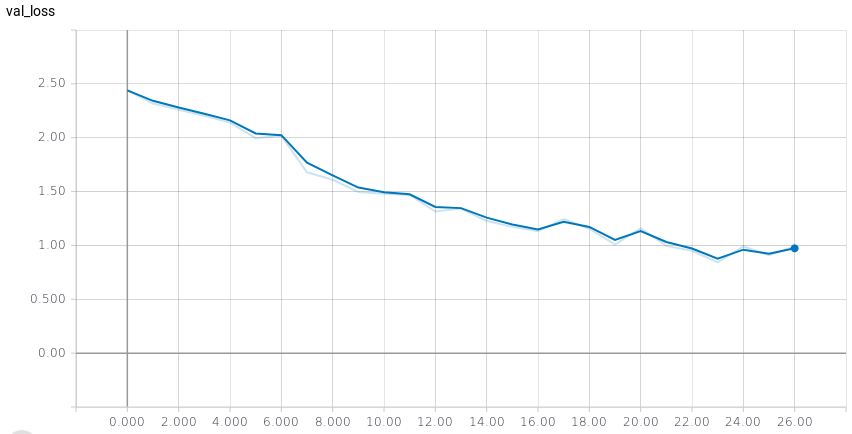
Diminuição do custo de validação
Comparação
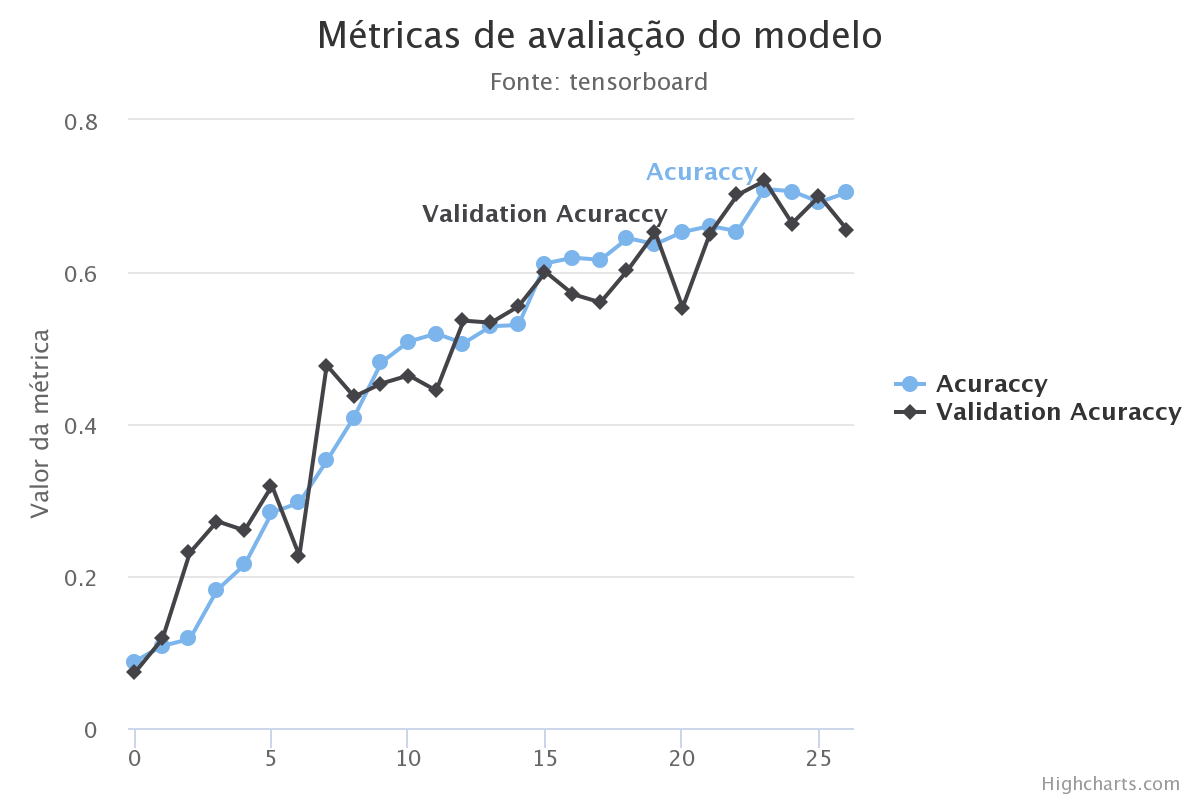
Comparação
Acurácia
-
Para verificar a acurácia do modelo foram realizados dois processos:
- Avaliação do extrator de características;
- Avaliação do classificador treinado com os vetores de características extraídos;
evaluation_model = KerasClassifier(
build_fn=build_model, epochs=epochs, batch_size=batch_size, verbose=0)
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7)
results = cross_val_score(
evaluation_model, X, y=y, cv=kfold)
logger.info(results.mean())Observações
- Devido a uma possível diferença na implementação interna do otimizador, é possível que se alcance uma acurácia diferente do esperado;
- A tática de cross-validation utilizando k-folds se mostrou muito efetiva para a avaliação desse modelo.
- Seria interessante comparar o tempo de treinamento do trabalho original para verificar a performance da implementação;
- O processo de late-fusion precisa ser testado para considerar a implementação finalizada.
Obrigado
[TCC 2] Apresentação Final
By Robson Cruz




