Meta-Learning for Manipulation
Final Project for 11-785: Intro to Deep Learning
Rohan Pandya, Alvin Shek, Deval Shah, Chandrayee Bhaumik

Problem Description
RL + Meta-Learning for Manipulation
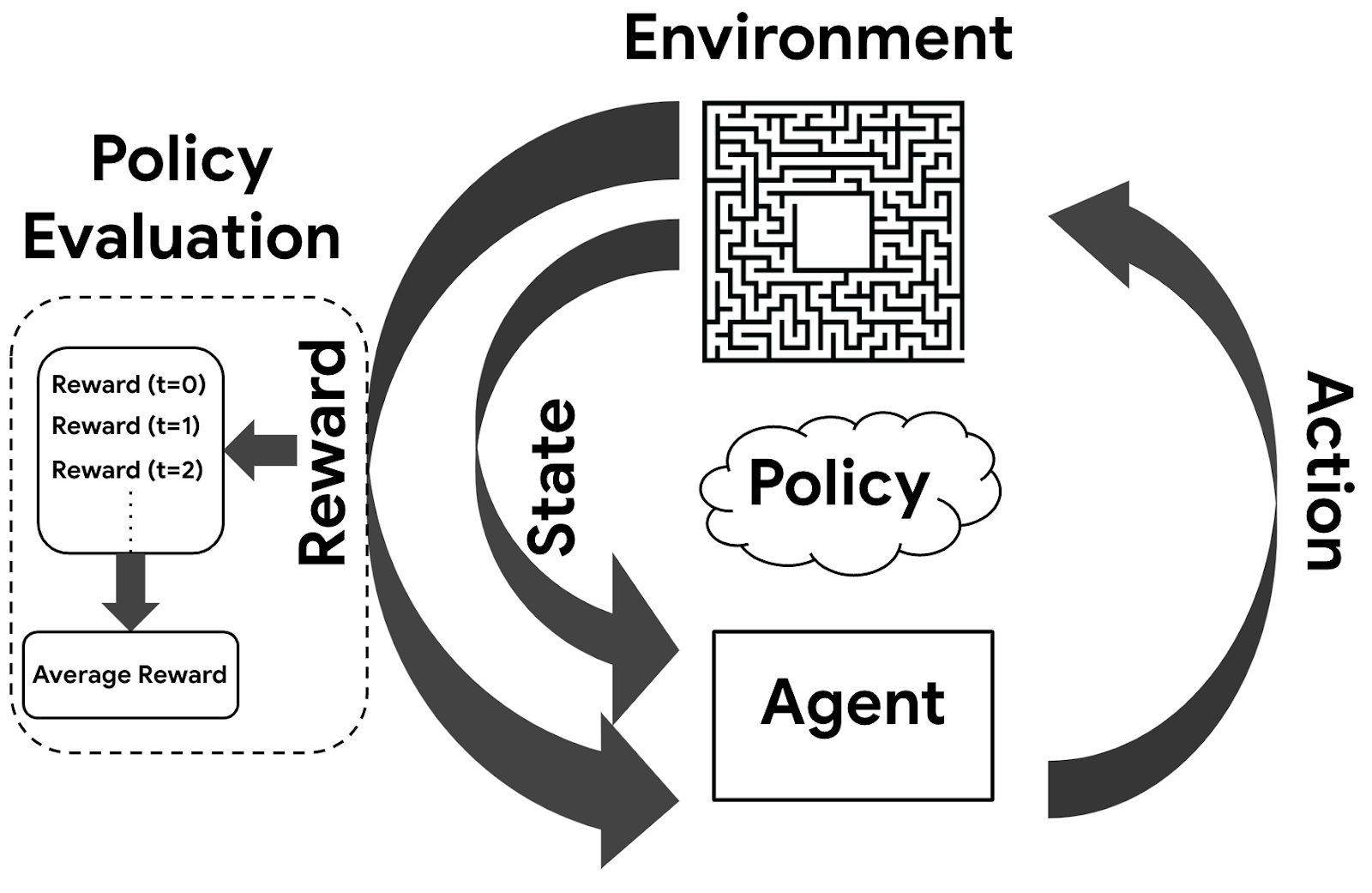
Meta-Learning
Learning to learn (meta-learning) is a skill that enable humans to generalize and transfer prior knowledge.
Goal: Quickly retrain a trained model to learn a new task from few samples
Meta-Learning enables:
- Sample efficiency
- Leverage prior experience
- Generalization


Problem Description
Reinforcement Learning
Learning useful policies by directly interacting with the environment and receiving rewards for good behaviors
Advantages:
- No need for labeled data
- Generalizable
- Very few priors needed
Disadvantages:
- Real-world experience is expensive
- Slow and unstable convergence
Problem Description
Robotic Manipulation
Robotic Manipulation refers to the use of robots to effect physical changes to the world around us. Examples include moving objects, grasping, carrying, pushing, dropping, throwing, and so on.
Challenges:
- Expensive to gather data
- Difficult to simulate contact dynamics and accurate physics
- Learned policies brittle to environmental changes, generalization
- Supervised learning difficult due to nature of the problem
Problem Description


Meta Learning + RL + Manipulation
- RL offers a robust, scalable approach to learning novel manipulation tasks
- Meta Learning addresses the sample inefficiency and expensive data collection issues by allowing for effective learning of the shared structure between tasks
Problem Description
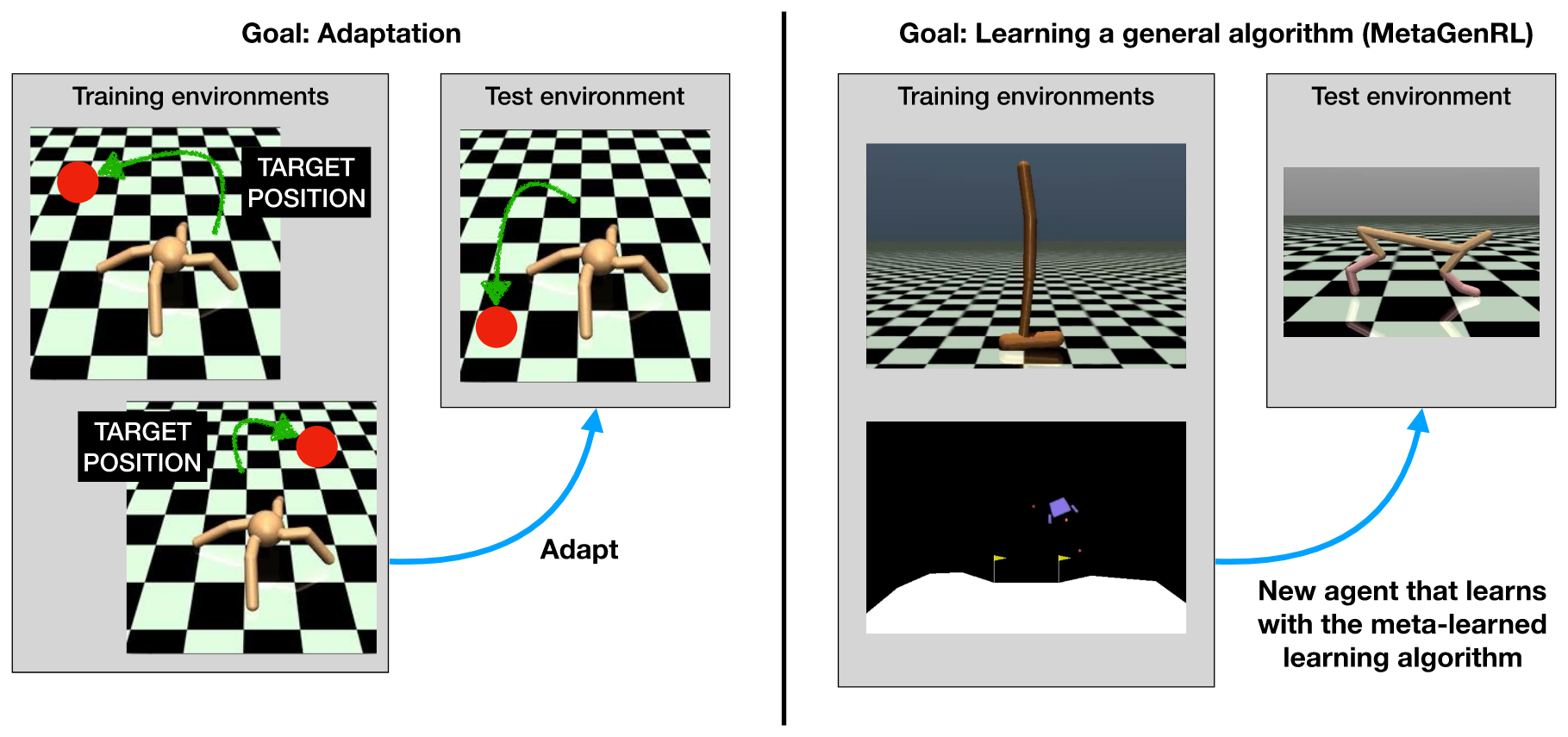
Current Approaches to Meta Learning
Broad categorization of Meta-Learning approaches:
- Metric Based
- Model Based
- Optimization Based
- MAML
- Reptile
Problem Description
Task
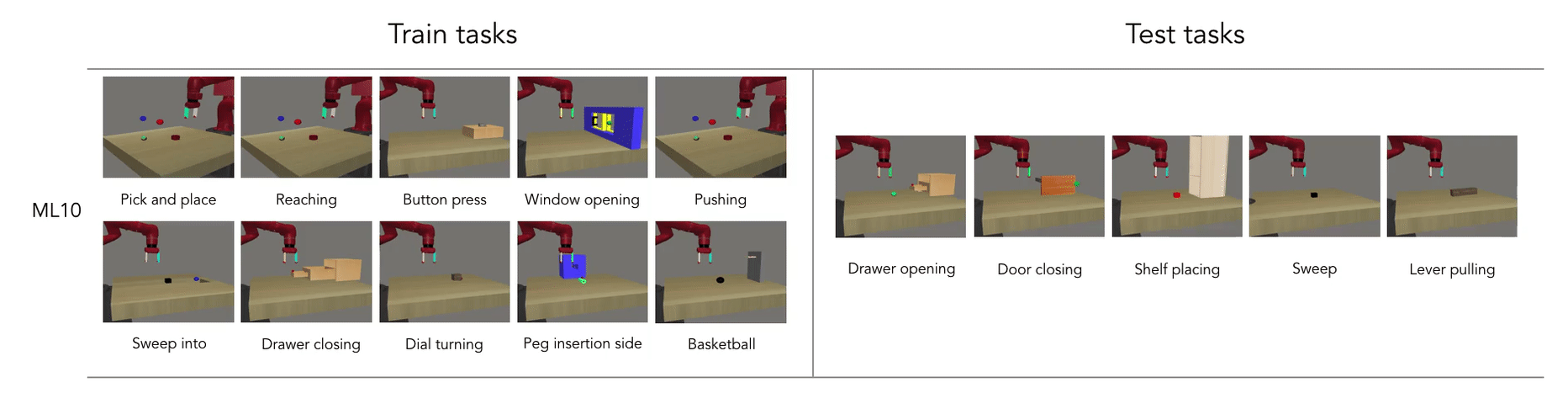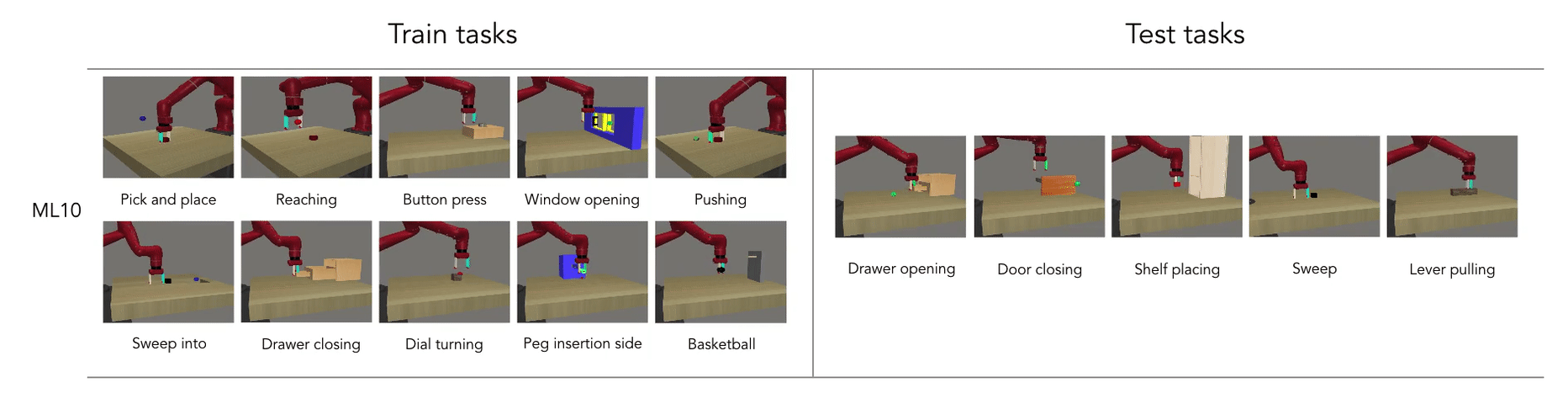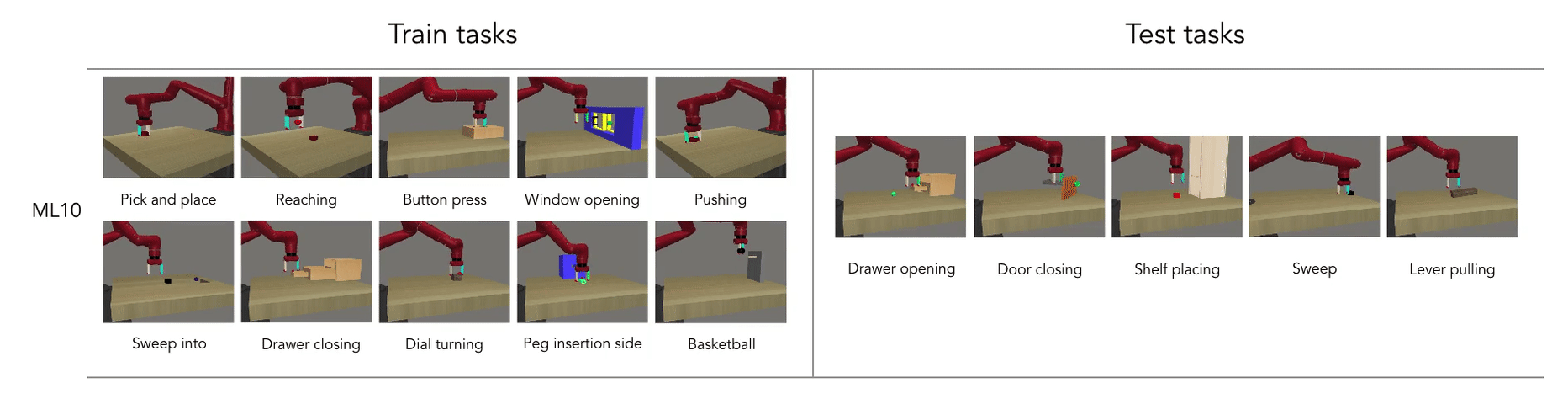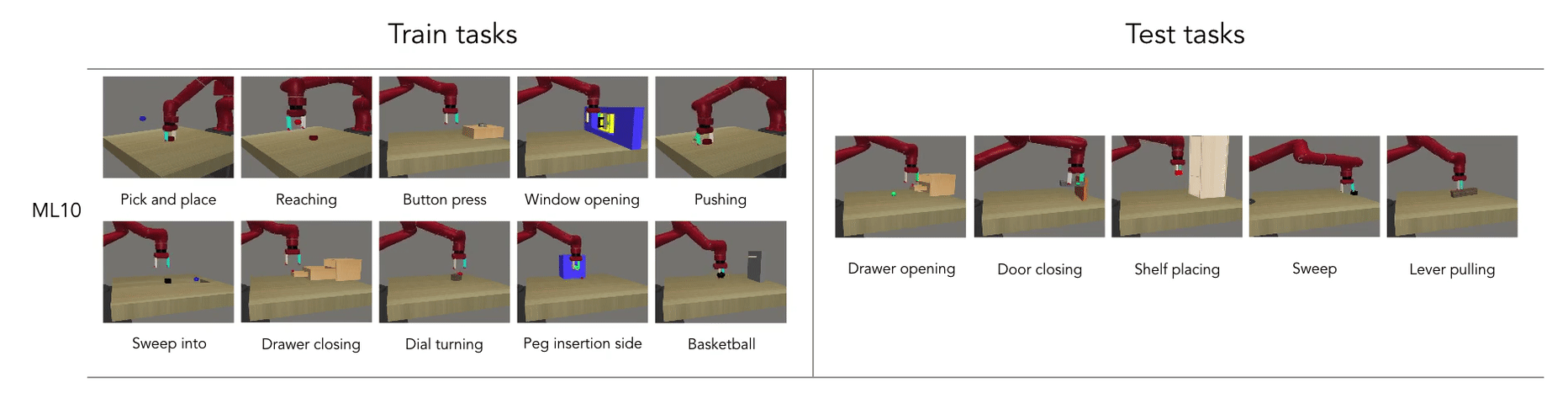
Benchmarking Meta-Learning Approaches
Manipulation Task: Reach
- Learning the reach manipulation task
- Task benchmark suggested by Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning
- Meta-Learning 1 (ML1): Few-shot adaptation to goal variation within one task
- Represents parametric task variation
- Train tasks: 10 reach goals
- Test tasks: 5 reach goals

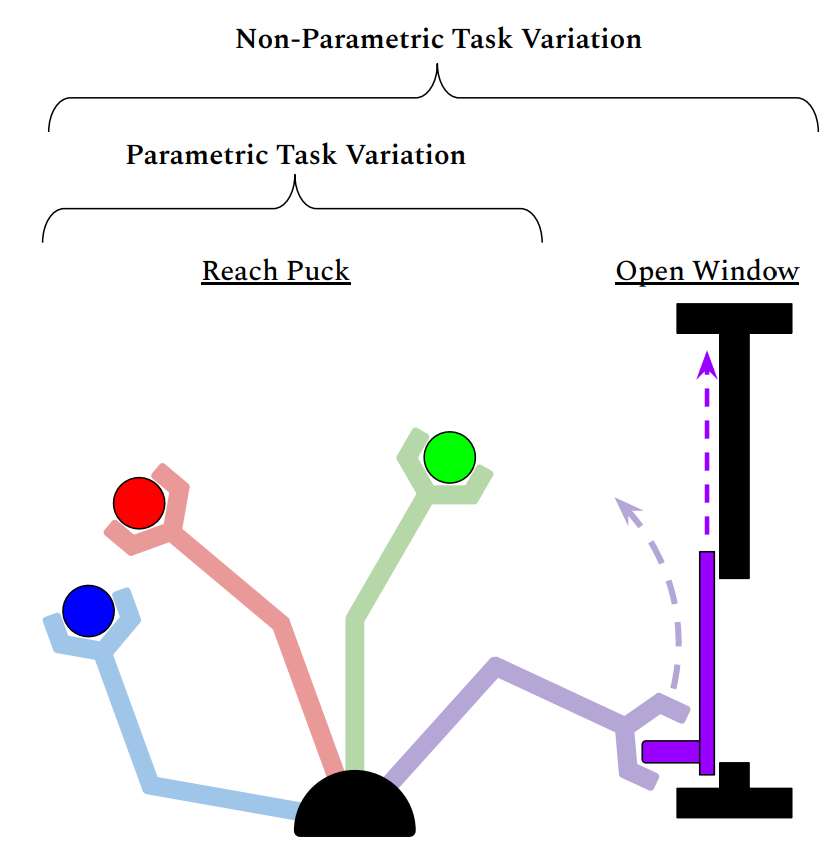
Fig: Train and Test tasks showing parametric task variation
Fig: Parametric vs Non-Parametric Task Variation
RLBench: Simulator
- Benchmark and learning-environment for robot learning
- Built on top of Coppelia-Sim
- Goal: Reach the red target from a fixed starting position

Fig: 7 DOF Arm performing reach-task in RL-Bench Simulation
Dataset
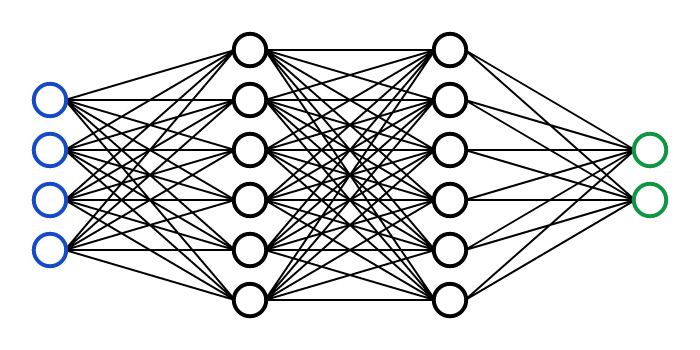
Policy Network
Inputs: EE Pose, Goal Pose
Outputs: Delta EE pose

EE Pose
Goal Pose
Delta EE Pose
Approach/Methods
Learning the Reach-Task
PPO
• Policy gradient RL Algorithm
• Improvements over other PG methods
• Still sample inefficient (200K+)
Reptile
• Policy gradient RL Algorithm
• Improvements over other PG methods
• Still sample inefficient (200K+)
MAML
• Model-Agnostic Meta-Learning
• General optimization algo, compatible with any model that uses SGD
• Learns good policy parameter initializations

Multi-headed Reptile
- Investigate a proposed batch version of the algorithm empirically
- Evaluates on n tasks at each iteration and updates the initialization by the following rule
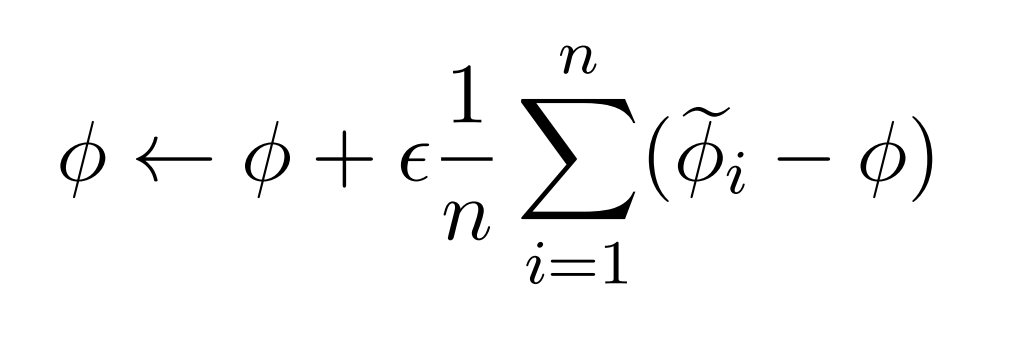

Batch update rule
initialization parameters
updated parameters
on the i-th task
Multi-headed Reptile
-
Batch updates are lower variance, and have potential to lead to faster convergence.
-
This is similar to performing mini-batch GD vs SGD

Multi-headed Reptile:
Asynchronous updates
- Implemented this asynchronously
- Same wall-clock time as the serial version
- More stable updates (in theory) without additional time
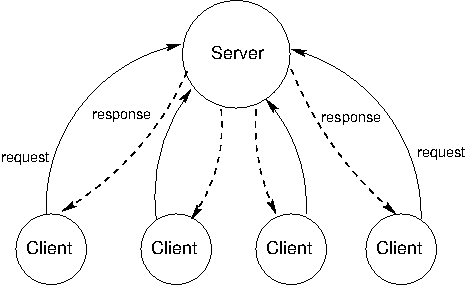

}
N parallel workers
Results & Discussion
Results - Success Rate
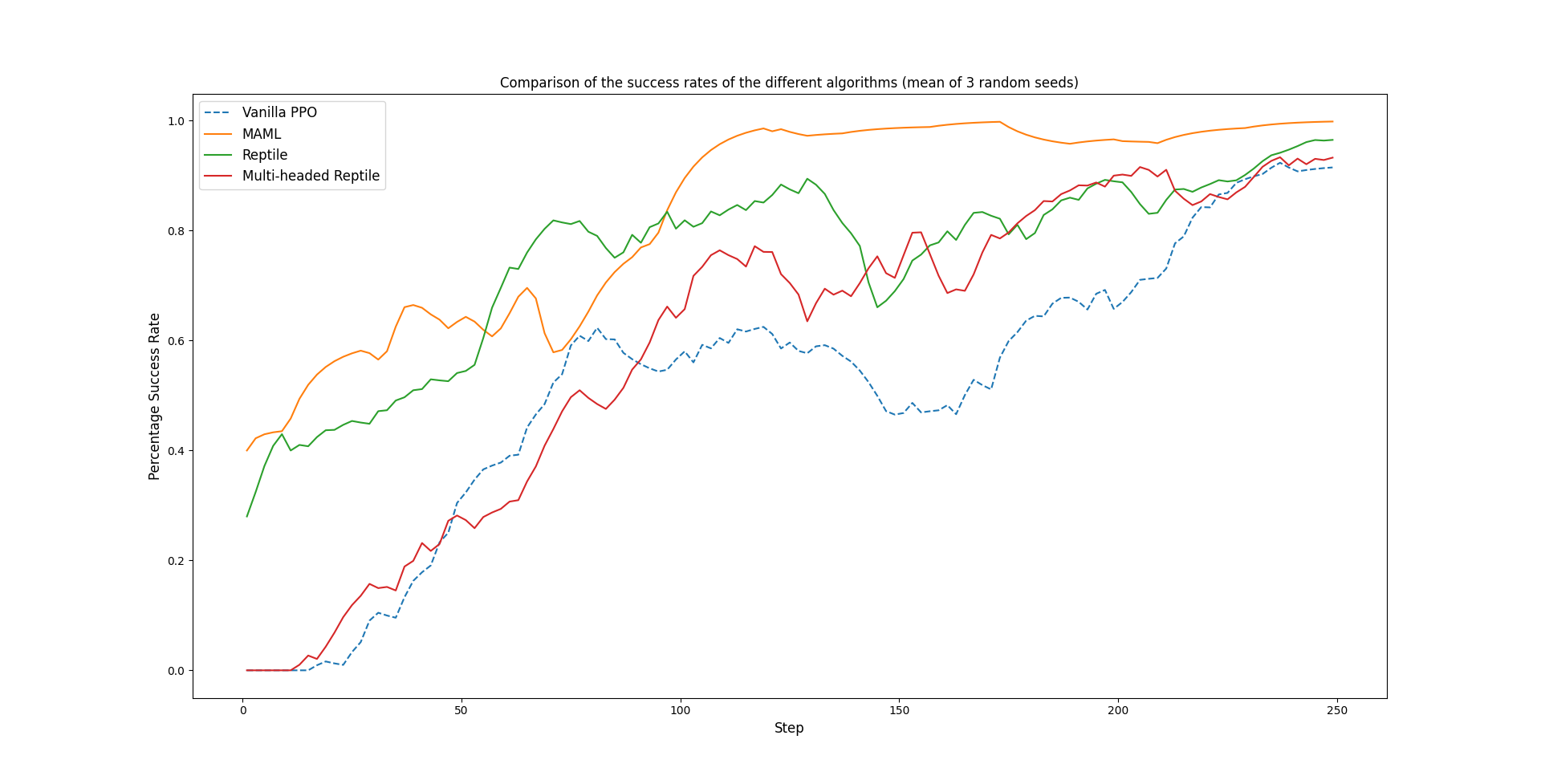
80% success rate
Reptile
MAML
Multi-Headed Reptile
Vanilla PPO
Multi-headed reptile doesn't work
-
In multi-headed reptile, we directly changing the parameters based on the updated parameters of task-specific models
-
Effectively we only account for first order gradient terms and entirely lose information of higher order terms.
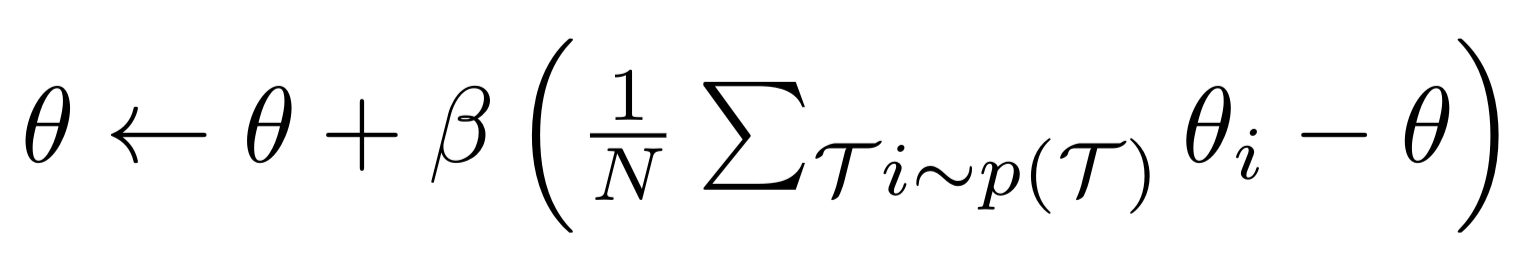
-
Batch gradient descent and batch parameter weight update have different convergence properties

Results - Training Times

- Training time for multi-headed reptile comparable to the reptile
Conclusions
RL + Meta-Learning for Manipulation
Conclusions
-
Confirmed and benchmarked two meta-learning algorithms for manipulation:
-
MAML > Reptile > PPO ~ Multi-headed Reptile
-
-
In this work we explored Multi-headed Reptile, which has the following two changes
- Batch updates of parameters : Does not provide the performance boost due to loss of higher order terms
-
Asynchronous training : This speeds up the training process
-
Further investigation needed into the probable causes of its failure and potential fixes
Thank You
deck
By Rohan Pandya