Szabo Roland Teodor
UBB
Obtaining personal Finance data from receipts using machine learning
Contents
- Motivation and Problem Statement
- Related work
- ReceiptBudget - the application
- Conclusions
The results obtained in this paper were also presented at the Scientific Communication Session for Students
Motivation
- came to college in 2011
- money seemed to evaporate
- needed a tool to keep track of it
- existing ones weren't good enough
Aims
- create a new personal finance management tool
- develop an OCR engine tailored for receipts
- show interactive visualizations of expenses
Optical character recognition
Steps performed
Existing OCR ENGINEs
OCROpus
- poorer recognition performance
- does sophisticated document layout analysis
Tesseract
- good general performance
- no document layout analysis
Our OCR engine
- knows layout of receipts
- specially trained for receipt font
- which is weird, compressed, broken
Dataset
- 20 receipts were annotated by hand
- ~7000 characters
- 74 classes (different characters)
BUILT USING:
All three free, open-source libraries for scientific computing, machine learning and computer vision
Results
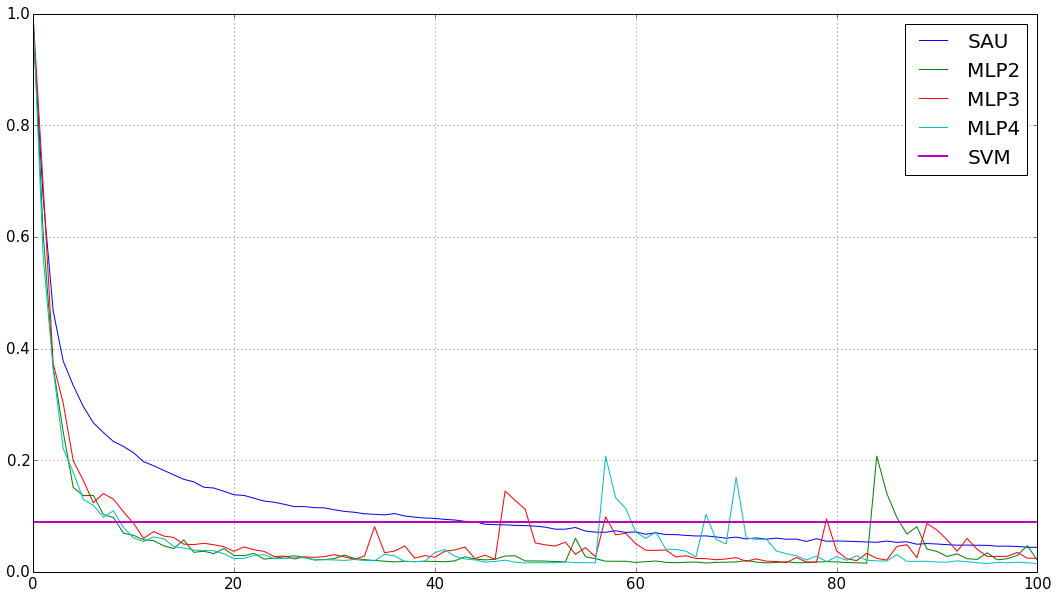
Character Recognition
- SVM baseline with RBF kernel - 91.01%
- deep learning with neural networks - 98.5%
| Model | Mean accuracy | Std deviation |
|---|---|---|
| SVM | 91.01% | 0.126 |
| SAU | 95.625% | 0.387 |
| MLP2 | 97.988% | 1.244 |
| MLP3 | 97.576% | 1.768 |
| MLP4 | 98.506% | 0.256 |
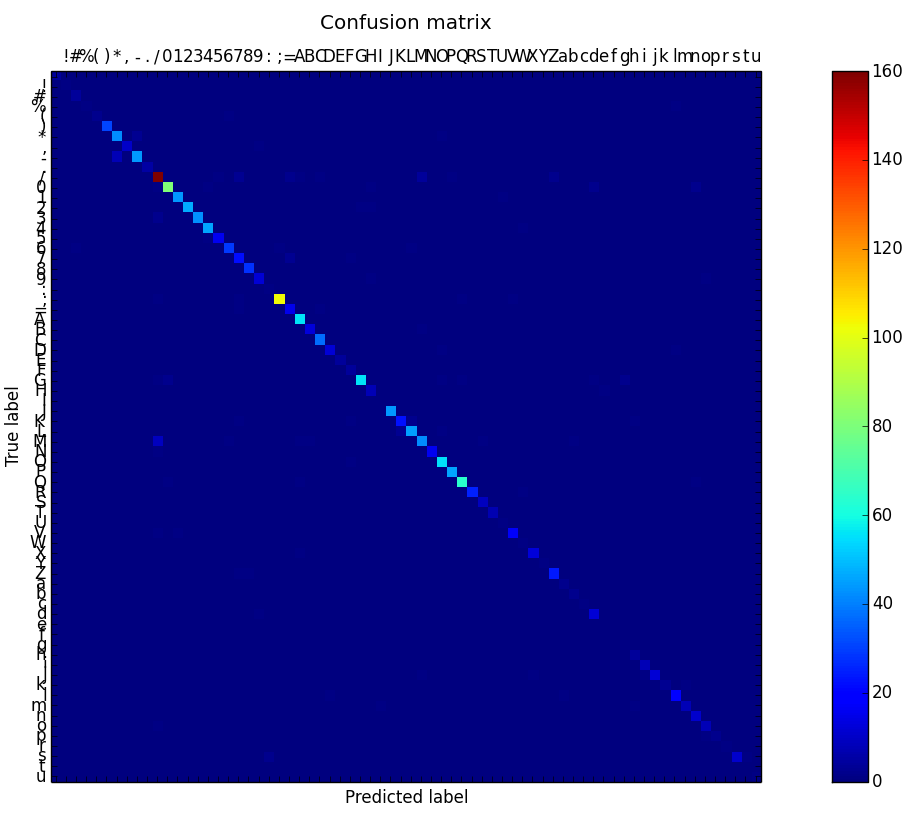
Most common missclassifications
- , and . - 40 times
- O and 0 - 39 times
- 1, l and I - 14 times
- Random forests
-
tried between 150 and 250 trees
- number of features used between 8 and 120
- best F1 score of 87.9%
Confusion Matrix
|
|
No split
|
Split
|
|
Predicted no split
|
4556
|
363
|
|
Predicted split
|
255
|
2546
|
Model is more specific, rather than sensitive
Line Classification
- mostly regular expressions to match various patterns
- 92.8% accuracy
- depends a lot on results from previous step:
- T0TAL
- STA REPUBLICII
Comparison to Other Results
- recognition results obtained by others on MNIST are better
- SVM with RBF kernel - 98.6% accuracy
- state-of-the-art - 99.7%
- 10x bigger dataset
- 7x fewer classes
- segmentation results for license plate are better
- 96% accuracy
- fixed number of letters to be segmented
Tesseract
ReceiptBudget

S.C. HRTIHH 5.9. ELUJ NHPUCH. STR. BUCEGI. NR. 19 9.9.1. 99 11735629 RUN 1.999 x 3.19 BRTISTE N9Z.CLHS|C3S 3.19 9 1.999 x 2.59 STICKLETTI CHRTUF 99 2.59 9 9.399 x 7.99 HHNDHRINE 3.12 H 9.446 x 7.99 99511 3.56 9 1.999 x 11.29 SHLHH C959 USCHT 299 11.29 9 SUBTUTHL 23.5? SUBTUTRL _____ ‘-29:99 TUTHL 23.57
S.C. ARTIMA S.A. CLUJMAPOCA, STR. BUCEGI, NR.19 C .U.1,R O1 1735628 RON 1.000 x 3,19 BATISTE NAZ.CLASIC3S 3,19% 1,000x 2,50 STICNLETTI CARTOF 80 2,50 A 0,390 x 7,99 MANDARINE 3,12A 0,446 x 7,99 R0SI 3,56 A 1.000 x 11,20 SALANIASAOSCAT 290 11,20A SUBTOTAL 23,57 SUBTOTAL 23,57 TOTAL 27,57
The Application
- ReceiptBudget has an interactive dashboard
- The goal is to get some insight into spending patterns
THE map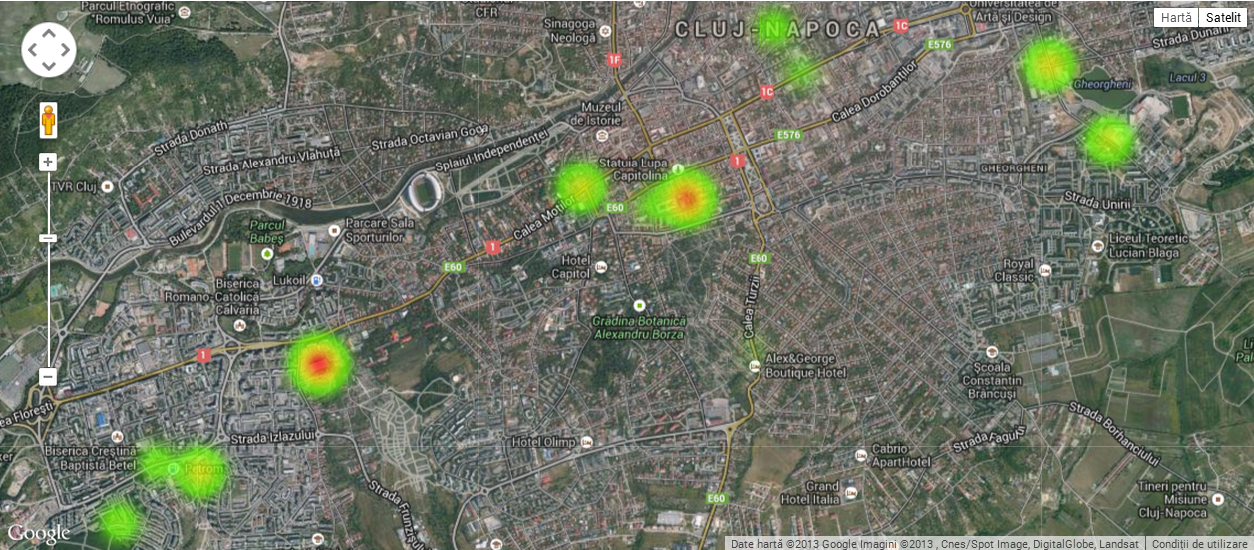
The charts
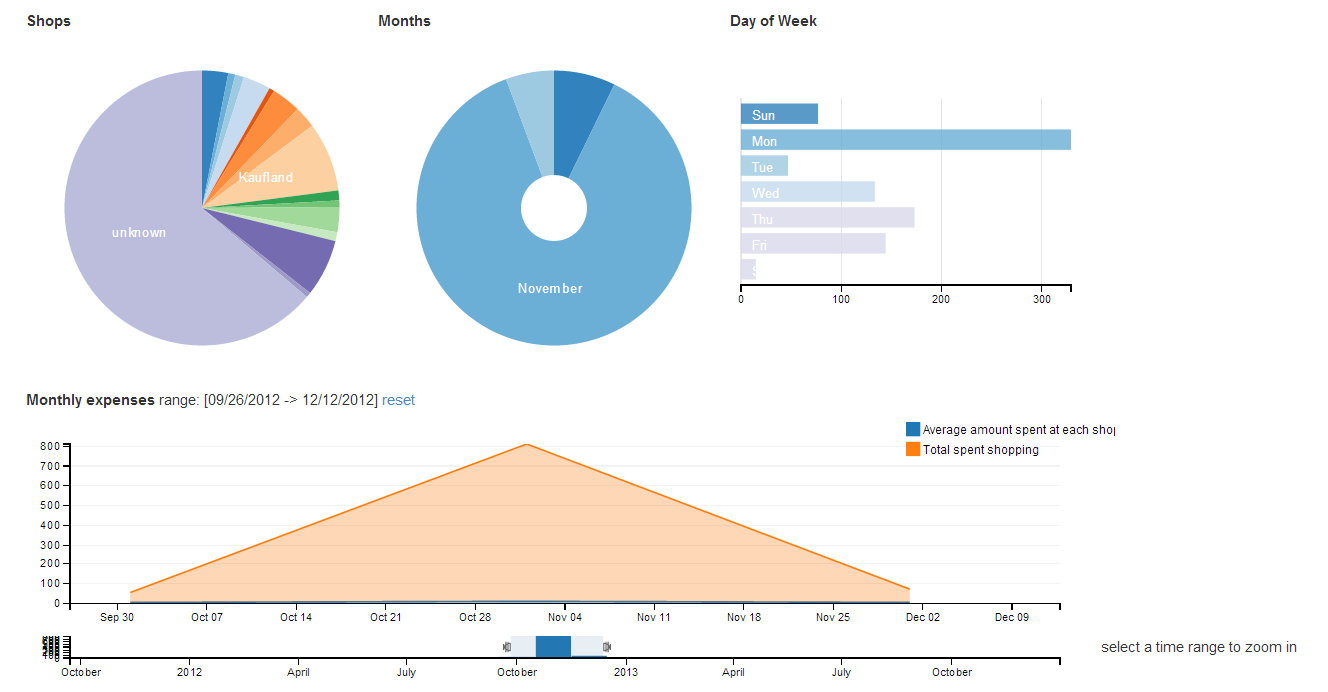
Built USING
Conclusion
- OCR results are better than by using off-the-shelf components
- incorporating domain specific knowledge helps
- interactive dashboard is helpful
- I saved some money:)
Questions?
Licenta
By rolisz



