

















russtedrake PRO
Roboticist at MIT and TRI
(Foundation models for dexterous manipulation)
Russ Tedrake
MIT, EECS/CSAIL
russt@mit.edu
large language models
visually-conditioned language models
large behavior models
\(\sim\) VLA (vision-language-action)
\(\sim\) EFM (embodied foundation model)
\(\Rightarrow\) Many new startups (some low-cost, some humanoids)
Why actions (for dexterous manipulation) could be different:
should we expect similar generalization / scaling-laws?
Success in (single-task) behavior cloning suggests that these are not blockers
Big data
Big transfer
Small data
No transfer
robot teleop
(the "transfer learning bet")
Open-X
simulation rollouts
novel devices
I really like the way Cheng et al reported the initial conditions in the UMI paper.
At TRI, we have non-experts run regular "hardware evals"
w/ Hadas Kress-Gazit, Naveen Kuppuswamy, ...
Example: we asked the robot to make a salad...
NVIDIA selected Drake and MuJoCo
(for potential inclusion in Omniverse)
(Establishing faith in)
(Establishing faith in)
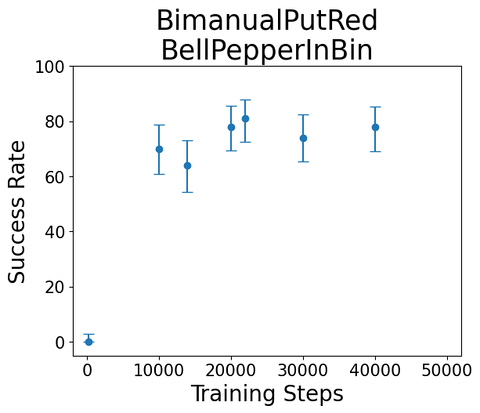
Task:
"Bimanual Put Red Bell Pepper in Bin"
Sample rollout from single-skill diffusion policy, trained on sim teleop
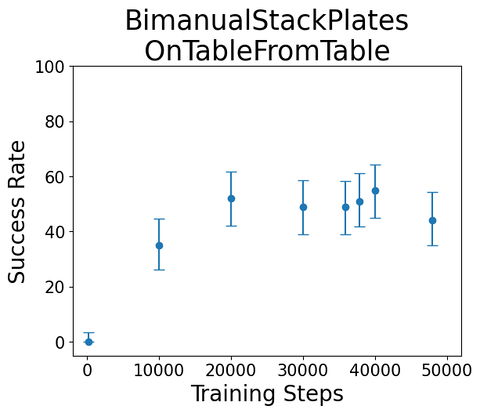
Task:
"Bimanual stack plates on table from table"
Sample rollout from single-skill diffusion policy, trained on sim teleop
(100 rollouts each, \(\alpha = 0.05\))
http://manipulation.mit.edu
By russtedrake




