k-最近傍法
Pythonではじめる機械学習 読書会
2017/8/30
宇都宮 諒(@ryo511)
k-最近傍法とは
- 英語ではk-Nearest Neighbor、k-NNともいう
- 新しいデータポイントに対する予測の際は、訓練データセットの中から一番近い点を見つける
- kは近い点をいくつ探すか
- k=1なら1つだけ、k=3なら3つの点の多数決で決める
k-最近傍法の特徴
- 利点
- モデルが理解しやすい
- 欠点
- 処理速度が遅い
- 多数の特徴量を扱うことができない
- "実際にはほとんど使われていない" らしい…
irisにおける最適なkは?
# p.40のコードのデータ読み込み部分をirisに変えただけ
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(
iris.data, iris.target, stratify=iris.target, random_state=0)
training_accuracy = []
test_accuracy = []
neighbors_settings = range(1, 30)
for n_neighbors in neighbors_settings:
clf = KNeighborsClassifier(n_neighbors=n_neighbors)
clf.fit(X_train, y_train)
training_accuracy.append(clf.score(X_train, y_train))
test_accuracy.append(clf.score(X_test, y_test))
plt.plot(neighbors_settings, training_accuracy, label="training accuracy")
plt.plot(neighbors_settings, test_accuracy, label="test accuracy")
plt.ylabel("Accuracy")
plt.xlabel("n_neighbors")
plt.legend()
plt.show()irisにおける最適なkは?(結果)
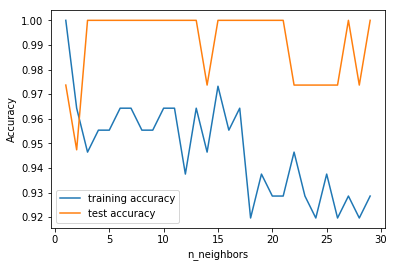
- scoreが1.0になるkの値がちらほら…
- kを増やしてもテストデータのscoreは大差ない
- kを増やすと訓練データのscoreは少しずつ落ちる
k-最近傍法
By Ryo Utsunomiya
k-最近傍法
Pythonではじめる機械学習 読書会(2017/08/30)




