Google Big Queryを使ってみよう
CALIL Inc.
Ryuuji Yosimoto
Code4Lib 2015
図書館の大規模データ分析に
Problem
データ分析がしたい
お金がない
人がいない
面倒なことはやらない

Hadoop is too expensive
and 面倒
小規模クラスタ(Hadoopごっこ)ではメリットが少ない
Compare Cloud Big Data Service
クラウド型のデータ分析サービスの比較
Google Big Query ・・・ データ従量課金
Amazon Redshift ・・・ インスタンス課金
Azure HDInsight ・・・ インスタンス課金 (Hadoop)
Google Big Queryの場合
ほぼ無料
$5 / 処理データ 1TB
$0.020 / ストレージ 1GB
※2016年1月から最大400%の値上げ
負荷の高いクエリーは 1TB / $20
管理画面付き ・・・ プログラミングの知識がなくても使える
カーリルでの活用例
システムエラーの検出
スクレイピング結果の精度分析
(テキスト形式のログを統計する
簡易的なプログラムから移行)
スキーマを定義 / Python
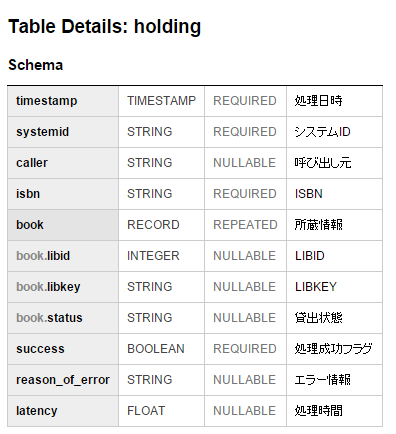
HOLDING_SCHEMA = [{"name": "timestamp", "type": "TIMESTAMP", "description": u"処理日時", "mode": "REQUIRED"},
{"name": "systemid", "type": "STRING", "description": u"システムID", "mode": "REQUIRED"},
{"name": "caller", "type": "STRING", "description": u"呼び出し元", "mode": 'nullable'},
{"name": "isbn", "type": "STRING", "description": u"ISBN", "mode": "REQUIRED"},
{"name": "book", "type": "RECORD", "description": u"所蔵情報", "fields": [
{"name": "libid", "type": "INTEGER", "description": u"LIBID", 'mode': 'nullable'},
{"name": "libkey", "type": "STRING", "description": u"LIBKEY", 'mode': 'nullable'},
{"name": "status", "type": "STRING", "description": u"貸出状態", 'mode': 'nullable'},
], "mode": "repeated"},
{"name": "success", "type": "BOOLEAN", "description": u"処理成功フラグ", 'mode': 'REQUIRED'},
{"name": "reason_of_error", "type": "STRING", "description": u"エラー情報", 'mode': 'nullable'},
{"name": "latency", "type": "FLOAT", "description": u"処理時間", 'mode': 'nullable'}]
{"reason_of_error": null, "latency": 2.0176000595092773, "book": [{"status": "\u8cb8\u51fa\u53ef", "libid": "103405", "libkey": "\u4e2d\u592e"}, {"status": "\u8cb8\u51fa\u4e2d", "libid": "103418", "libkey": "\u6771\u6d66\u548c"}, {"status": "\u8cb8\u51fa\u53ef", "libid": "103412", "libkey": "\u5927\u5bae\u897f\u90e8"}, {"status": "\u8cb8\u51fa\u53ef", "libid": "103406", "libkey": "\u5317\u56f3\u66f8\u9928"}, {"status": "\u8cb8\u51fa\u53ef", "libid": "103413", "libkey": "\u5bae\u539f"}], "systemid": "Saitama_Saitama", "success": "true", "isbn": "4796683550", "timestamp": "2015-09-05 02:53:51", "caller": "API:0"}
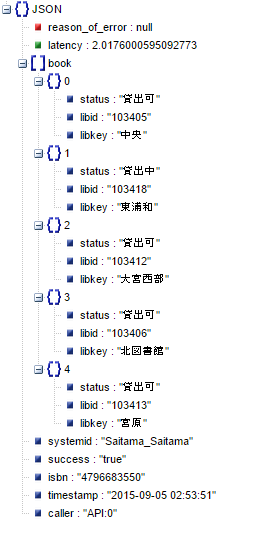
1件あたりのログデータ
api.calil.jp
Task worker
Task worker
Task worker
Task worker
Google Big Query
スクレイピングサーバーの
ログデータを集約
JSON (newline-delimited)

ファイルをGCEにアップロードして、Big Queryにロード
Unusual Holding / 異常な所蔵率変化の検出例
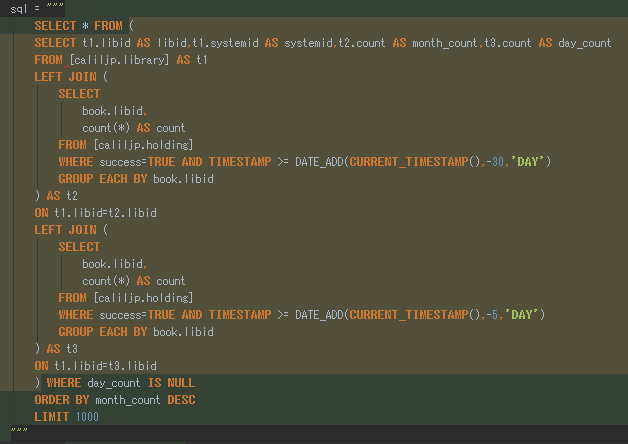
多摩ラストワンプロジェクト
NDL
NII
180万タイトル
30館
カーリルAPI
OPAC
2015年1月~3月
5400万回、カーリルAPIを叩く
NDL OAI-PMH → JSONに変換
4カ月 → 4週間くらいになったらしい
NII OpenSearch → JSONに変換
↓
遊んでみたい人は
データセット共有できます
SELECT * FROM (
SELECT
IFNULL(ndl.isbn ,nii.nii_isbn) AS isbn ,
IFNULL(ndl.title ,nii.nii_title) AS title ,
IFNULL(ndl.creater ,nii.nii_creater) AS creater,
IFNULL(ndl.publisher ,nii.nii_publisher) AS publisher ,
LEFT(IFNULL(ndl.date ,nii.nii_date),4) AS date ,
ndl.isbn_count AS ndl_isbn_count,
nii.nii_isbn_count AS nii_isbn_count,
ndl.owner_count AS ndl_owner_count
FROM [caliljp.ndlbook] ndl
LEFT OUTER JOIN EACH (
SELECT isbn as nii_isbn,
title as nii_title,
creater as nii_creater,
publisher as nii_publisher,
owner_count as nii_owner_count,
isbn_count as nii_isbn_count,
date as nii_date FROM [caliljp.niibook]
) AS nii ON ndl.isbn=nii.nii_isbn
) WHERE (REGEXP_MATCH(isbn,'^4'))
多摩集約
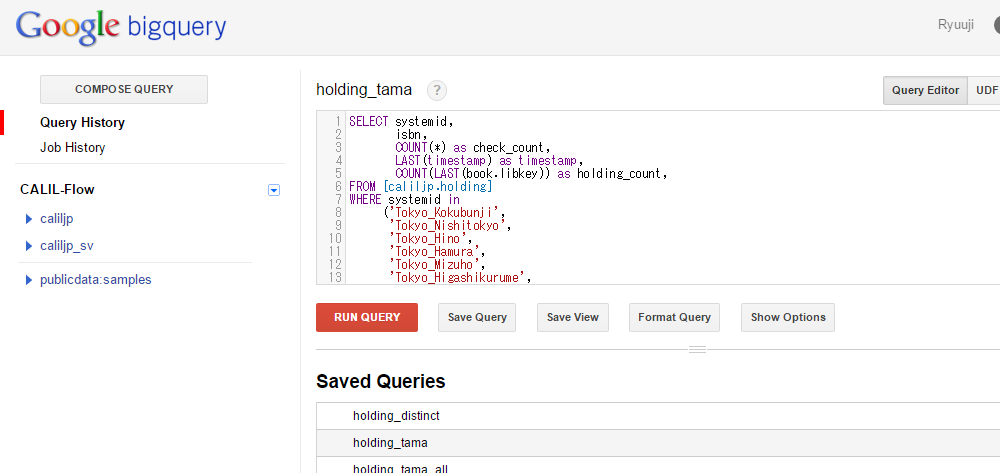
SELECT systemid,
isbn,
LAST(timestamp) as timestamp,
(LAST(book.libkey) IS NOT NULL) as is_holding,
FROM [caliljp.holding]
WHERE systemid in
('Tokyo_Kokubunji',
'Tokyo_Nishitokyo',
'Tokyo_Hino',
'Tokyo_Hamura',
'Tokyo_Mizuho',
'Tokyo_Higashikurume',
'Tokyo_Tachikawa',
'Tokyo_Okutama',
'Tokyo_Fussa',
'Tokyo_Ome',
'Tokyo_Kodaira',
'Tokyo_Kiyose',
'Tokyo_Chofu',
'Tokyo_Hachioji',
'Tokyo_Musashino',
'Tokyo_Koganei',
'Tokyo_Akishima',
'Tokyo_Tama',
'Tokyo_Fuchu',
'Tokyo_Inagi',
'Tokyo_Komae',
'Tokyo_Hinode',
'Tokyo_Mitaka',
'Tokyo_Akiruno',
'Tokyo_Machida',
'Tokyo_Kunitachi',
'Tokyo_Higashiyamato',
'Tokyo_Higashimurayama',
'Tokyo_Musashimurayama') AND success=true
GROUP EACH BY systemid,isbn;
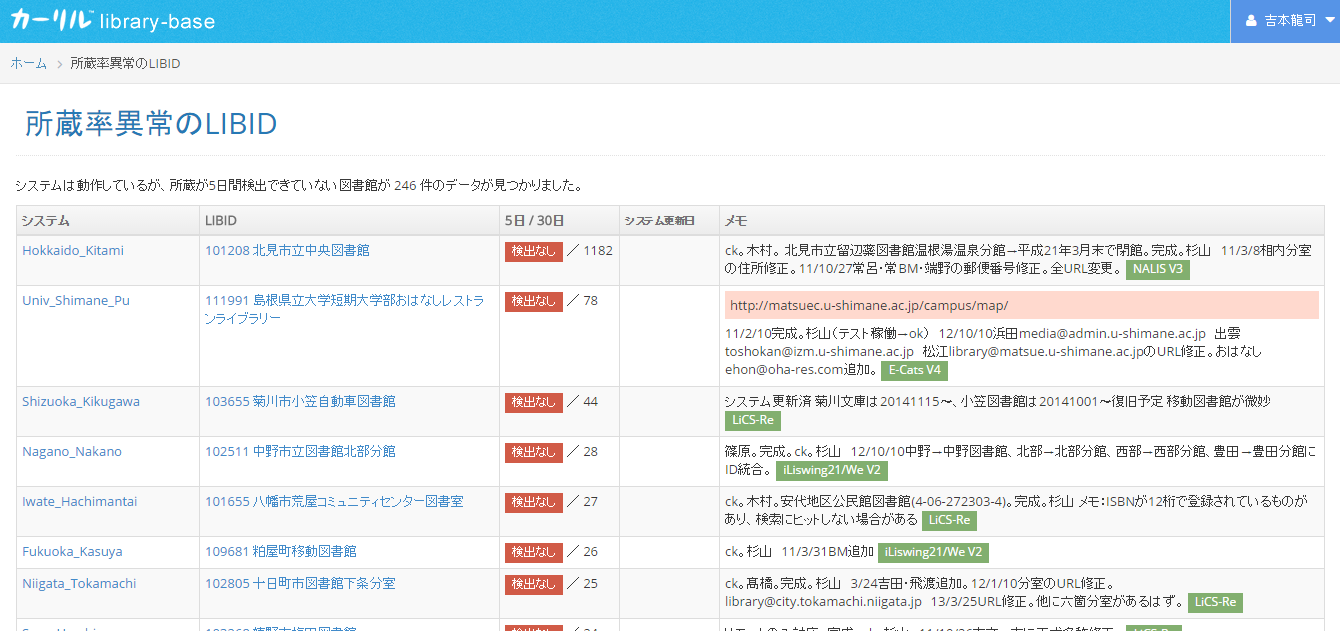
26館以上のデータが取れていて、1館以上で所蔵されているタイトルを、所蔵図書館数ごとに集計
SELECT sum,count(*) as titles,sum*count(*) as books FROM
(
SELECT isbn,count(*) as count,sum(is_holding) as sum FROM [caliljp.holding_tama_distinct] GROUP BY isbn
) where count>=26 and sum>=1 group by sum order by sum
Text
Text
Text
所蔵自治体数ごとの集計
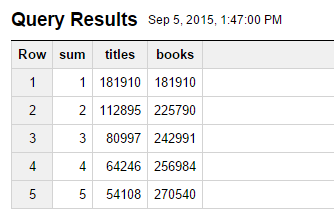
おまけ1 最速OPAC
SELECT * FROM (
SELECT systemid,AVG(latency) FROM [caliljp.holding] where success=true and timestamp>='2015-06-01 00:00:00' group by systemid order by f0_
) as t1
LEFT JOIN [caliljp.system] as t2
ON t1.systemid=t2.systemid
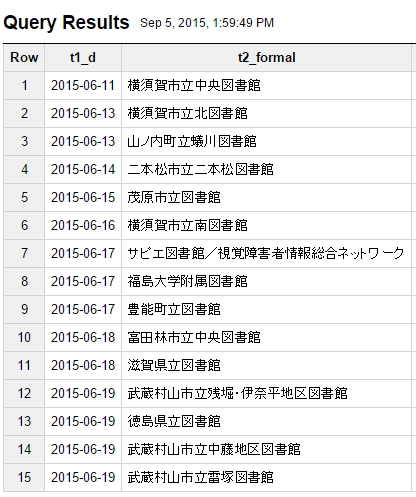
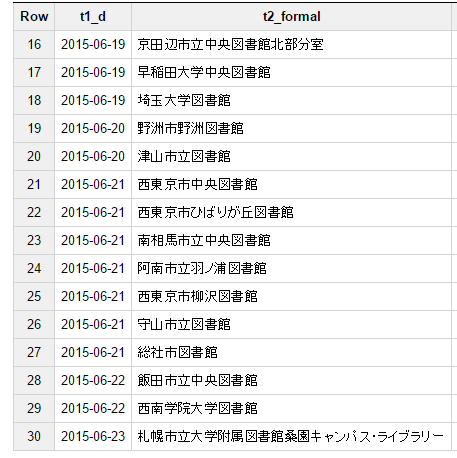
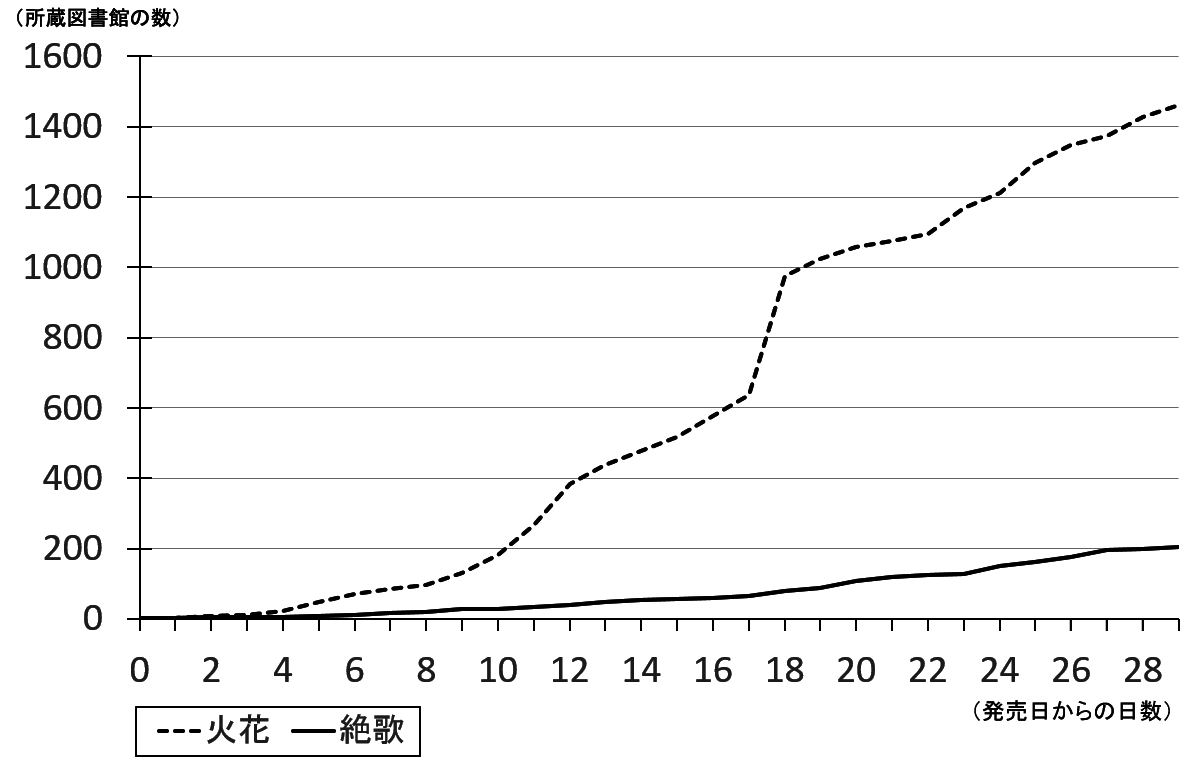
おまけ2 絶歌所蔵図書館の推移
SELECT t1.d,t2.formal FROM
(SELECT book.libid,DATE(min(timestamp)) as d from [caliljp.holding] where isbn='4778314506' and book.libid is not NULL group by book.libid order by d)
AS t1
LEFT JOIN [caliljp.library] as t2 on t1.libid=t2.libid
ありがとうございました
図書館の大規模データ分析にGoogle Big Queryを使ってみよう
By Ryuuji Yoshimoto
図書館の大規模データ分析にGoogle Big Queryを使ってみよう
Code4Lib 2015 in Tokyo




