

Sam Mangham
Senior Research Software Engineer @ University of Southampton
Hussey, 2023
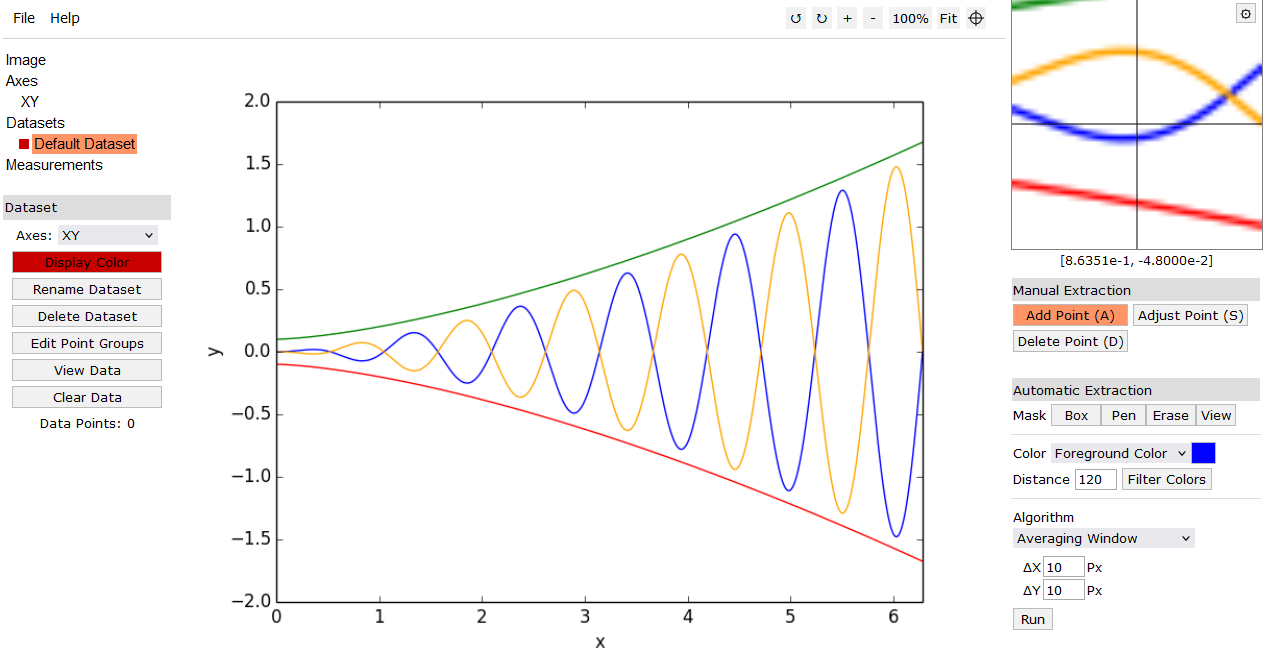
Web Plot Digitiser, 2024
s/Data/Code/gLetter to the Editor: Comment on Editorial on Software Distribution in Science, John Figueras
Good enough practises in scientific computing, Wilson 2017
https://doi.org/10.1371/journal.pcbi.1005510
Findable: (Meta)data should be easy to find for both humans and computers
Accessible: Once the user finds the required data, they need to know how they can be accessed, including authentication and authorisation
Interoperable: (Meta)data needs to be interoperable with applications or workflows for analysis, storage, and processing
Reusable: (Meta)data should be well-described so it can be replicated and/or combined in different settings
Findable: Software and its metadata are easily human- and machine-findable
Accessible: Software and its metadata can be accessed via standard protocols
Interoperable: Software must exchange (meta)data using APIs described by standards
Reusable: Software can be run, and can be understood, modified and extended
analyse_pt1234.py)Software, and its associated metadata, is easy for both humans and machines to find
citation.cff filecitation.cff/ codemeta.json file / on a software registry Software, and its metadata, is retrievable via standardised protocols
stdout
Software interoperates with other software by exchanging data and/or metadata, and/or through interaction via applicationprogramming interfaces (APIs), described through standards.
Software is both usable (can be executed) and reusable (can be understood, modified, built upon, or incorporated into other
software)
license.mdrequirements.txt)By Sam Mangham
Slides for friday morning talk about FAIR for Research Software.




