Convex Learning
Outline
- Convex Learning Problem
- Useful Properties
- Learnability
- Surrogate Loss Function
- Regularization and Stability
- Regularized Loss Minimization
- Fitting-Stability Tradeoff
- Stochastic Gradient Descent
- Learning with SGD
In fact, we know it
- Linear regression with square loss
- Logistic regression
l(w, (x, y)) = {\log{\left(1+e^{-y\langle w, x\rangle} \right)}}
Convex set
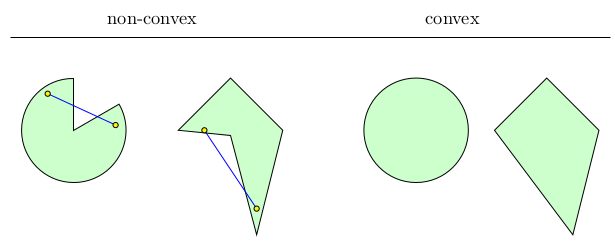
\forall u,v \in C,\,\forall \alpha \in \left[ 0,1 \right],\,\alpha u+(1-\alpha)v \in C
Convex function
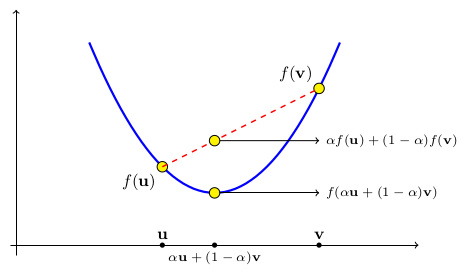
f:C\rightarrow \mathbb{R}\quad\forall u,v \in C,\,\forall \alpha \in \left[ 0,1 \right]
f\left( \alpha u+(1-\alpha)v \right) \leq \alpha f(u) + (1-\alpha)f(v)
First Order Property
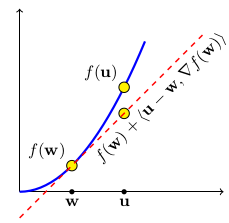
\forall u,v \in dom(f)
\, f(u) \geq f(w) + \langle\nabla f(w),\, w-v\rangle
Second order Property
For function f with f' and f'' exists, TFAE
- f is convex
- f' is monotonically increasing
- f'' is nonegative
Examples
f(x) = x^{2}\Rightarrow f^{\prime\prime}(x) = 2
f(x) = \log\left(1+e^{x} \right)\Rightarrow f^{\prime\prime}(x) =\frac{e^{-x}}{(1+e^{-x})^{2}}
l(w, (x, y)) = {\log{\left(1+e^{-y\langle w, x\rangle} \right)}}???
Linear transformation preserves convexity
f(w) =g(\langle w,\,x\rangle+y)
is convex when
g(x)
is convex
g(x) = \log\left(1+e^{x} \right)
l(w, (x, y)) =g(-y\langle w,\,x\rangle) =g(\langle w,\,-yx\rangle))={\log{\left(1+e^{-y\langle w, x\rangle} \right)}}
is convex and so is
f(w)=(\langle w,\,x\rangle-y)^{2}
is convex
Obviously,
Other functions preserve convexity
g(x) = \max\limits_{i \in [r]}{f_{i}(x)}
g(x) = \sum\limits_{i=1}^{r}{w_{i}f_{i}(x)}
Logistic loss is convex
l(w, (x, y)) = \frac{1}{m}\sum\limits_{i=1}^{m}{\log{\left(1+e^{-y_{i}\langle w, x_{i}\rangle} \right)}}
Proofs
Lipschitzness
\forall w_{1},w_{2}\in C
\lVert f(w_{1})-f(w_{2})\rVert \leq \rho \lVert w_{1}-w_{2}\rVert
Lipschitzness
\forall x \in dom(f),\,f^{\prime}(x)\leq \rho
For a differentiable function f, it is -lipschitz if and only if
in 1-D case
\rho
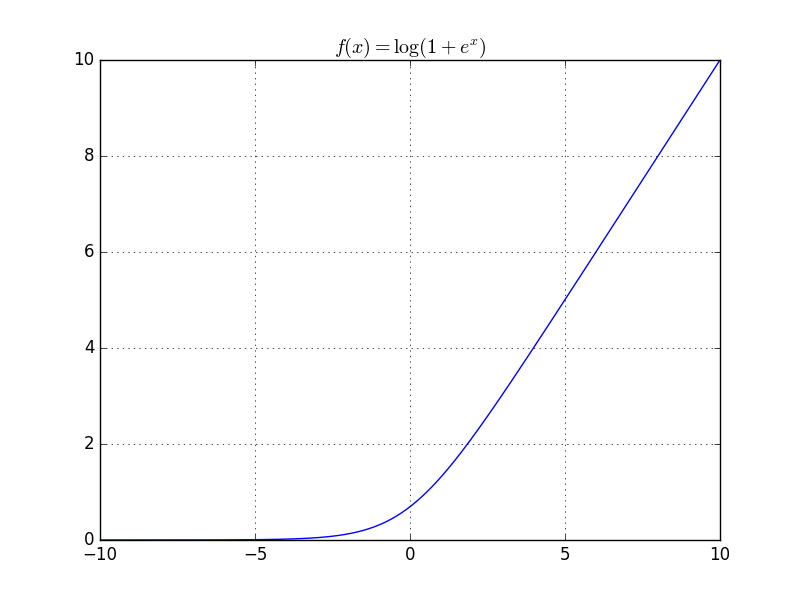
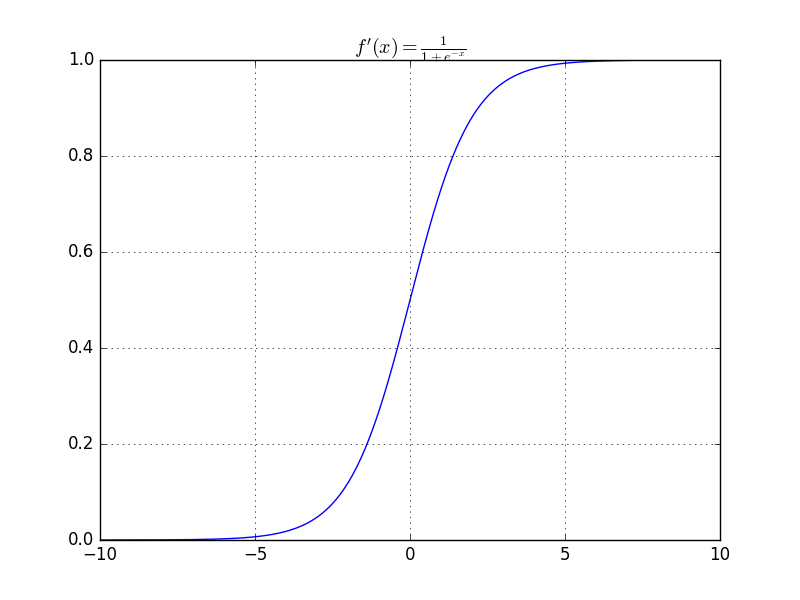
f(x) = \log\left(1+e^{x} \right)
is 1-Lipschitz
Bounded by [-1, 1]
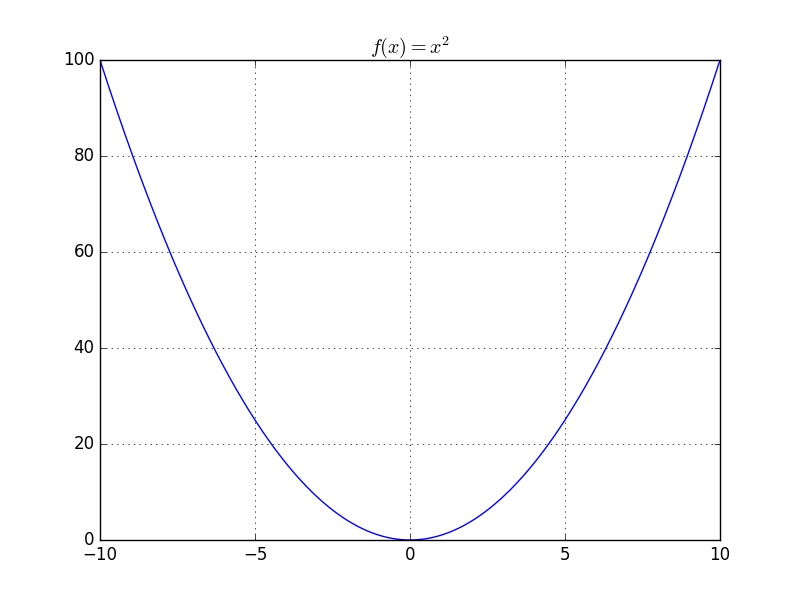
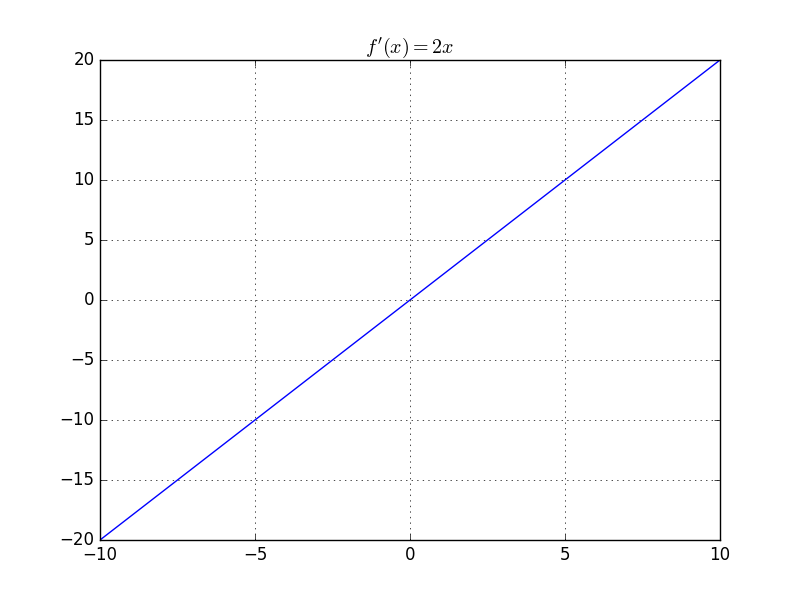
f(x) = x^{2}
is not Lipschitz
Unbounded above!
Smoothness
A function is called -smooth when its derivative is -lipschitz
\beta
\beta
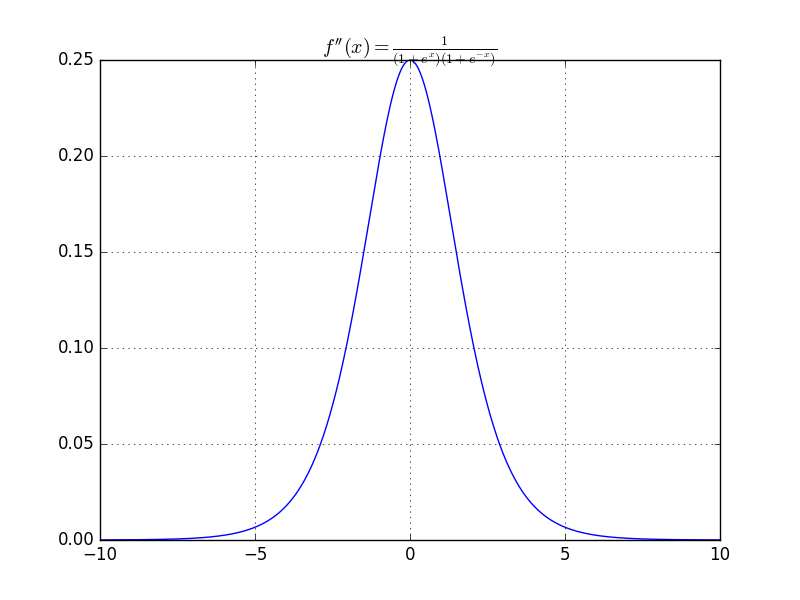
f(x) = \log\left(1+e^{x} \right)
is 1/4-smooth
Bounded by [-1/4, 1/4]
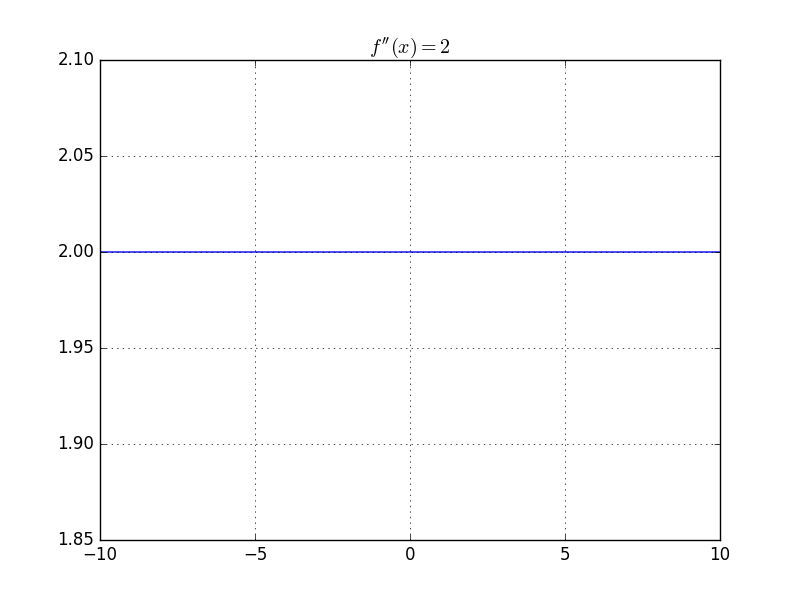
f(x) = x^{2}
is 2-smooth
bounded by [-2,2]
Property of smoothness
f(v ) \leq f(w) +\langle \nabla f(w), v-w \rangle + \frac{\beta}{2}\lVert v-w \rVert^{2}
f^{\prime}(v)
f^{\prime}(v)+\beta\lVert v-w\rVert
f^{\prime}(v)-\beta\lVert v-w\rVert
v
w
Self-bounded
f(v ) \leq f(w) +\langle \nabla f(w), v-w \rangle + \frac{\beta}{2}\lVert v-w \rVert^{2}
\lVert \nabla f(w) \rVert \leq 2\beta f(w)
When f is non-negative and smooth we can obtain
by setting
f(v ) = f(w) - \frac{1}{\beta}\nabla f(w)
in
Lipschitzness and smoothness under linear transformation
f(w) =g(\langle w,\,x\rangle+y)
is -lipschitz then
g(x)
\rho
is -lipschitz
\rho \lVert x \rVert
f(w) =g(\langle w,\,x\rangle+y)
is -smooth then
g(x)
\beta
is -smooth
\beta \lVert x \rVert^{2}
Examples
l(w, (x, y)) = {\log{\left(1+e^{-y\langle w, x\rangle} \right)}}
-lipschitz and -smooth
\lVert x \rVert
\frac{\lVert x \rVert^{2}}{4}
Since
y \in \{1,-1\},
\,-y\langle w,x\rangle=\langle w,-yx\rangle, \,\lVert -yx\rVert^{2}=\lVert x\rVert^{2}
Examples
l(w, (x, y)) = \left( \langle w, x\rangle - y \right)^{2}
-smooth
2\lVert x \rVert^{2}
Boundness of training set
In previous arguement, we have the form like -smooth
But x is a variable, so we also need x to be bounded :
So that we can say a loss function is -smooth
\lVert x \rVert^{2} \leq B
K\lVert x \rVert^{2}
KB
Proofs
Convex learning problem
A learning problem with
- convex set H
- loss function convex in h
l(h,z)
So linear regression and logistic regression are convex learning problems
Convex learning problem and convex optimization problem
When we apply ERM rule to a convex learning problem, we are finding the minimum of convex function
ERM_{H}(S) = \arg\min\limits_{w \in H} L_{S}(w)
which is equivalent to solving a convex optimization problem
Learnability of convex learning problems
Two kinds of convex learning problems are learnable :
- Convex-Lipschitz-Bounded problem
- Convex-Smooth-Bounded problem
Convex learning problem is not learnable in general
Example 12.8
(\mu,-1)
\frac{1}{2}
(1,0)
\frac{1}{2\mu}
D_1
D_2
prob
(1,0)
(\mu,-1)
\mu
1-\mu
0
1
\mu = \frac{\log(\frac{100}{99})}{2m}
y=-\frac{1}{2\mu}x
y
x
Example 12.8
(\mu,-1)
(1,0)
\frac{1}{2\mu}
y=\hat{w}x
(\mu,-1)
\frac{1}{2}
y=-\frac{1}{2\mu}x
y
x
y=\hat{w}x
D_1
D_2
y=-\frac{1}{2\mu}x
Example 12.9
(1,-1)
\frac{1}{2}
(\frac{1}{\mu},0)
\frac{1}{2\mu}
D_1
D_2
prob
(\frac{1}{\mu},0)
(1,-1)
\mu
1-\mu
0
1
\mu = \frac{\log(\frac{100}{99})}{2m}
y=-\frac{1}{2}x
y
x
Example 12.9
(1,-1)
\frac{1}{2}
(\frac{1}{\mu},0)
\frac{1}{2\mu}
y=-\frac{1}{2}x
y
x
y=-x
(1,-1)
\frac{1}{2}
y
y=-\frac{1}{2}x
x
y=x
D_1
D_2
y=\hat{w}x
y=\hat{w}x
Surrogate Loss Function
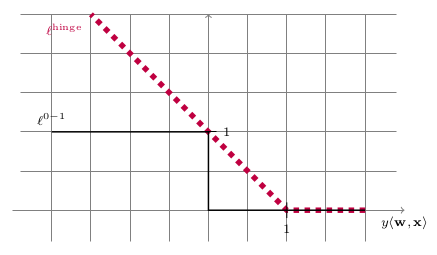
Surrogate Loss Function
L_{D}^{0-1}(A(S))\leq L^{hinge}_{D}(A(S))\leq\min\limits_{w \in H}L_{D}^{hinge}(w)+\epsilon
=\min\limits_{w \in H}L_{D}^{0-1}(w)+\left( \min\limits_{w\in H}L_{D}^{hinge}(w)-\min\limits_{w\in H}L_{D}^{0-1}(w) \right) + \epsilon
\epsilon_{approximation}
\epsilon_{estimation}
\epsilon_{optimization}
Regularization and Stability
- Regularized Loss Minimization
- Stability and Overfitting
- Proof of Learnability
- Convex-Lipschitz-Bounded problem
- Convex-Smooth-Bounded problem
RLM learning rule
A(S)=\arg\min\limits_w (L_{S}(w)+R(w))
A(S)=\arg\min\limits_w (L_{S}(w)+\lambda \lVert w\rVert^{2})
Tikhonov Regularization
Ridge Regression
\arg\min\limits_{w\in \mathbb{R}^{d}} \left(\lambda \lVert w\rVert_{2}^{2}+\frac{1}{m}\sum\limits_{i=1}^{m}\frac{1}{2}(\langle w, x_{i}-y_{i}\rangle)^{2}\right)
(2\lambda mI+A)w=b
w=(2\lambda mI+A)^{-1}b
A=\sum\limits_{i=1}^{m}x_{i}x_{i}^{\intercal}
Stability
S = (z_{1},...,z_{m})
S^{(i)} = (z_{1},...,z_{i-1},z^{\prime},z_{i+1},...,z_{m})
?\geq l(A(S^{(i)}),z_{i})-l(A(S),z_{i})\geq0
Stability and Overfitting

Replace-One-Stable

Strong Convex
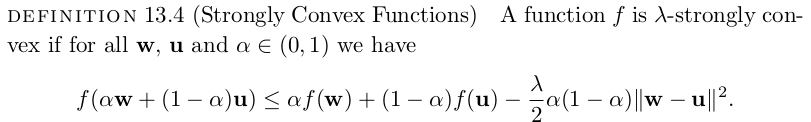
Strong Convex
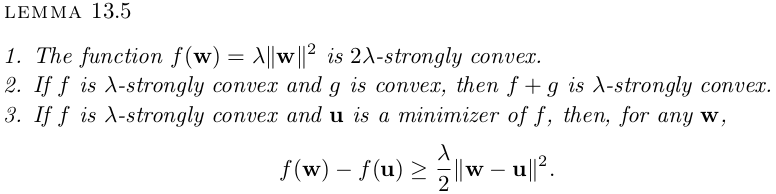
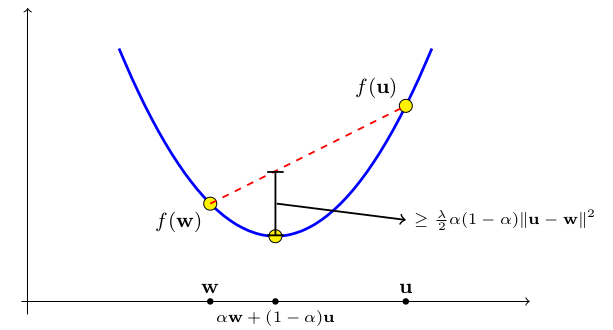
A(S)=\arg\min\limits_w (L_{S}(w)+\lambda \lVert w\rVert^{2})
Strong convex
Replace-One-Stable

Author abuse the fact that the loss function is strong convex in this proof
RLM Stability-Fitting Tradeoff
Lipschitzness would help
Stochastic Gradient Descent
- Gradient Descent to SGD
- Learning with SGD
- Comparison of SGD and RLM
- Appliction of SGD
Gradient Descent
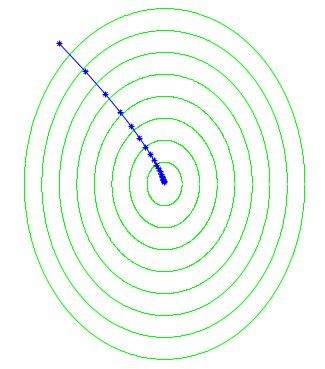
f(\bar{w})=f(\frac{1}{T}\sum\limits_{t=1}^{T}w^{(t)})
w^{(t+1)}=w^{(t)}-\eta\nabla f(w^{(t)})
f(\bar{w})=f(w^{(T)})
Importance of Lipschitzness and Smoothness
f^{\prime}(x)\leq \rho
\lVert f^{\prime}(x) \rVert \leq 2\beta f(x)
Lipschitzness
Self-bounded(Smoothness)
Gradient Descent
Gradient Descent
Stochastic Gradient Descent

Stochastic Gradient Descent
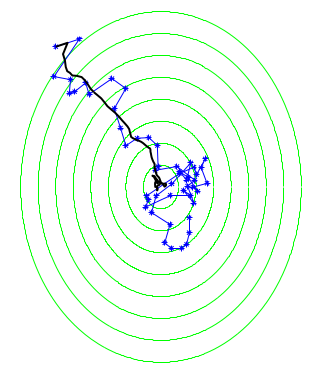
f(\bar{w})-f(w^{*})\leq \epsilon
T \geq \frac{B^{2}\rho^{2}}{\epsilon^{2}}
same as GD
What if we go out of boundary?
What if we have strong convexity?
SGD Learning
We directly minimize the true risk with an unbiased estimate of its gradient
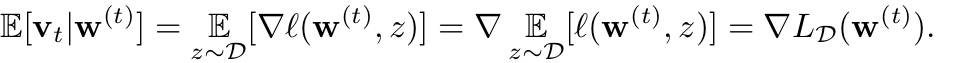
Followed by SGD method we can obtain the result we want
Comparison
\mathbb{E}_{S}[L_{D}(A(S))]\leq \min\limits_{w\in H}L_{D}(w)+\epsilon
convex-Lipschitz-bounded
convex-Smooth-bounded
\frac{8\rho^{2}B^{2}}{\epsilon^{2}}
\frac{150\beta B^{2}}{\epsilon^{2}}
\frac{12\beta B^{2}}{\epsilon^{2}}
\frac{\rho^{2}B^{2}}{\epsilon^{2}}
| samples / Iterations | RLM | SGD |
|---|---|---|
|
|
||
|
|
Learning
Rule
Specific
Algorithm
Application
When training DNN, SGD is the most common algorithm to train the NN model
- Hypothesis set is all possible neural network
- Implement SGD by batches of training data
- ERM rule apply to choose best DNN model
- Usually use square loss function
- In general, the loss function is not convex
SGD with Momentum
w^{(t+1)}=w^{(t)}-v^{(t)}
v^{(t+1)}=\gamma v^{(t)}+\eta\nabla f(w^{(t)})
In practice SGD is a successful method in training DNN
- SGD itself will introduce randomness
- SGD with momentum will avoid local minimum
- Local minimum is few in practical problem
Other Issue of SGD
- Properly selection of initial position
- Boosting the efficiency : RMSProp, adagrad
- Proper batch size selection
- Back propagation to evaluate gradient
convex learning
By 許泓崴



