





Sam Wu
Data Engineer/Software Engineer/DL Researcher
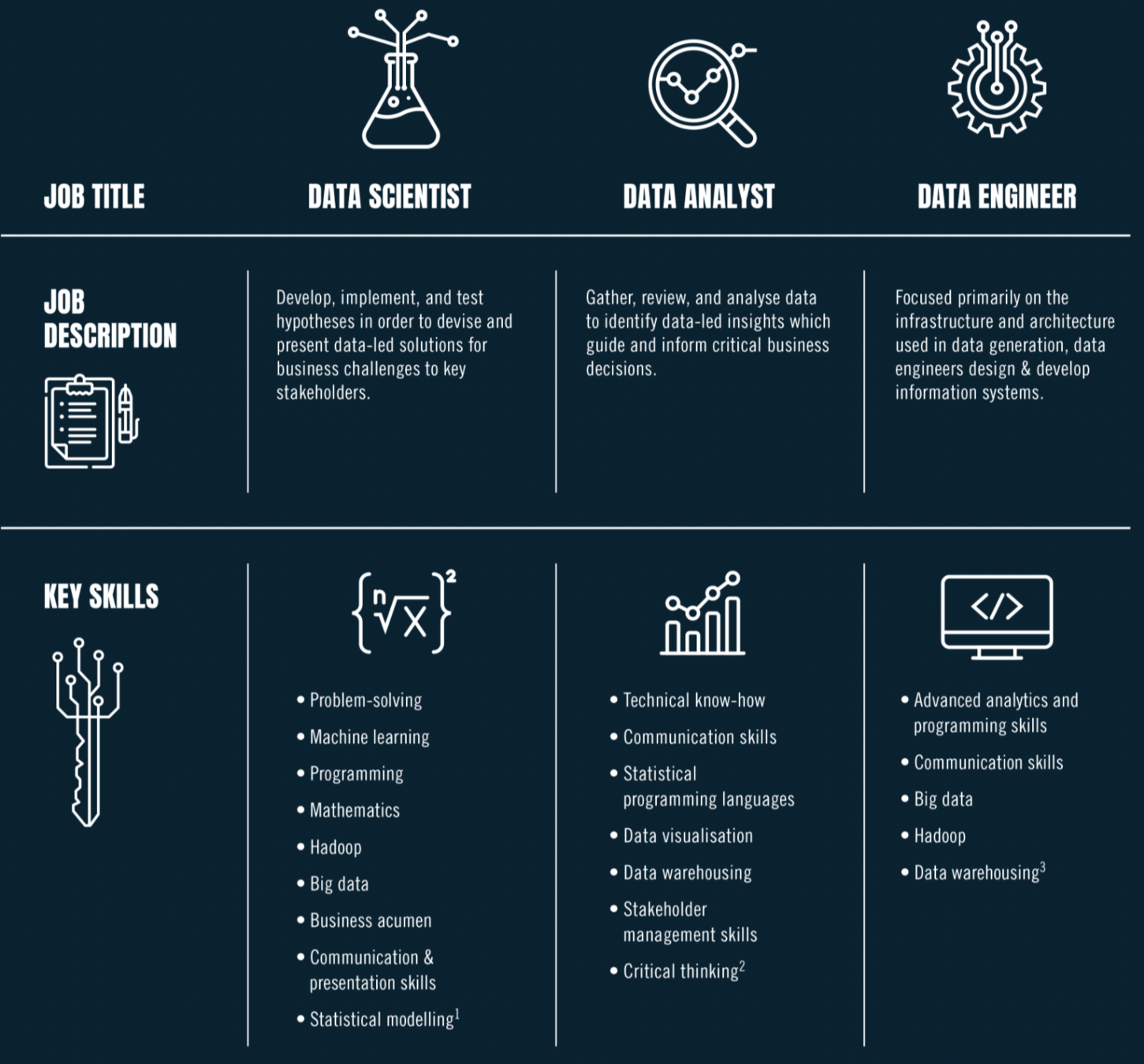
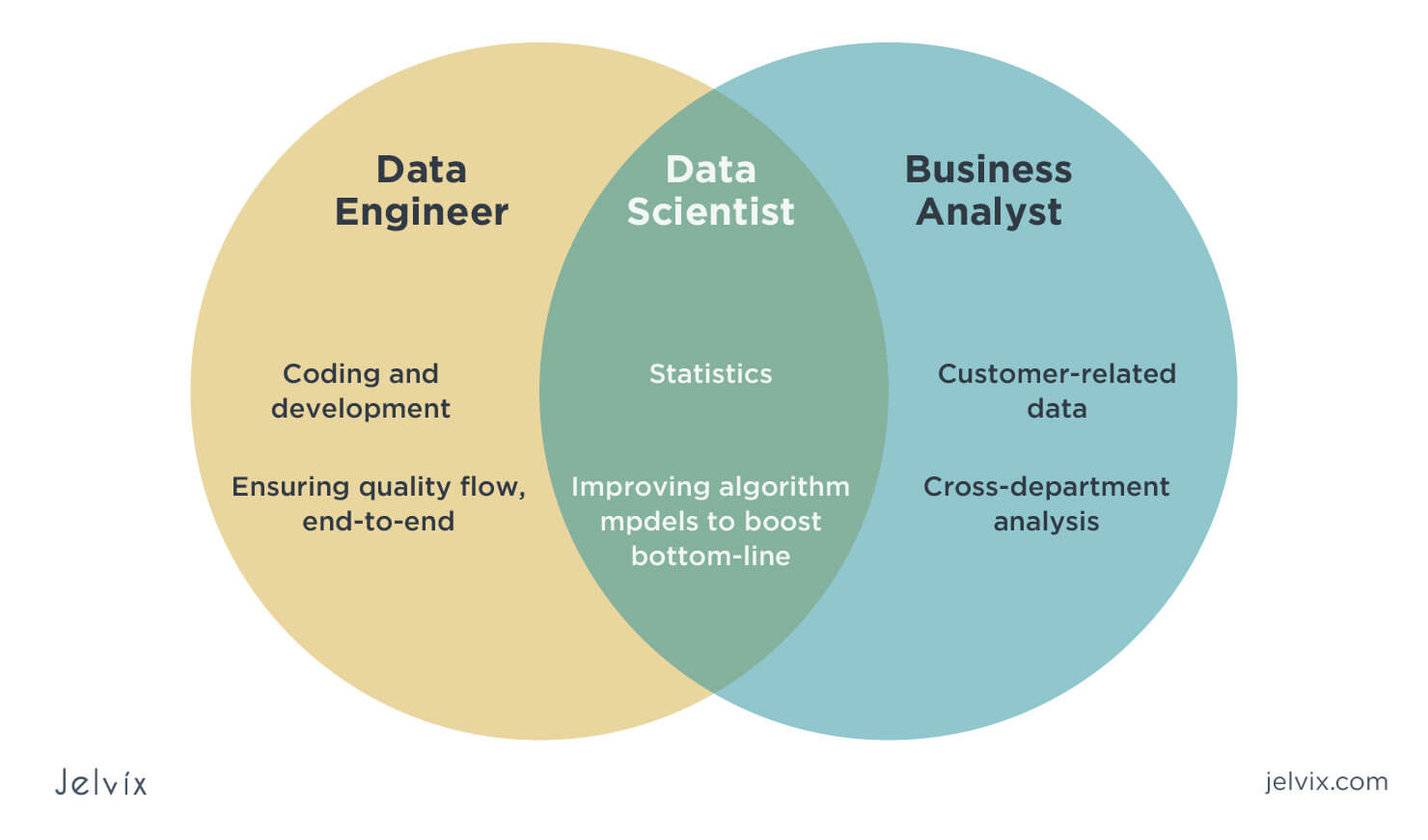
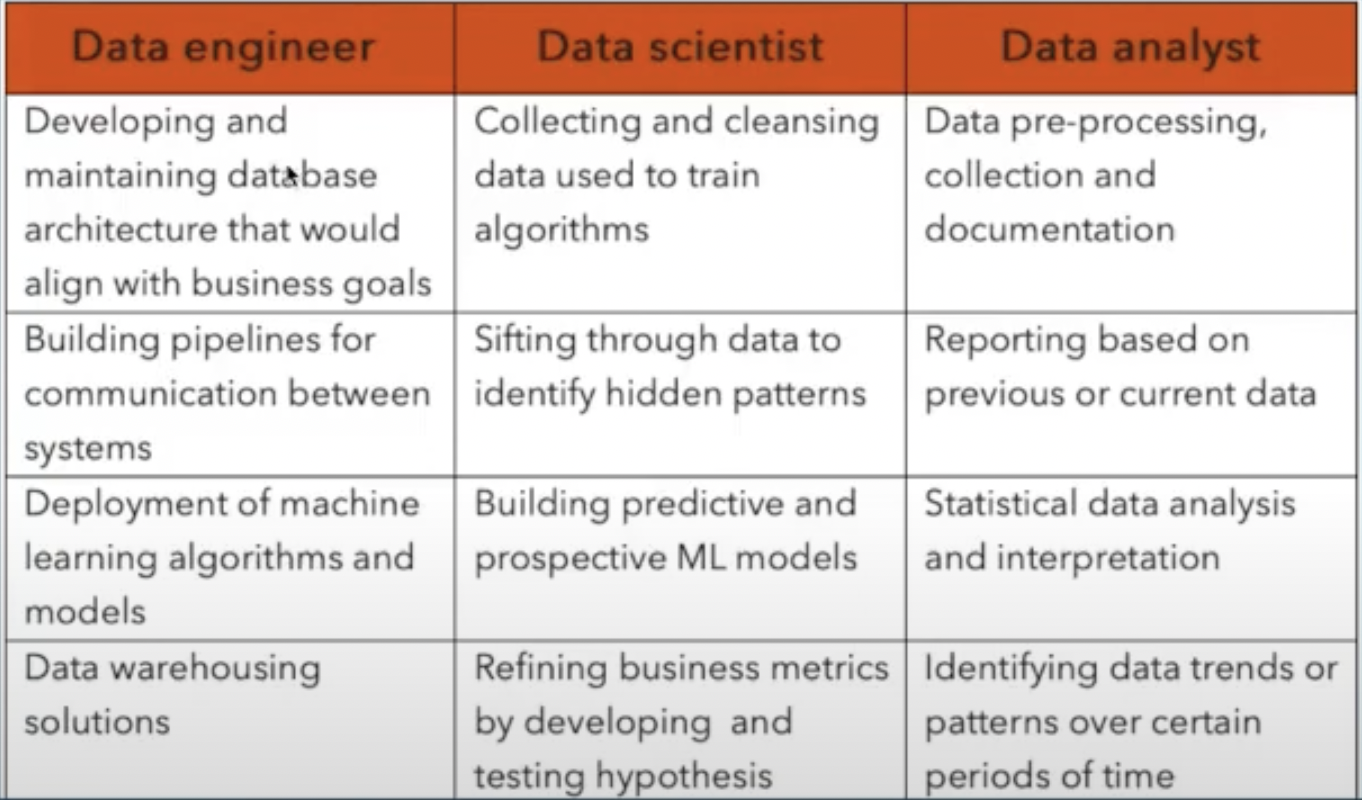
Difference of data scientist and data engineer
What a Data Engineer does?
In Taiwan regular company
Data Scientist
+
Data Analyst
+
Data Engineer
=
Data Scientist
JD from Taiwan's company
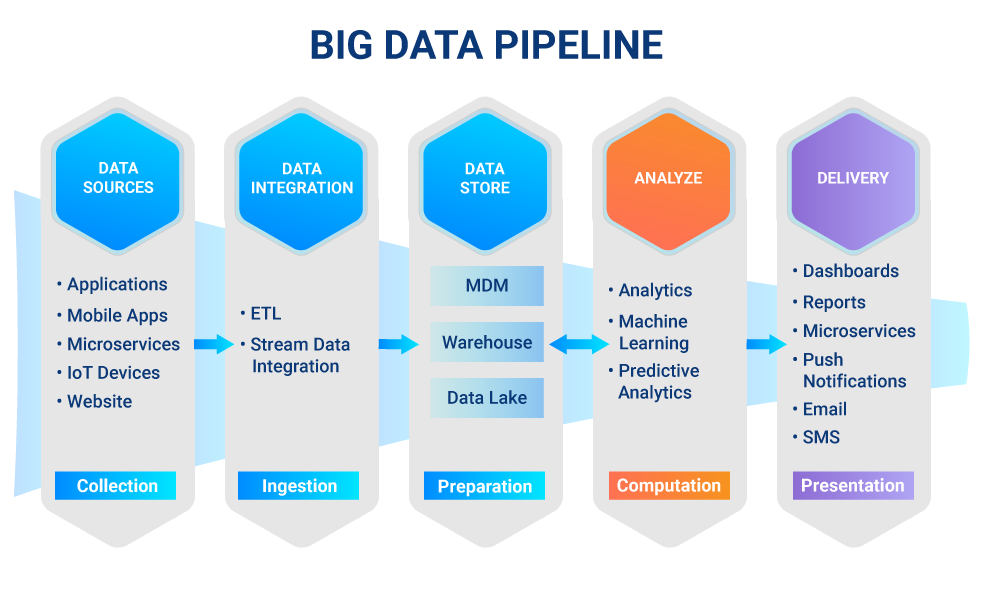
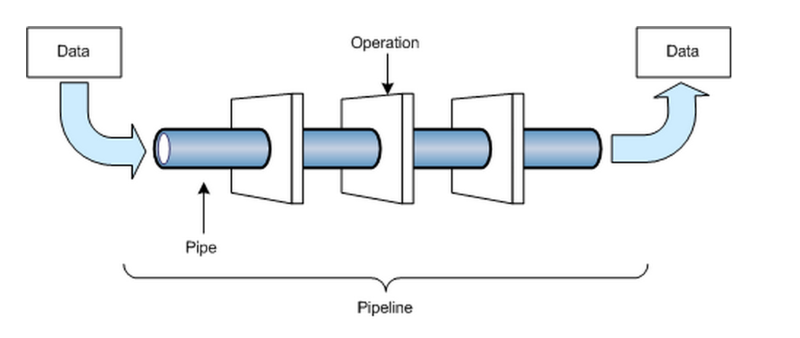
Series of data processes that extract, process and load data between different systems.
ETL is part of data pipeline, means Extract, Transform and Load.
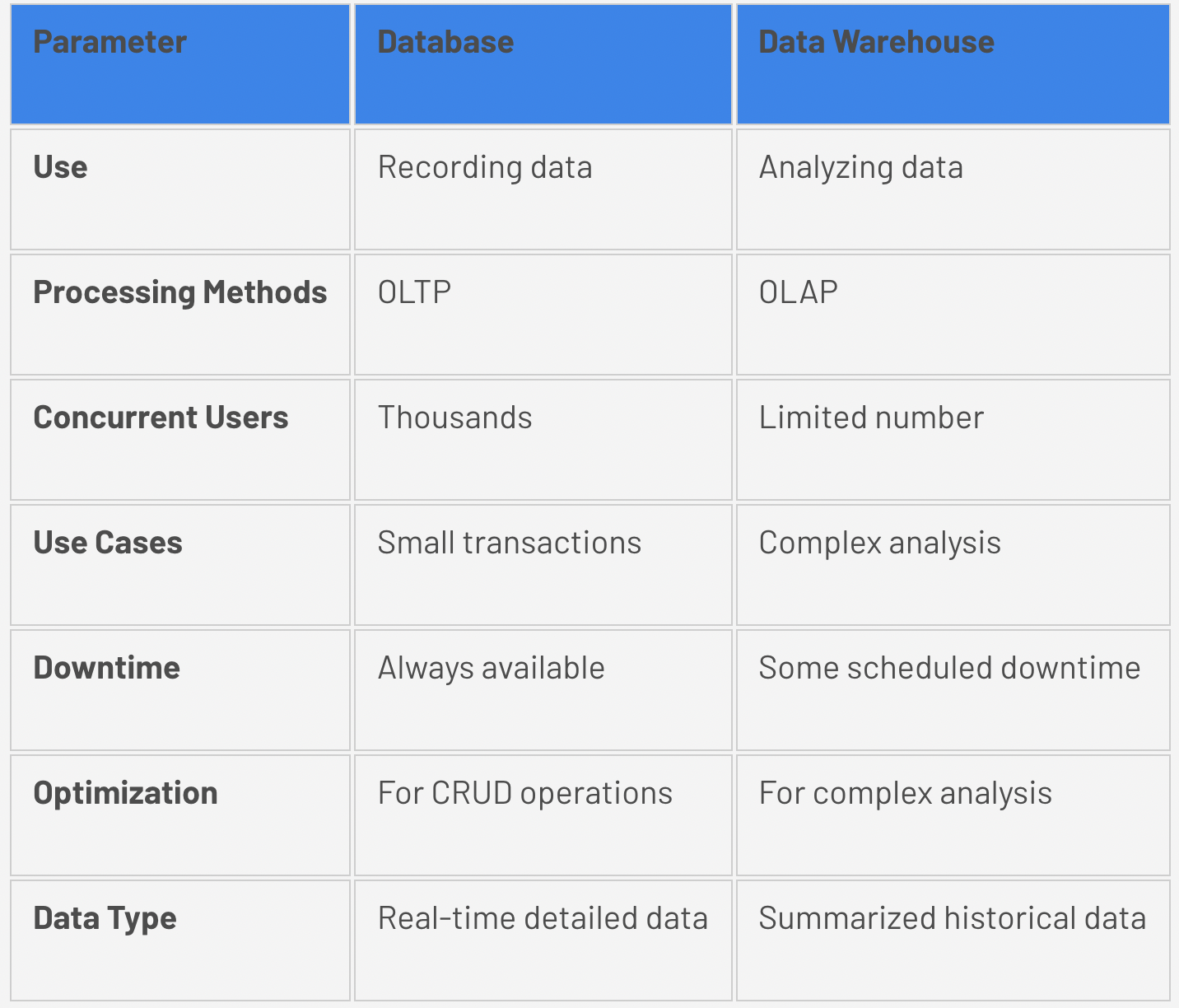
A data warehouse is a type of data management system that is designed to enable and support business intelligence (BI) activities, especially analytics. Data warehouses are solely intended to perform queries and analysis and often contain large amounts of historical data.
Google BigQuery + Google Data Studio
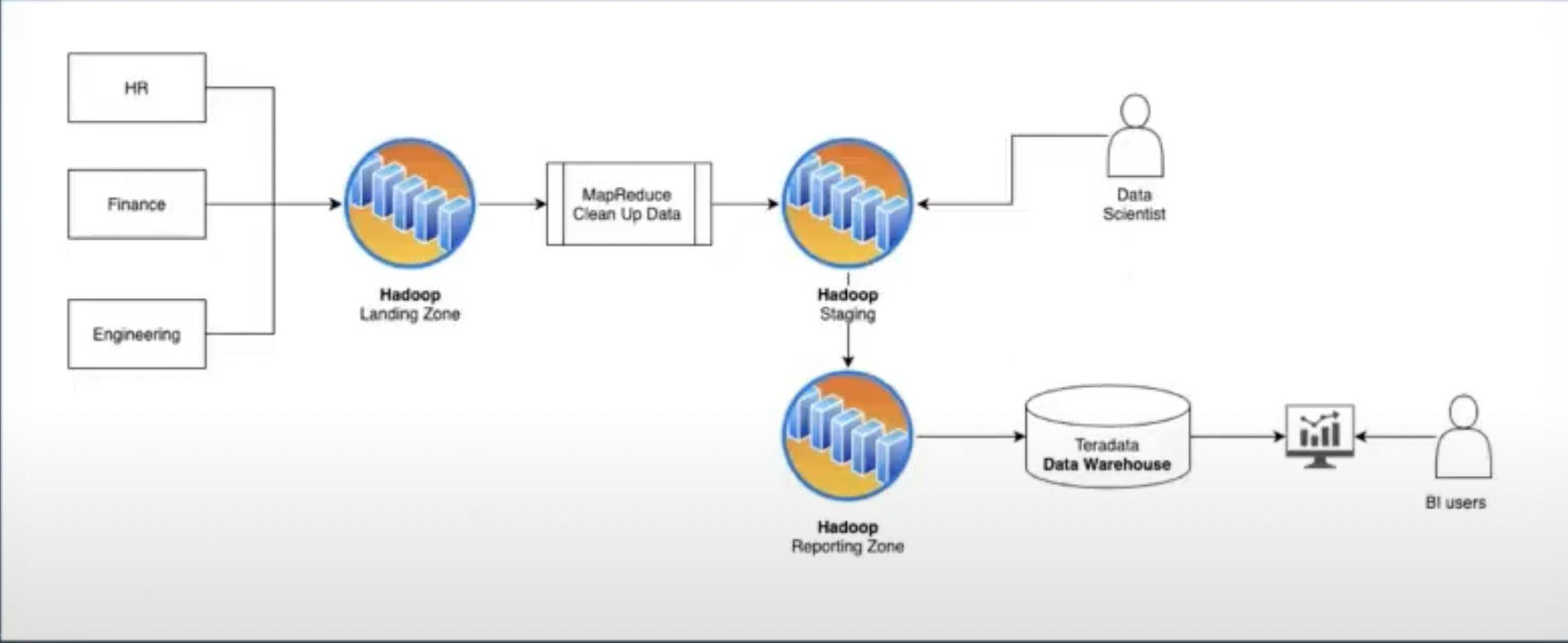
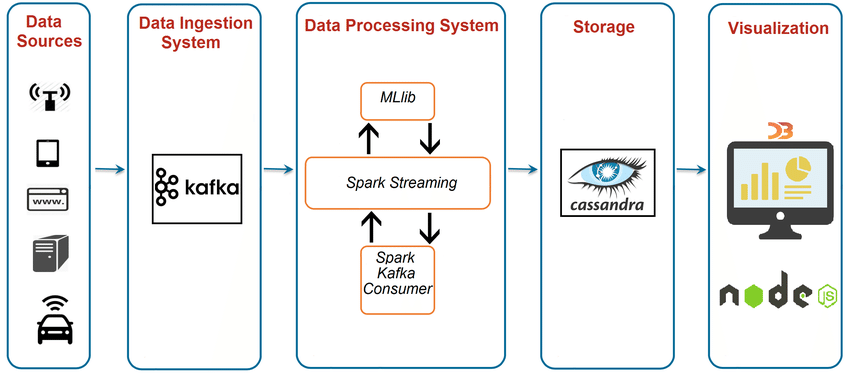
Data infrastructure of data platform:
The distributed systems that everything runs on top of.
Building internal data tools and APIs.
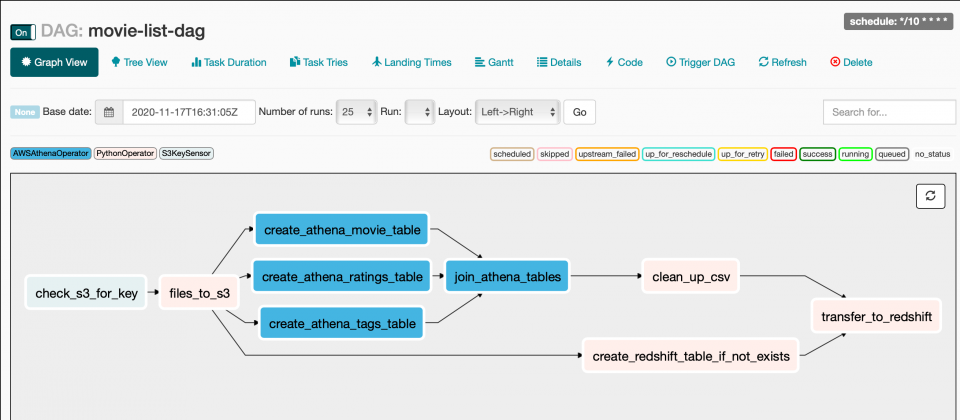
Apache Airflow is a platform to programmatically author, schedule, and monitor workflows.
When workflows are defined as code, they become maintainable, versionable, testable and collaborative.
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from datetime import datetime, timedelta
dag = DAG('tutorial', default_args=default_args, schedule_interval=timedelta(days=1))
# t1, t2 and t3 are examples of tasks created by instantiating operators
t1 = BashOperator(
task_id='print_date',
bash_command='date',
dag=dag)
t2 = BashOperator(
task_id='sleep',
bash_command='sleep 5',
retries=3,
dag=dag)
templated_command = """
{% for i in range(5) %}
echo "{{ ds }}"
echo "{{ macros.ds_add(ds, 7)}}"
echo "{{ params.my_param }}"
{% endfor %}
"""
t3 = BashOperator(
task_id='templated',
bash_command=templated_command,
params={'my_param': 'Parameter I passed in'},
dag=dag)
t2.set_upstream(t1)
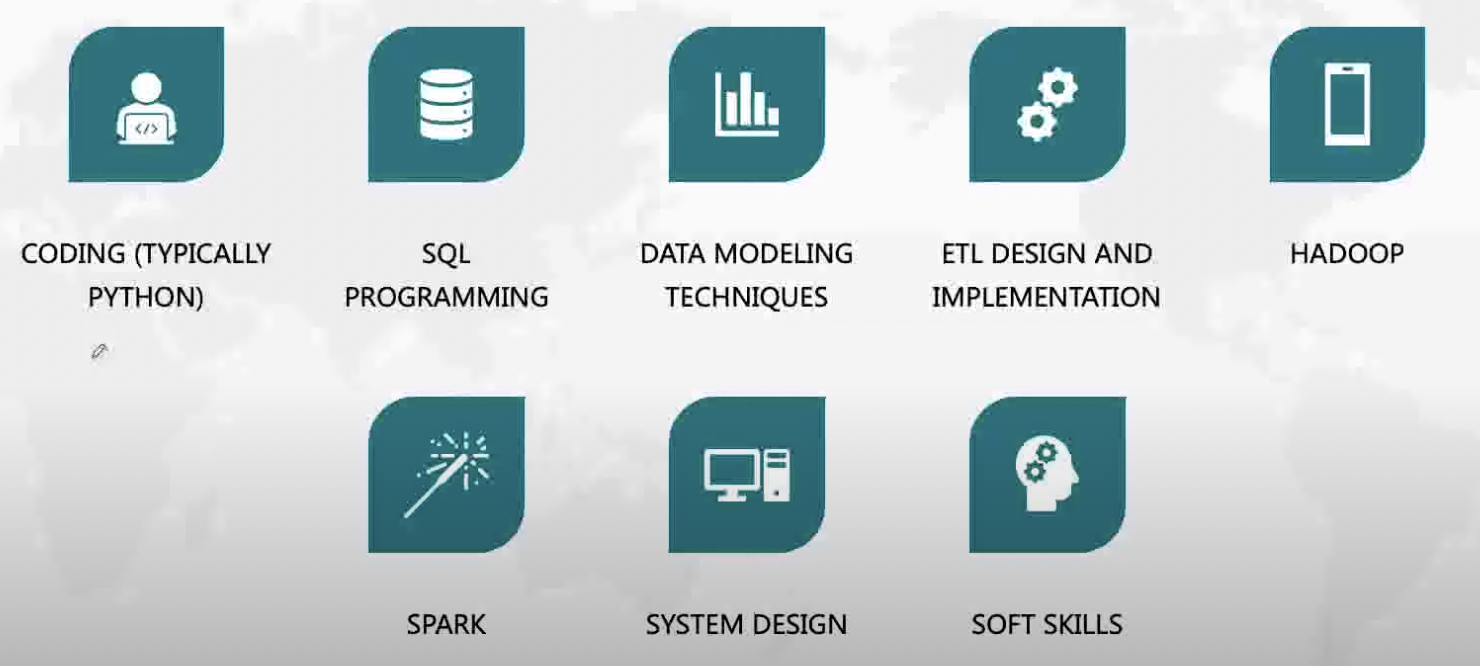
t3.set_upstream(t1)Facebook data engineer
Walmart data engineer
Overview
By Sam Wu

