DBSCAN 介紹
講者:ㄇㄒ
日期:2021/03/14
Outline
- 基本介紹
- 簡易實作
基本介紹
What is DBSCAN?
- 屬非監督式學習中的分群方式
- Density-based spatial clustering of applications with noise
- 基於密度的分群方式
- 將特徵相近且密度高的樣本劃分為一群
補充:分類 VS 分群
| 分類 | 分群 | |
|---|---|---|
| 演算法 | K-近鄰演算法 (KNN)、支持向量機 (SVM) … | Kmeans、DBSCAN … |
| 所屬機器學習方式 | 監督式學習 | 非監督式學習 |
| 資料標籤 | 有標籤 | 無標籤 |
| 標準答案 | 有正確答案 透過機器學習能分辨及預測 |
沒有給答案 機器需自行尋找規則與不同之處 |
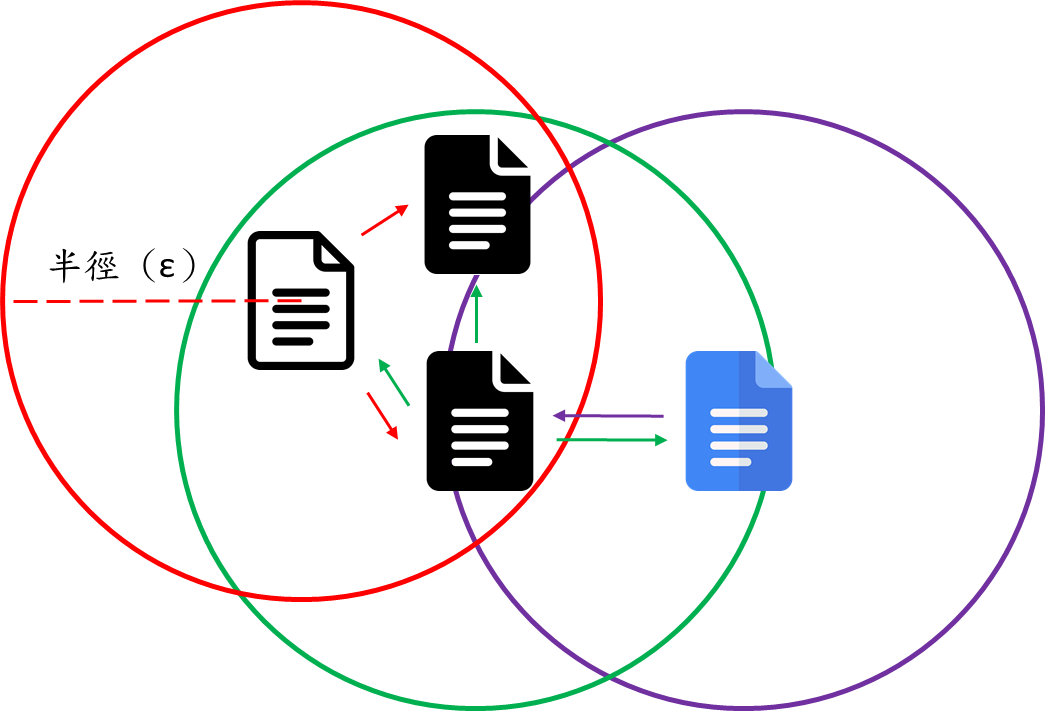
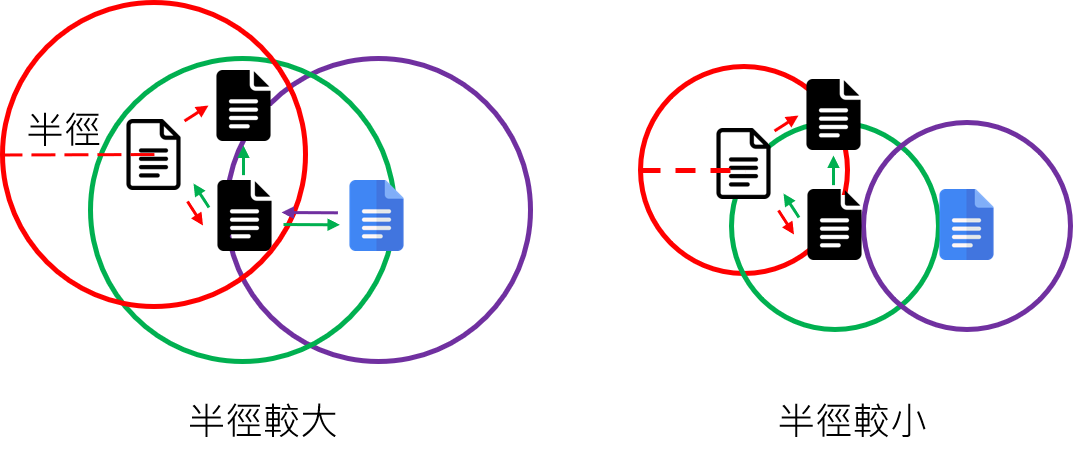
兩大參數
- 距離:半徑 (ε)
- 最少點數:minPts
流程
-
任意選取一個樣本當作中心點,以設定好的半徑畫圓
- 若圓內樣本數大於等於最少點數,則此樣本為一核心點
- 反之則為非核心點
- 重複前步驟直到所有樣本皆當過中心點
- 將有連結性(雙向)的樣本點劃分為一群,其他局外點可檢視是否單向可達,劃分為不同群體。


DBSCAN 優缺點
- 優點
- 不受極端質影響
- 不須事先選擇樣本群數,模型中會自動決定
- 缺點
- 若維度過高,則須非常大量的樣本才能達到比較好的預測效果
- 若資料密度差異大,效果會較差
簡易實作
打開 google colab
引入套件
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.cluster import DBSCAN載入資料集
iris = datasets.load_iris()
x = iris.data
x = x[:,2:4]建立模型
clustering = DBSCAN().fit(x)顯示分群結果
clustering.labels_-1為噪點 (Noisy samples)
結果圖像化
plt.scatter(x[:,0],x[:,1],c=clustering.labels_)原始答案
y = iris.target
plt.scatter(x[:,0],x[:,1],c=y)Reference
- Yao-Jen Kuo (2017). Scikit-Learn 教學:Python 與機器學習. Retrieved from: https://reurl.cc/nnY6p1.
- Jason Chen (2020).【機器學習】基於密度的聚類演算法 DBSCAN. Retrieved from: https://reurl.cc/WEOabe.
- Rita Tang (2020). 機器學習易混淆名詞/演算法比較. Retrieved from: https://reurl.cc/ynA1l2.
- 三大類機器學習:監督式、強化式、非監督式. Retrieved from: https://reurl.cc/MZz1LL.
- PyInvest (2020). [Python實作] 密度聚類 DBSCAN. Retrieved from: https://reurl.cc/1gOjqm.
- PyInvest (2020). [機器學習首部曲] 密度聚類 DBSCAN. Retrieved from: https://reurl.cc/E20vZa.
感謝聆聽_(:3 ⌒゙)_
DBSCAN 介紹
By sandy-tsai



