Python 網頁爬蟲
- Selenium 篇 -
講者:蔡孟軒
日期:2020/5/12
OUTLINE
- 前置作業
- 自動登入 Tronclass
- 獲取公告資料
- 寫檔
前置作業
創建並進入虛擬環境
$ python -m venv venv
$ venv\Scripts\activate建議今天的東西建一個資料夾放
創建的虛擬環境請切到這個資料夾建立
安裝套件
$ pip install selenium
$ pip install tensorflow
$ pip install pandas
$ pip install pillow本日建議如果要你更新 pip 就更新
下載 Selenium WebDriver
依照你的瀏覽器還有版本選擇
下載驗證碼辨識的訓練集
點 這裡 下載
這邊是已經跑過 100 張圖片的訓練集
自動登入 Tronclass
輸入帳號密碼
from selenium import webdriver
def login(driver, ac, pa):
driver.find_element_by_id("username").clear()
driver.find_element_by_id("password").clear()
username = driver.find_element_by_id("username")
password = driver.find_element_by_id("password")
username.send_keys(ac)
password.send_keys(pa)
driver = webdriver.Chrome()
driver.get("放入網址")
ac = "輸入自己的學號"
pa = "輸入自己的密碼"
login(driver, ac, pa)
稍微了解一下如何找到需要的位置 點這
擷取驗證碼
def get_captcha(driver):
element = driver.find_elements_by_tag_name("img")
img = element[1]
img.screenshot("captcha.png")
get_captcha(driver)辨識驗證碼
import numpy as np
from tensorflow.keras import models
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.preprocessing.image import load_img
digits_in_img = 4
img_rows = None
img_cols = None
def split_digits_in_img(img_array, img_rows, img_cols):
x_list = []
for i in range(digits_in_img):
step = img_cols // digits_in_img
x_list.append(img_array[:, i * step:(i + 1) * step] / 255)
return x_list
def number():
np.set_printoptions(suppress=True, linewidth=150, precision=9, formatter={'float': '{: 0.9f}'.format})
model = models.load_model('cnn_model.h5')
img_filename = './captcha.png'
img = load_img(img_filename, color_mode='grayscale')
img_array = img_to_array(img)
img_rows, img_cols, _ = img_array.shape
x_list = split_digits_in_img(img_array, img_rows, img_cols)
varification_code = []
for i in range(digits_in_img):
confidences = model.predict(np.array([x_list[i]]), verbose=0)
result_class = model.predict_classes(np.array([x_list[i]]), verbose=0)
varification_code.append(result_class[0])
guess = ""
for i in varification_code:
guess = guess+str(i)
return guess放程式最上方
輸入驗證碼、登入
def capt(driver):
get_captcha(driver)
guess = number()
driver.find_element_by_id("captcha").clear()
captcha = driver.find_element_by_id("captcha")
captcha.send_keys(guess)
driver.find_element_by_class_name("btn-submit").click()
# 加在login(driver, ac, pa)下
capt(driver)確認登入是否成功
title = driver.title
while title == "天主教輔仁大學 - 登入 Tronclass":
login(driver, ac, pa)
capt(driver)
title = driver.title不成功則重新輸入
獲得公告資料
獲得公告標題
from time import sleep
driver.get("https://elearn2.fju.edu.tw/bulletin-list/")
sleep(3)
info_dic = {"title":[], "class":[], "content":[]}
title_class = driver.find_elements_by_css_selector("div.bulletin-title span.ng-binding")
for i in range(0,10):
print(title_class[i].text)
info_dic["title"].append(title_class[i].text)獲得公告課程
class_name = driver.find_elements_by_css_selector("div.course-name-label.truncate-text span")
for i in range(0,10): # 這是剛剛的for迴圈
...
print(class_name[i].text)
info_dic["class"].append(class_name[i].text)
print()
試著寫看看
獲得公告內容
op = driver.find_elements_by_css_selector("div.bulletin-update-info")
for i in op:
i.click()
contents = driver.find_elements_by_css_selector("div.content-container")
for i in range(0,10): # 剛剛的for迴圈
print(contents[i].text)
info_dic["content"].append(contents[i].text)
print()
寫檔
基本讀寫檔
f = open(檔名, 模式, encoding=解碼方式)
"""
執行的動作
"""
f.close()with open(檔名, 模式, encoding=解碼方式) as f:
"""
執行的動作
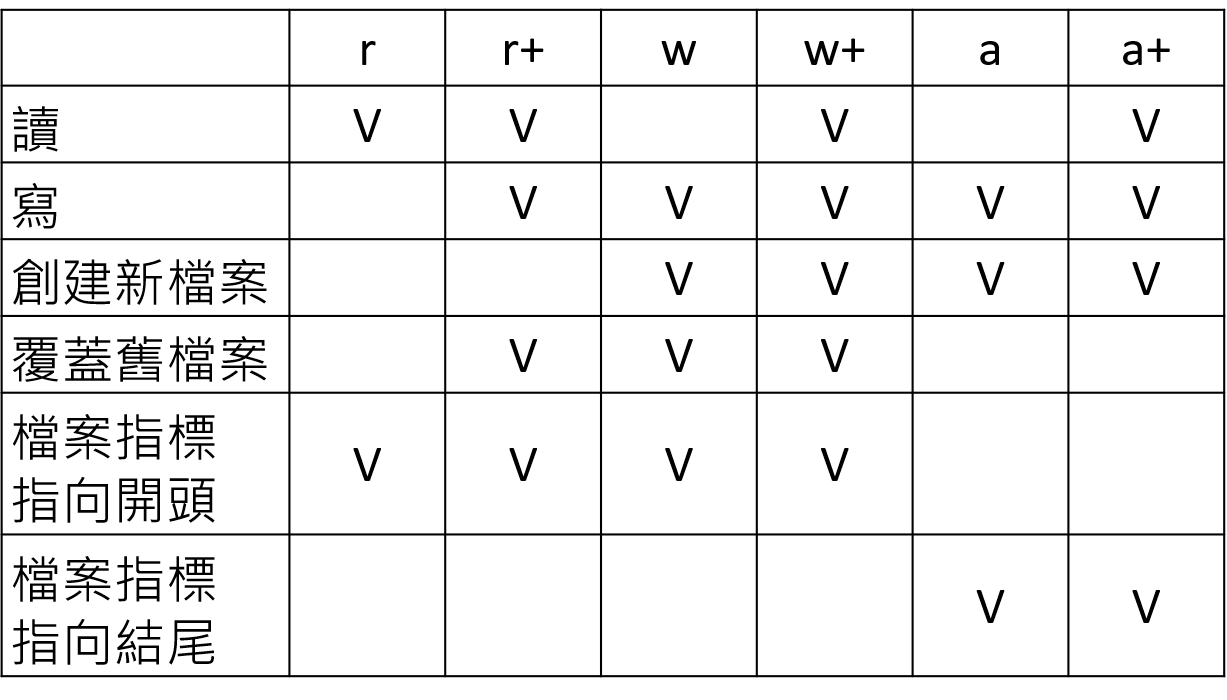
"""模式
寫成 txt 檔
with open('example.txt', 'w', encoding = 'utf-8') as f:
for i in range(0,10):
f.write(info_dic["title"][i] + "\n")
f.write(info_dic["class"][i] + "\n")
f.write(info_dic["content"][i] + "\n")
f.write("----------------我是分隔線----------------\n")寫成 csv 檔
import pandas as pd
import csv
anouce = pd.DataFrame(info_dic)
anouce.to_csv("./anouce.csv")Reference
- 未具名 (2016). Selenium-Python中文文档. Retrieved from: https://reurl.cc/0DA2ak
- CW Lin (2019). python 檔案讀寫. Retrieved from: https://reurl.cc/DvzdxQ
- Yu-Hsuan Chou (2019). Python 初學第十二講—檔案處理. Retrieved from: https://reurl.cc/E2xpmA
感謝聆聽 ( ~'ω')~
Python Selenium
By sandy-tsai



