Teoría del Caos
Chaos Engineering
Teoría del Caos
Sebastían Díaz
- Github: @seadiaz
- Twitter: @seadiaz
- LinkedIn: @seadiaz
Underworld Tribe Lead

¿Por Qué?
¿Por Qué?
Monolito => Microservicios
¿Por Qué?
Falacias de los Sistemas Distribuidos
- Las redes son confiables
- La latencia es cero
- El ancho de banda
- La red es segura
- Las topologías no cambia
- Hay un solo administrador
- El costo de transporte es cero
- Las redes son homogenias
¿Por Qué?
Iron Age => Cloud Age
¿Por Qué?
Hardware comóditi
- Discos duros estándar
- Tarjetas de red estándar
- Placas madres estándar
- Procesadores madres estándar
- Memorias madres estándar
- ...
¿Por Qué?
Iron Age => Cloud Age
Monolito => Microservicios
+
= Muchas eventos fuera de control
Pero yo construyo con calidad
Pero yo construyo con calidad
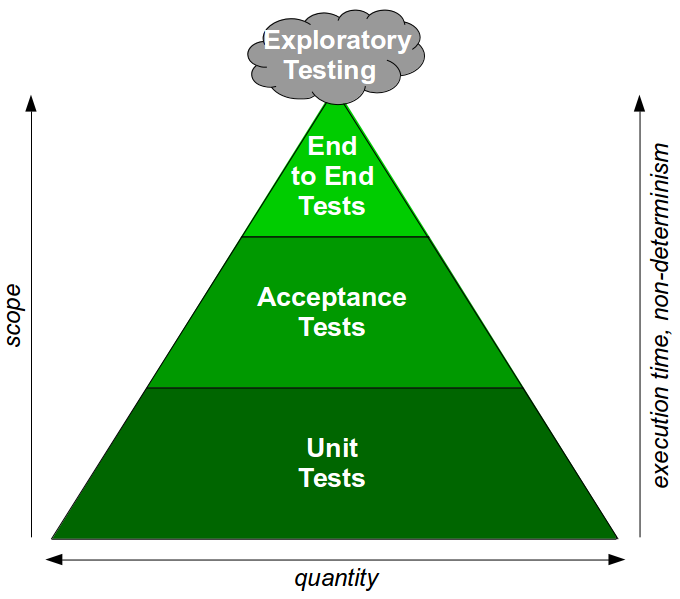
Pero yo construyo con calidad
¿Es suficiente?
Antifragilidad
Antifragilidad
Flexible
Robustez
Robustez
Capacidad de mantenerse funcionando frente a situaciones anómalas
Robustez
- Validar todo tipo de entradas
- Manejar todos caminos con errores
- Cortar conexiones que demoran mucho
- Reciclar conexiones
- Mantener consistentes los pools de conexiones
Resiliencia
Resiliencia
Capacidad de modificar el comportamiento para mantenerse funcionando frente a situaciones anómalas
Resiliencia
- Timeout
- Circuit Breaker
- Bulkhead
- Steady State
- Fail Fast
- Handshaking
- Test Harness
- Decoupling Middleware
- Shed Load
- Create Back Pressure
Antifragilidad
Capacidad de hacerse más fuerte a través de la provocación de un daño controlado
+ Robustez
+ Resiliencia
¿Es suficiente?
¿Es suficiente?
"Demasiadas variables fuera de nuestro control, por lo tanto, el comportamiento es difícil de predecir"
Chaos Engineering
Un poco de historia
Un poco de historia
2010
Netflix créa Chaos Monkey
2011
Netflix evoluciona hacia Simian Army
2012
Netflix libera el código de Chaos Monkey en Github
2014
Netflix crea un nuevo rol
Chaos Engineer
Requisitos
Requisitos
Modelo de gestión de incidentes
- Tipos de severidades
- Tiempos de respuestas
- Rotación de turnos 24/7
- Sistemas de notificación
- Modelo de escalamiento
- Traspasos de información
Requisitos
Monitoreo
- Las 4 señales de oro
- Latencia
- Tráfico
- Tasa de error
- Saturación
- Tendencias
- Dashboard
- Alerting
- Análisis retrospectivo
Requisitos
Medir el impacto de la indisponibilidad
Negocio/Cliente
- Costos
- Reputación
- Tiempo
- Resultado
Sistema
- Disponibilidad
- Durabilidad
- Integridad
Paso a paso
Paso a paso
1) Encontrar un estado de estabilidad
Paso a paso
2) Definir la hipótesis de que el estado se mantiene en un grupo experimental y en uno de control
Paso a paso
3) Introducir variables que reflejen escenarios reales en el grupo de experimentación
Paso a paso
4a) Refutar la hipótesis de que ambos grupos se mantienen estables
Experimento
Paso a paso
4b) Refutar la hipótesis de que ambos grupos se mantienen estables
Experimento exitoso
Principios
Principios
Crea hipótesis basándote en comportamientos de estado estable
Principios
Introduce eventos del mundo real
Principios
Ejecuta los experimentos en producción
Principios
Automatiza los experimentos para que puedan correr de manera continua
Principios
Minimiza el radio de impacto
Priorización de experimentos
Priorización de experimentos
Conocido
Desconocido
Conocidos
Desconocidos
Somos conscientes y entendemos
Somos conscientes y no entendemos
Entendemos pero no somos conscientes
No sabemos ni somos conscientes
Beneficios
Beneficios
Clientes
Un servicios sin indisponibilidad
Negocio
Sin perdidas de ingresos ni costos de mantención
Técnicos
Pueden ocupar su tiempo libre sin preocupaciones
¿Debería aplicarlo en mi contexto ?
¿Debería aplicarlo en mi contexto ?
Tengo
Tengo una infraestructura dinámica
Soy de uso masivo o tengo expectativas de serlo
Tengo resuelto todos los requisitos
¿Cómo sigo?
https://github.com/netflix/chaosmonkey
¿Cómo sigo?
https://principlesofchaos.org/
https://www.gremlin.com/community
https://github.com/dastergon/awesome-chaos-engineering
Chaos Engineering
Chaos Engineering
By Sebastian Diaz




