benchcab
A testing framework for the CABLE land surface model
Open the slide deck at: slides.com/seanbryan/benchcab
Issues with non-standardised testing
- Sufficient code coverage is not guaranteed
- Easy to cherry pick test cases
- Not guaranteed to be reproducible
- Test results often incomparable
- Takes time and effort to setup
The ideal testing framework
- Extensive coverage across test cases
- Reproducible tests
- Automated with very minimal overhead to run
- Results are comparable
- Test cases are extensible to new model features
benchcab
- An attempt to converge on the ideal testing framework for CABLE
- A command line tool written in Python
- Initially developed by Martin De Kauwe
- Currently developed and maintained by CABLE's user community and ACCESS-NRI
- See Github
Usage
1. Getting access on NCI
module use /g/data/hh5/public/modules
module load conda/analysis3-unstablemkdir -p /scratch/nf33/$USER
cd /scratch/nf33/$USER
git clone git@github.com:CABLE-LSM/bench_example.git
cd bench_example2. Clone the example work directory
3. Configure the configuration file
vi config.yaml4. Run the tests
benchcab runSetup
2. Getting access to benchcab on NCI
module use /g/data/hh5/public/modules
module load conda/analysis3-unstablemkdir -p /scratch/nf33/$USER
cd /scratch/nf33/$USER
git clone git@github.com:CABLE-LSM/bench_example.git
# git clone https://github.com/CABLE-LSM/bench_example.git
cd bench_example3. Clone the example work directory
1. Connect to NCI
ssh -Y <userID>@gadi.nci.org.auExercise
Running benchcab for:
- the Tumbarumba experiment
- using the nf33 project
- to compare CABLE trunk and branches/Users/ccc561/demo-branch
Exercise
project: nf33
experiment: AU-Tum
realisations: [
{
path: "trunk",
},
{
path: "branches/Users/ccc561/demo-branch",
}
]
modules: [
intel-compiler/2021.1.1,
netcdf/4.7.4,
openmpi/4.1.0
]1. Edit config.yaml to the following:
2. Run benchcab with the verbose flag enabled
benchcab run --verboseAutomated workflow

Manual step
The example work directory
-
config.yaml- Tests are fully reproducible from the config file
- See the documentation for all configuration options.
-
namelists- Contains the "base" namelist files used by all tests. Each test applies a test specific "patch" on top of the base namelist files.
$ tree bench_example/
bench_example/
├── config.yaml
├── LICENSE
├── namelists
│ ├── cable.nml
│ ├── cable_soilparm.nml
│ └── pft_params.nml
└── README.mdFlux site tests
- Flux site configuration - running CABLE at a single point forced by observed eddy covariance data
- Test coverage over different science configurations and sites
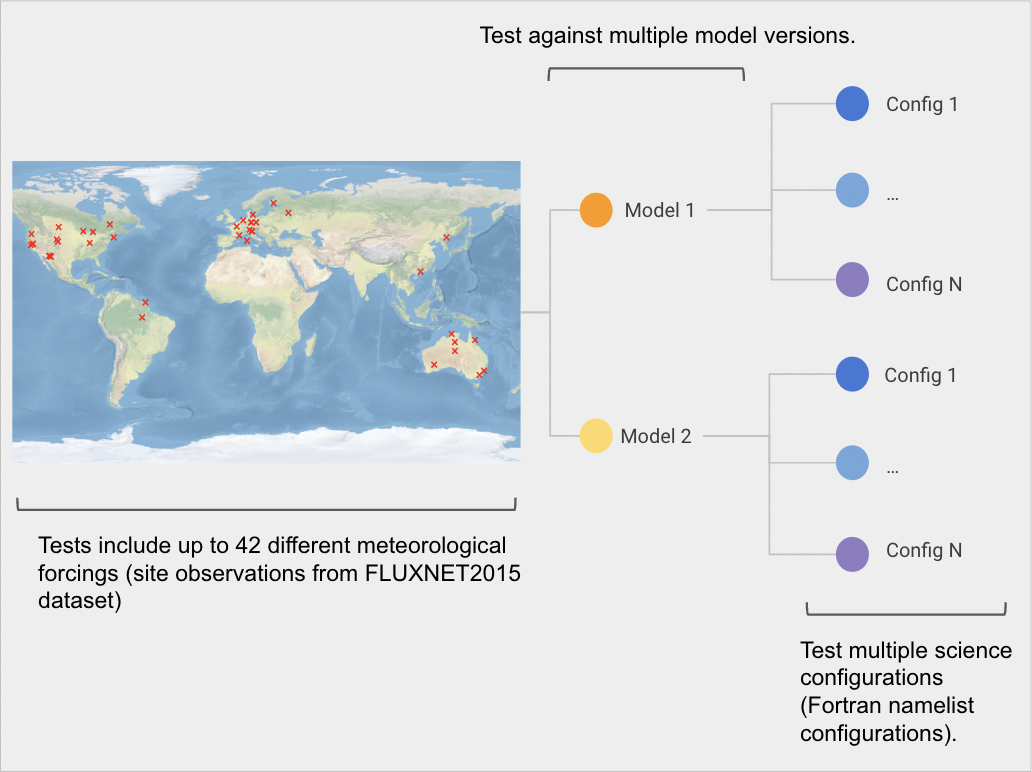
Directory structure and files
- benchcab creates the following directory structure on success
.
├── benchmark_cable_qsub.sh
├── benchmark_cable_qsub.sh.o<jobid>
├── rev_number-1.log
├── runs
│ └── site
│ ├── logs
│ │ ├── <task>_log.txt
│ │ └── ...
│ ├── outputs
│ │ ├── <task>_out.nc
│ │ └── ...
│ ├── analysis
│ │ └── bitwise-comparisons
│ └── tasks
│ ├── <task>
│ │ ├── cable (executable)
│ │ ├── cable.nml
│ │ ├── cable_soilparm.nml
│ │ └── pft_params.nml
│ └── ...
└── src
├── CABLE-AUX
├── <realisation-0>
└── <realisation-1>
- See the user guide for a description of all files/directories
Exercise: model evaluation
- Upload model outputs from the run directory to modelevaluation.org.
- See the user guide for detailed instructions. Note: Do not go through step 3 (create a model profile). In step 4.c, use "trunk false_feature demo" for the model profile
- If your benchcab instance has not finished, you can use the example outputs in:
/scratch/nf33/ccc561/standard_evaluation/runs/site/outputsFull workflow demo:
Making tests extensible to new features
-
benchcabcan support new namelist parameters introduced by a code change through thepatchoption -
patchspecifies any branch specific namelist parameters which are then applied to namelist files for tasks that run the corresponding branch
patch: {
cable: {
cable_user: {
MY_NEW_FEATURE: True
}
}
}Exercise:
Use a different potential evaporation scheme for one branch only
realisations: [
{
path: "trunk",
},
{
path: "branches/Users/sb8430/test-branch",
patch: {
cable: {
cable_user: {
SSNOW_POTEV: "P-M"
}
}
}
}
]
- Run benchcab with the following namelist patch in config.yaml:
Custom science configurations
science_configurations: [
{ # S0 configuration
cable: {
cable_user: {
GS_SWITCH: "medlyn",
FWSOIL_SWITCH: "Haverd2013"
}
}
},
{ # S1 configuration
cable: {
cable_user: {
GS_SWITCH: "leuning",
FWSOIL_SWITCH: "Haverd2013"
}
}
}
]
Users can specify their own science configurations in config.yaml
Running with CABLE version 2.x
See the documentation for potential gotchas.
Future work
🚧 Test suites for:
◦ Global/regional simulations (offline CABLE)
◦ Global/regional simulations (online CABLE)
◦ CABLE-CASA-CNP
🚧 A standard set of science configurations.
🚧 Fortran code coverage analysis.
🚧 Automated model evaluation step.
🚧 Tests for different compilers and compiler flags.
🚧 Updates to analysis plots for flux site tests.
🚧 Model evaluation with ILAMB
Summary
- benchcab is a testing framework that is:
- Easy to use
- Standardised
- Automated
- Reproducible
- benchcab should be used by everyone who contributes to CABLE development!
We need your feedback!
GitHub issues: github.com/CABLE-LSM/benchcab/issues
ACCESS-Hive forum: forum.access-hive.org.au
Model evaluation
- Comparison analysis plots done on modelevaluation.org
- The benchcab documentation has detailed instructions.
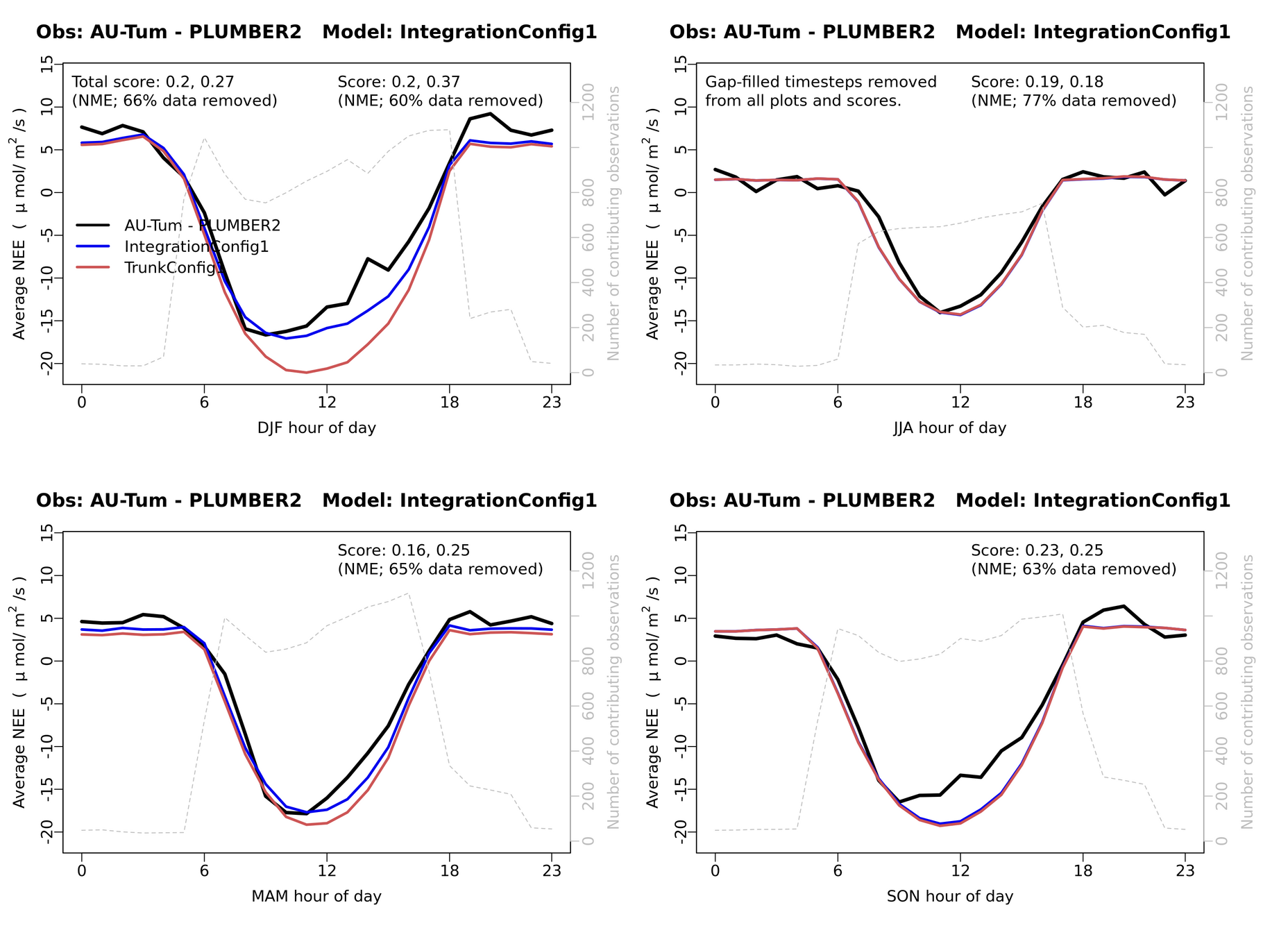
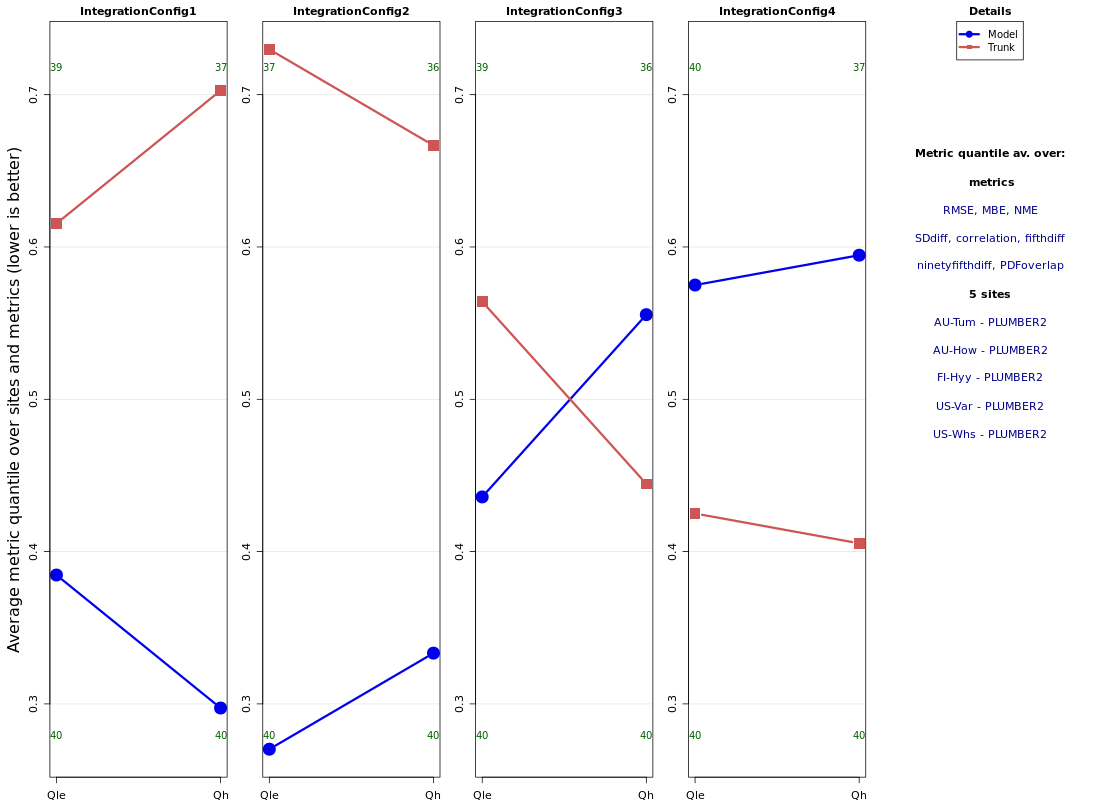
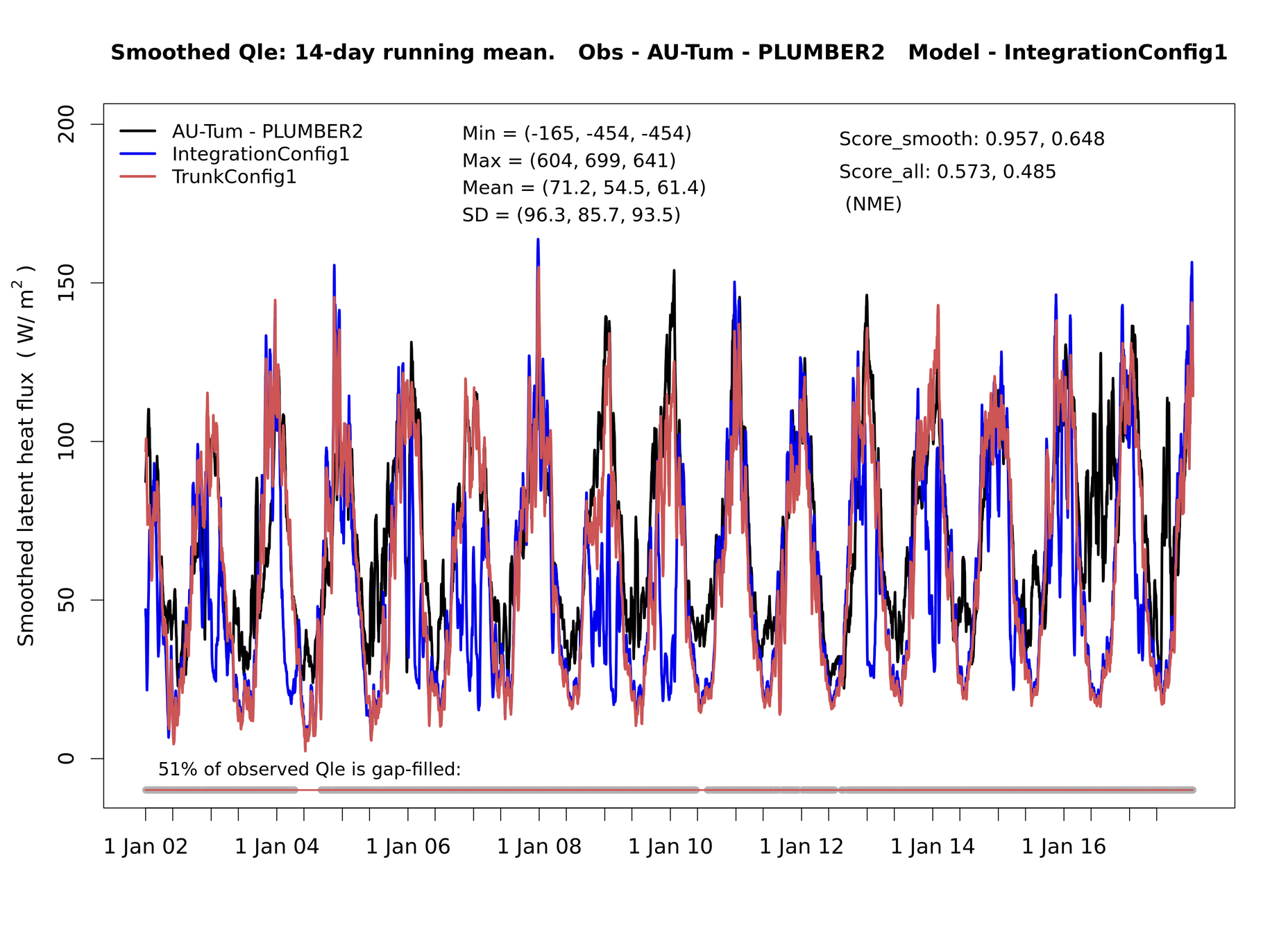
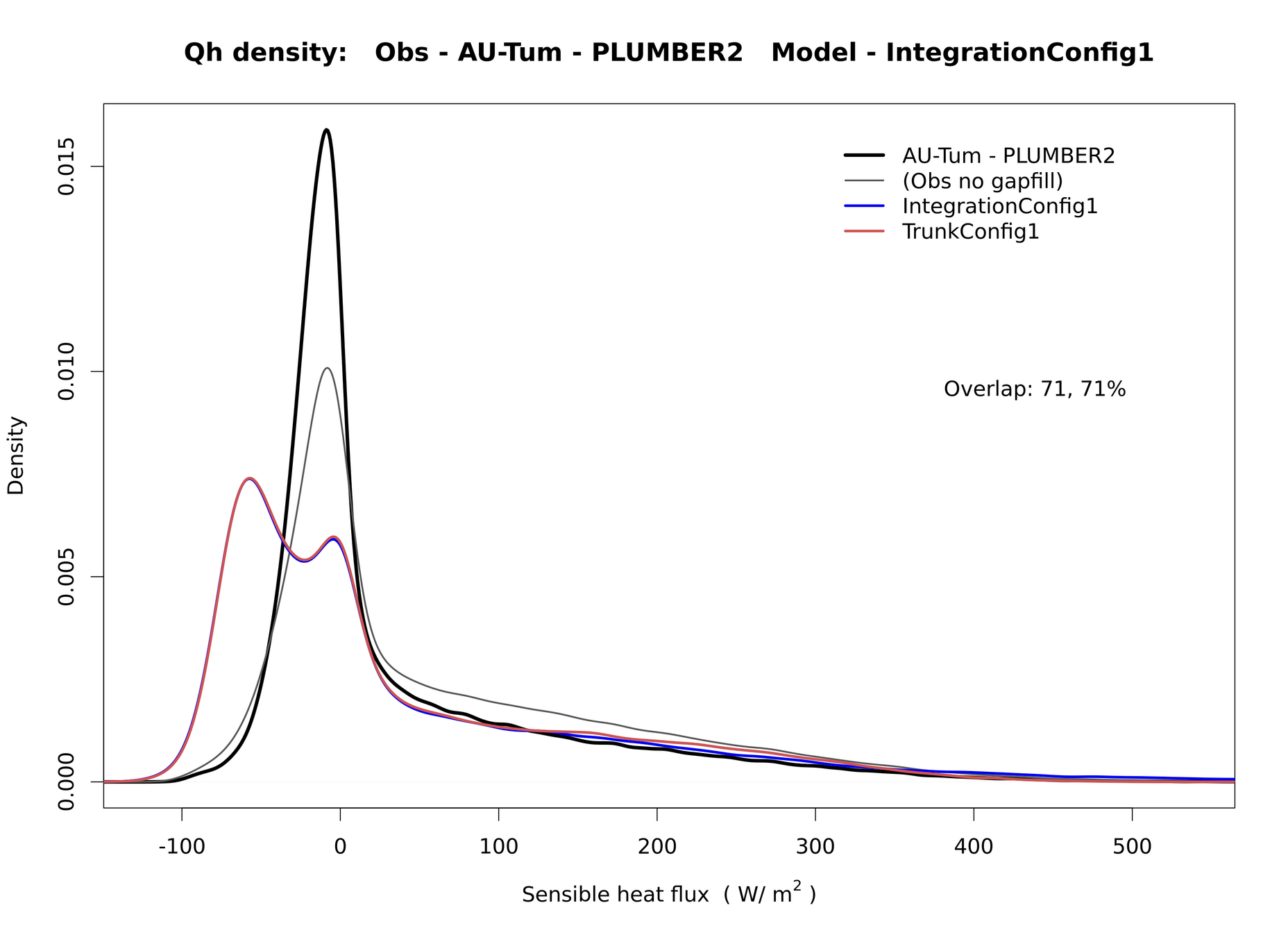
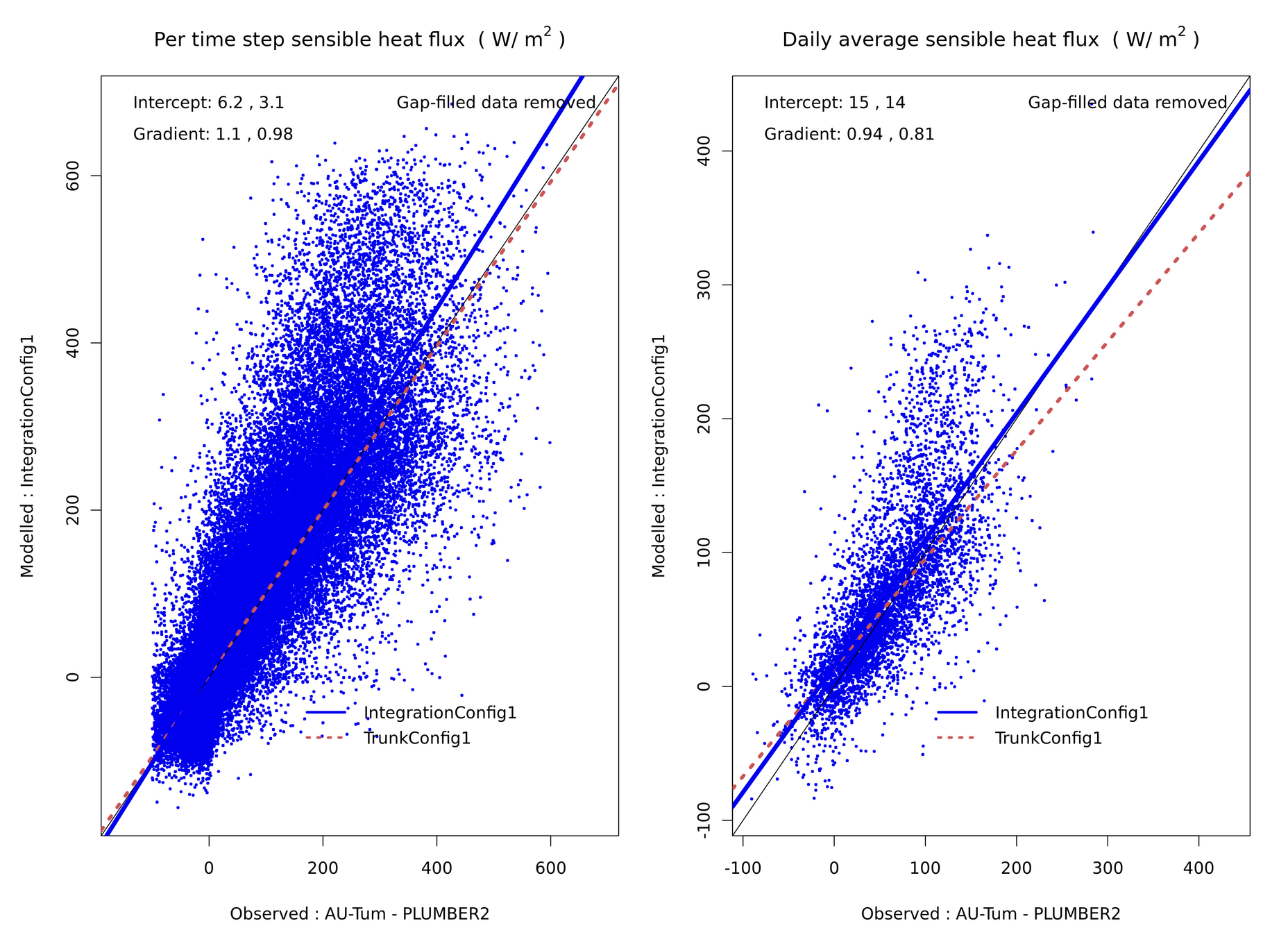
Regression testing
- By default, benchcab runs bitwise comparison checks on model outputs across model versions.
Demo
realisations: [
{
path: "trunk",
name: "trunk_head"
},
{
path: "trunk",
name: "trunk_r9468",
revision: 9468
}
]Motivation / rationale
-
Evaluation: We want CABLE developers to easily evaluate the impact of their code additions to CABLE
-
Standardisation: We want a standardised evaluation of CABLE to allow for comparison
-
Automation: CABLE is highly configurable, running tests manually for every possible configuration is time consuming
What benchcab does (hopefully):
-
benchcabprovides a fast, standardised way for developers of CABLE to evaluate how code changes affect the model output. -
benchcabautomates running tests against a lot of possible configurations of CABLE - checks out, builds and runs all tests in a reproducible environment
Configurability
-
benchcabis intended to have limited configurability by design - Current configurable options include:
- Running specific steps of the workflow in isolation
- Choosing the modules used for compiling CABLE
- Running CABLE with a subset of the configurations
- Adding a "branch specific" namelist patch
Modes currently supported
Regression mode:
run 2 models with the same science options

New feature mode:
run 2 models. One with a science patch added to the science options

Ensemble mode:
run any number of models with custom science options

Will be required for code submissions
Necessary to support old versions
Better set of analysis plots
-
Summary plots: measure improvement of new branch vs control
- for all sites, all metrics, all variables
- same per variable
- same per PFT
- same per PFT, per variable
- for all sites, all metrics, all variables
- "PLUMBER" plots

- for outputs that contain a single flux site: timeseries, seasonal and diurnal cycle, model/obs scatter plots, ...
- Use full set of variables available at flux sites
Demo: flux site tests
Running benchcab
-
benchcabis executed via the command line - sub-commands allow specific steps of the workflow to be run in isolation
$ benchcab -h
usage: benchcab [-h] [-V] command ...
benchcab is a tool for evaluation of the CABLE land surface model.
positional arguments:
command
run Run all test suites for CABLE.
fluxnet Run the fluxnet test suite for CABLE.
checkout Run the checkout step in the benchmarking workflow.
build Run the build step in the benchmarking workflow.
fluxnet-setup-work-dir
Run the work directory setup step of the fluxnet command.
fluxnet-run-tasks Run the fluxnet tasks of the main fluxnet command.
spatial Run the spatial tests only.
optional arguments:
-h, --help Show this help message and exit.
-V, --version Show program's version number and exit.Running benchcab
- To run the full test suite, use the
benchcab runcommand:
$ benchcab run
Creating src directory: /scratch/tm70/sb8430/bench_example/src
Checking out repositories...
Successfully checked out trunk at revision 9550
Successfully checked out test-branch at revision 9550
Successfully checked out CABLE-AUX at revision 9550
Writing revision number info to rev_number-1.log
Compiling CABLE serially for realisation trunk...
Successfully compiled CABLE for realisation trunk
Compiling CABLE serially for realisation test-branch...
Successfully compiled CABLE for realisation test-branch
Setting up run directory tree for FLUXNET tests...
Creating runs/site/logs directory: /scratch/tm70/sb8430/bench_example/runs/site/logs
Creating runs/site/outputs directory: /scratch/tm70/sb8430/bench_example/runs/site/outputs
Creating runs/site/tasks directory: /scratch/tm70/sb8430/bench_example/runs/site/tasks
Creating task directories...
Setting up tasks...
Successfully setup FLUXNET tasks
Creating PBS job script to run FLUXNET tasks on compute nodes: benchmark_cable_qsub.sh
PBS job submitted: 82479088.gadi-pbs
The CABLE log file for each task is written to runs/site/logs/<task_name>_log.txt
The CABLE standard output for each task is written to runs/site/tasks/<task_name>/out.txt
The NetCDF output for each task is written to runs/site/outputs/<task_name>_out.ncUsing modelevaluation.org
- Open and log into modelevaluation.org
- Navigate to the NRI Land testing workspace
- Create a model profile for the two model branches you are using
- Create a model output and upload the outputs in
runs/sites/outputs/under your work directory - Launch the analysis
benchcab
By seanbryan
benchcab
ACCESS-NRI workshop benchcab presentation + demo/training