Summer Student Programme 2021
Sebastian Ordoñez
jsordonezs@unal.edu.co
Supervisors: Alberto C. dos Reis Diego Milanés.
7\(^{th}\) September 2021
Selection of the
\(D^{+}\longrightarrow K^{-}K^{+}K^{+}\) candidates at the LHCb experiment


Outline
- Introduction
- Data Analysis
- Pre selection
- Multivariate Analysis
- Results
- Summary
Introduction
- The study is based on a sample of \(pp\)-collision data, collected at a centre-of-mass energy of 13 TeV with the LHCb detector in 2016
- \(D\) mesons are a unique laboratory to study light quark spectroscopy. Three-body decay of these mesons exhibit rich interference between intermediate states.

The \(D\) mesons are the lightest particle containing charm quarks.
\(D^{+}\) mass: 1869.62\(\pm\)0.20 MeV
- They offer rich phenomenology, including unique sensitive to \(CP\) violation and charm mixing (New Physics).
- The selection of \(D^{+}\longrightarrow K^{-}K^{+}K^{+}\) candidates is performed using a multivariate analysis (MVA).
Data Analysis
Pre-selection: Clone Tracks

\boxed{1.}
\boxed{2.}
- Before using MVA it is necesasry to reduce the high levels of background: clone tracks and combinatorial.
- Clone tracks originate when two tracks share more than 70% of their hits in the tracking system.
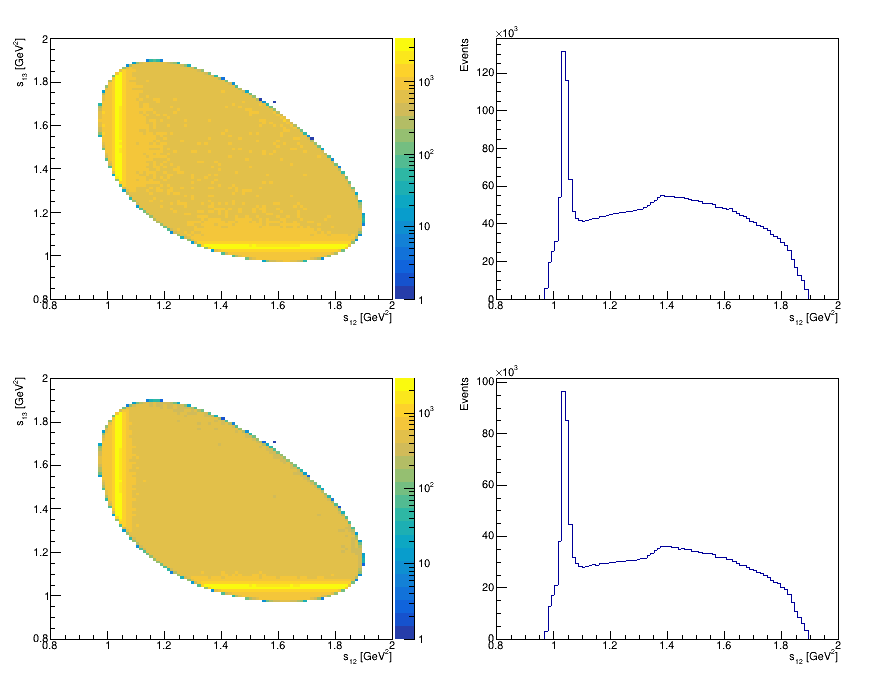
Dalitz Plot before and after cuts on the slope difference variables
\text{difTX}_{ij}=\left|\frac{p_{x_{i}}}{p_{z_{i}}}-\frac{p_{x_{j}}}{p_{z_{j}}}\right|
\text{difTY}_{ij}=\left|\frac{p_{y_{i}}}{p_{z_{i}}}-\frac{p_{y_{j}}}{p_{z_{j}}}\right|
- We use the slope difference variables:
Data Analysis
Pre-selection: Clone Tracks
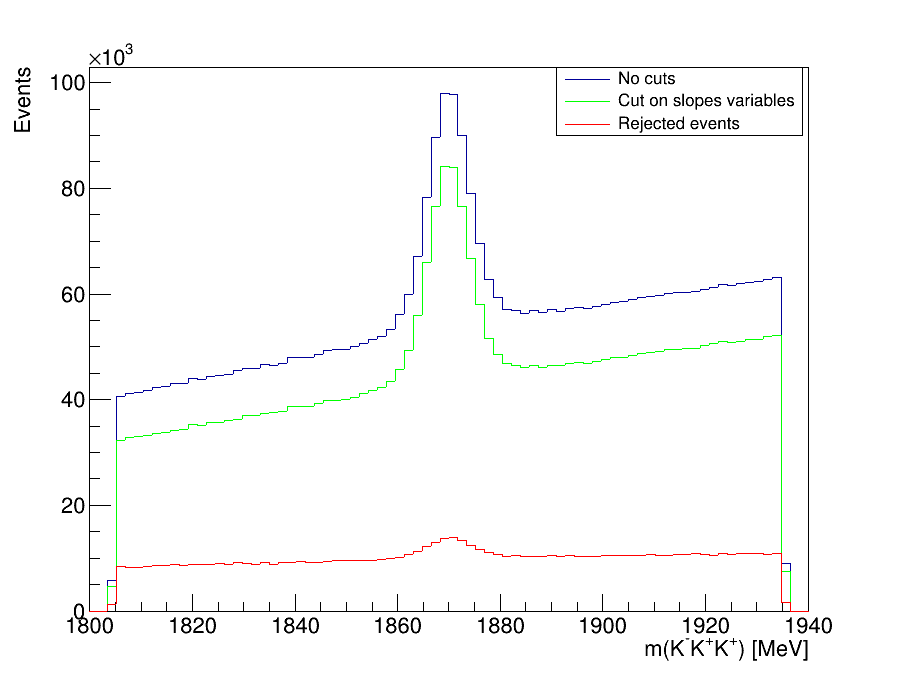
\(D^{+}\longrightarrow K^{-}K^{+}K^{+}\) invariant-mass distribution
Data Analysis
Pre-selection: PID
\boxed{3.}
\boxed{2.}
Dalitz Plot before and after cuts on PID variables (ProbNNK)
- We impose requirements on PID variables, in order to remove combinatorial background
- Background coming from the decay of charmed mesons in which one - or two - of the product particles is misidentified as a kaon
- The two main sources in our analysis are \(\Lambda^{+}_{c}\) decays into \(K^{-}K^{+}p\) and \(K^{-}p\pi\) final states.
Data Analysis
Pre-selection: (PID)
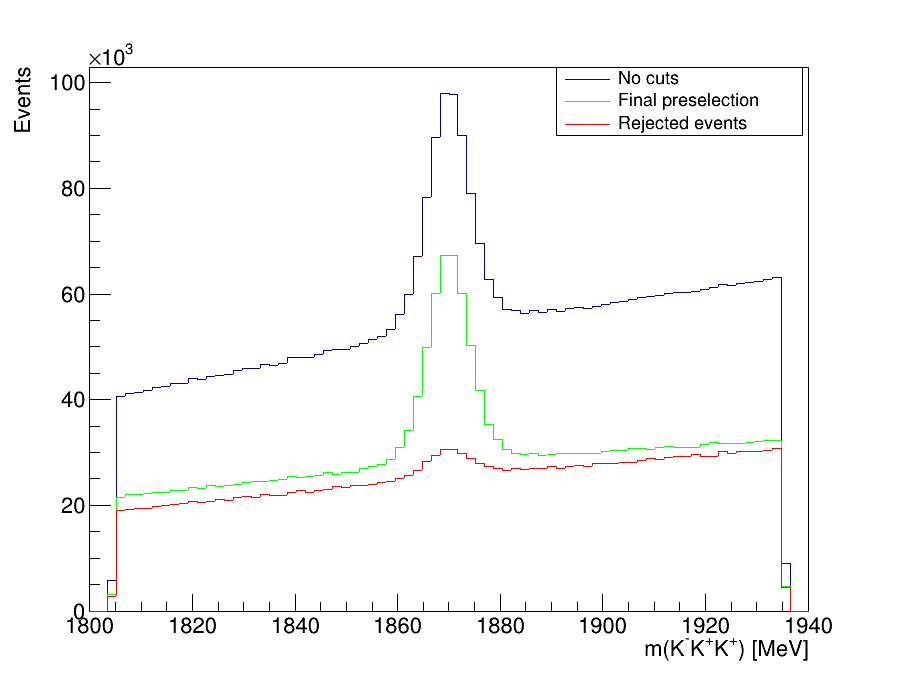
\(D^{+}\longrightarrow K^{-}K^{+}K^{+}\) invariant-mass distribution
Data Analysis
Multi-variate Analysis (MVA): Training
MVA algorithm uses a set of discriminating variables for known background and signal events, with the purpose of building a new variable which provides an optimal signal-background
discrimination.
Background from data
Signal from Monte Carlo
Data Analysis
Multi-variate Analysis (MVA): Training
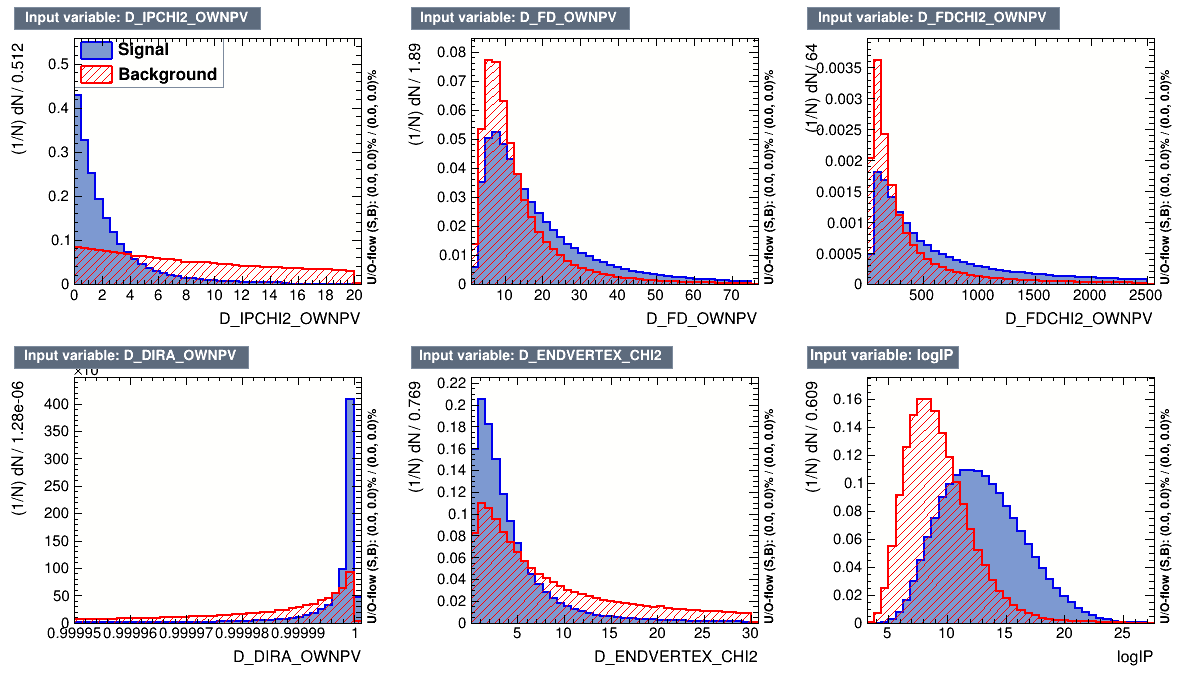
Input variables for the MVA Algorithms
The discriminating variables chosen for the MVA methods are only related to the
\(D^{+}\) candidate
Data Analysis
Multi-variate Analysis (MVA): Training
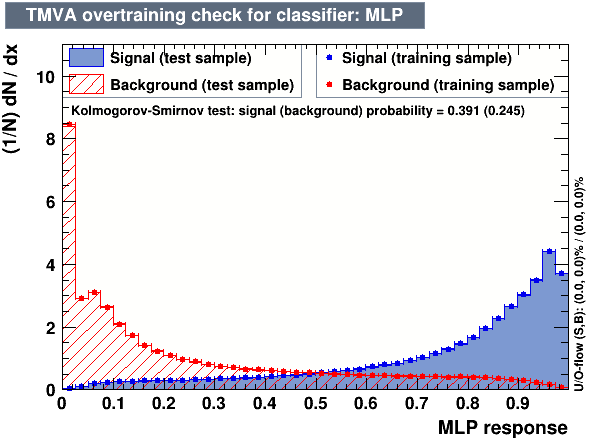
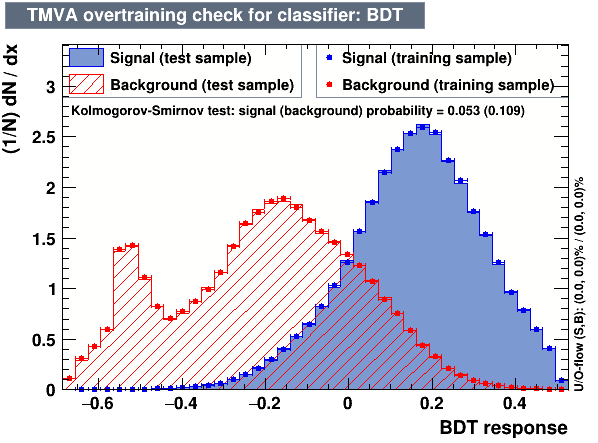
The following algorithms were considered: Multi Layer Perceptron (MLP), Gaussian Boosted Decision Tree (BDTG), BDT, Decorrelated BDT (BDTD).
Classifier output distributions
Data Analysis
Multi-variate Analysis (MVA): Training
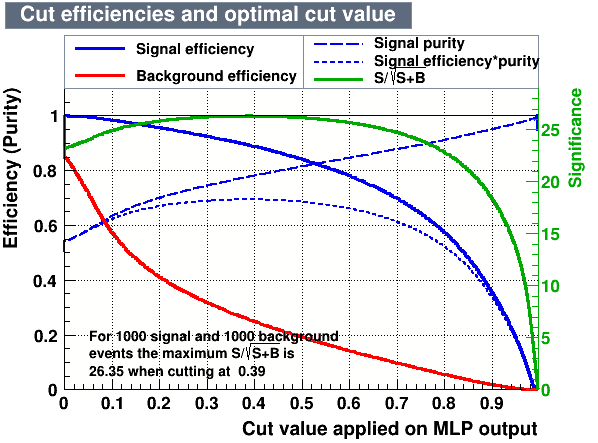
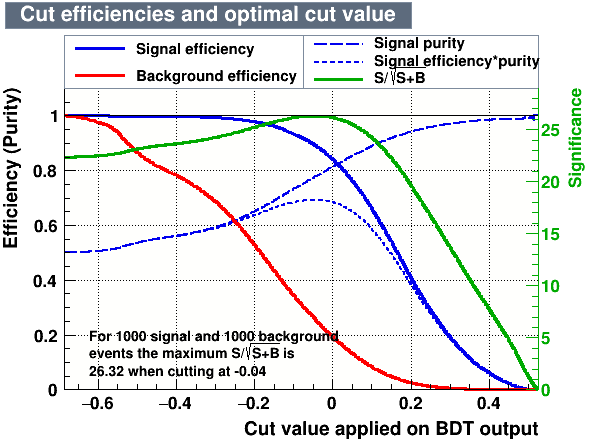
Cutting on the value of the MVA variables, it is possible to find the one which maximises a given figure of merit, providing high signal efficiency and at the same time a significant background rejection.
Data Analysis
Multi-variate Analysis (MVA): Training

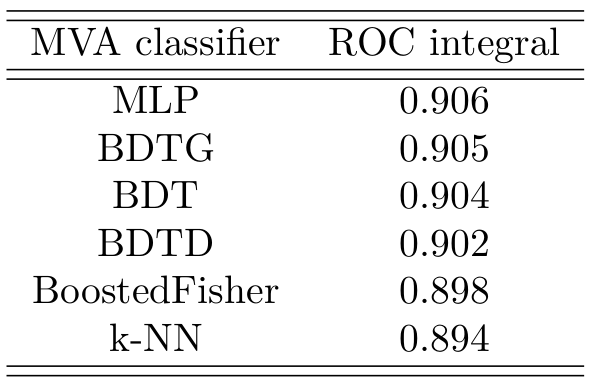
ROC curve for all the classifiers
Area under the ROC curve
Data Analysis
Multi-variate Analysis (MVA): Application
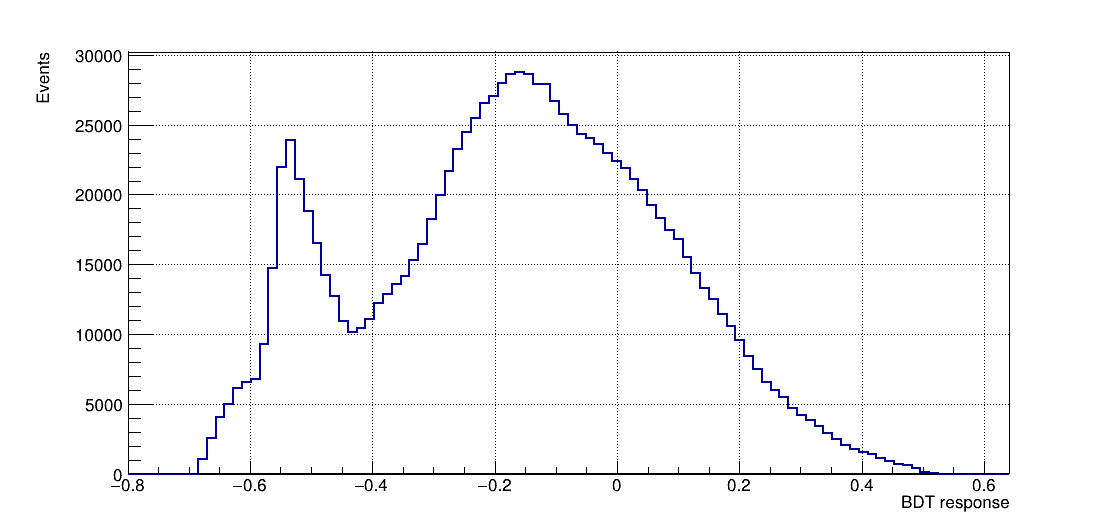
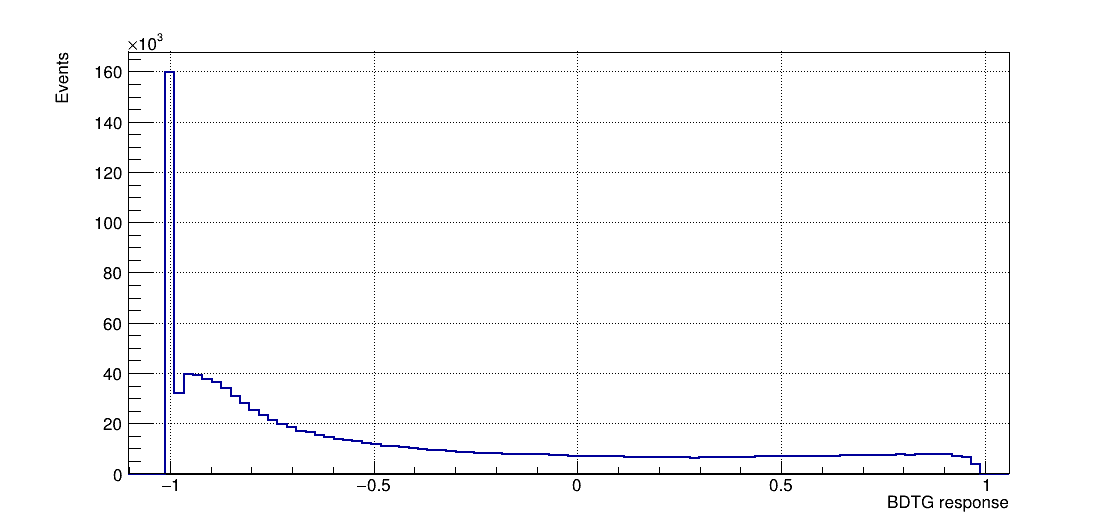
Once the training is completed, the next phase is the application of these results to an independent data set with unknown signal and background composition
Results
Significance curves
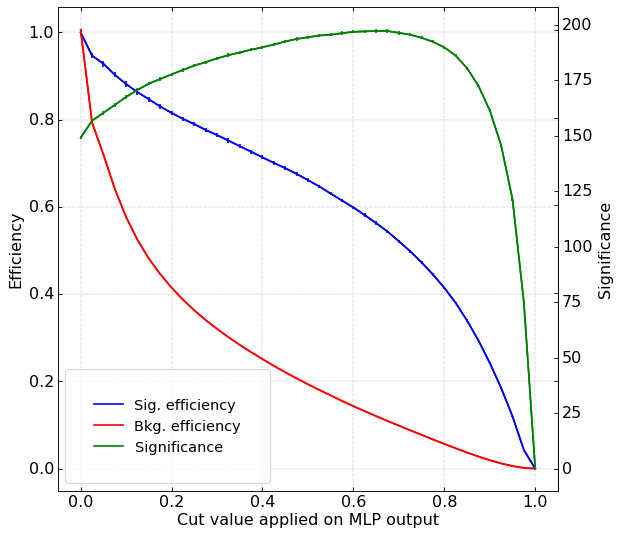
Result of applying cuts in the classifiers that showed the best signal-background discrimination performance
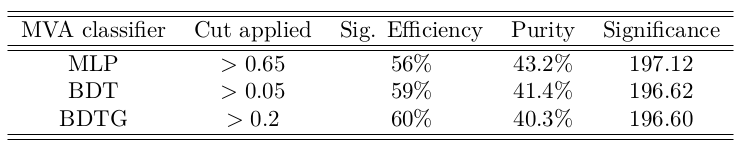
- Cut values which give the maximum signal significance
Results
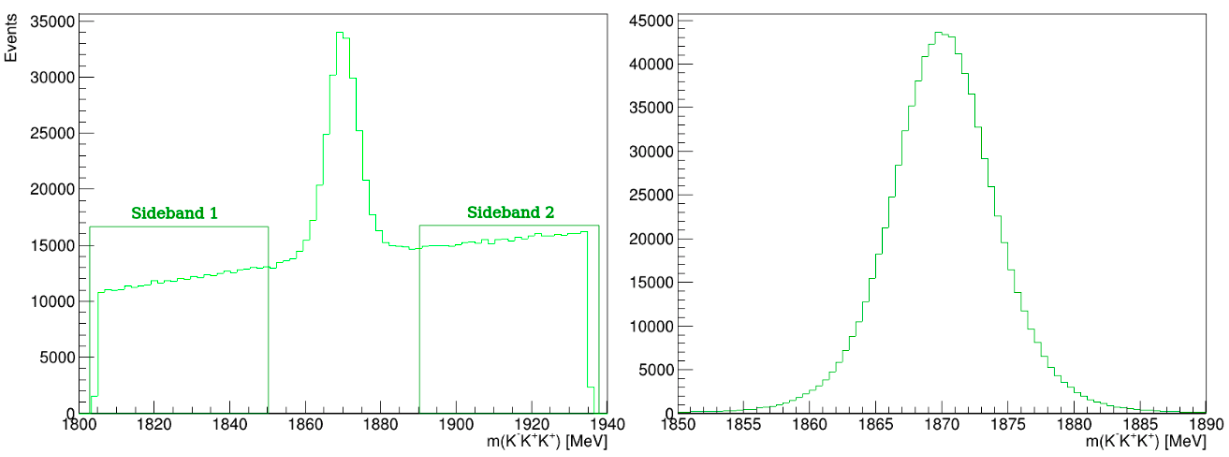
\(D^{+}\longrightarrow K^{-}K^{+}K^{+}\) invariant-mass spectrum
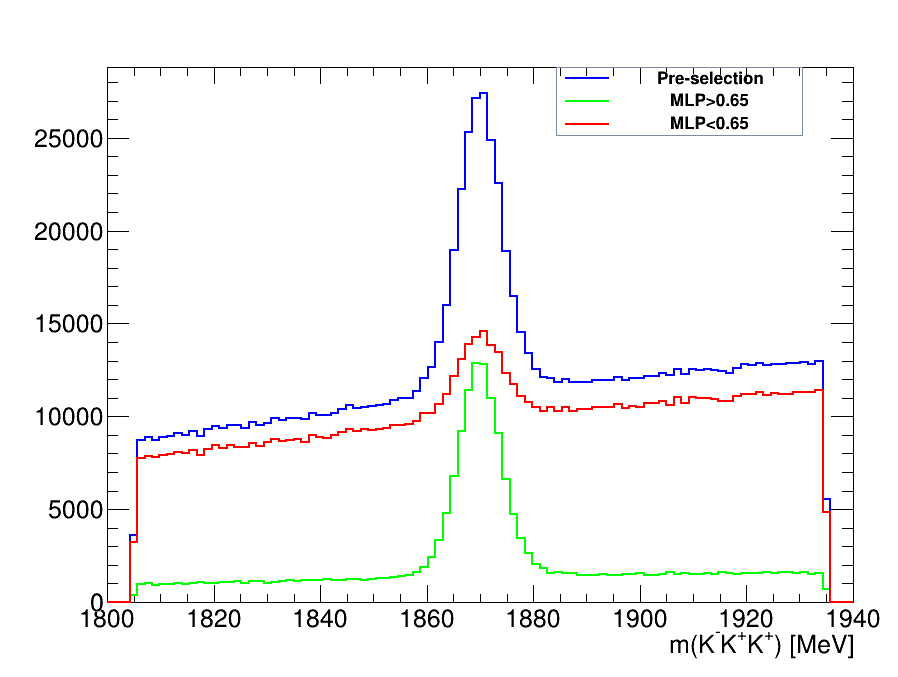
This is the final invariant-mass distribution of the \(K^{-}K^{+}K^{+}\) candidates after applying the cut on the MLP classifier, the one with the best performance.
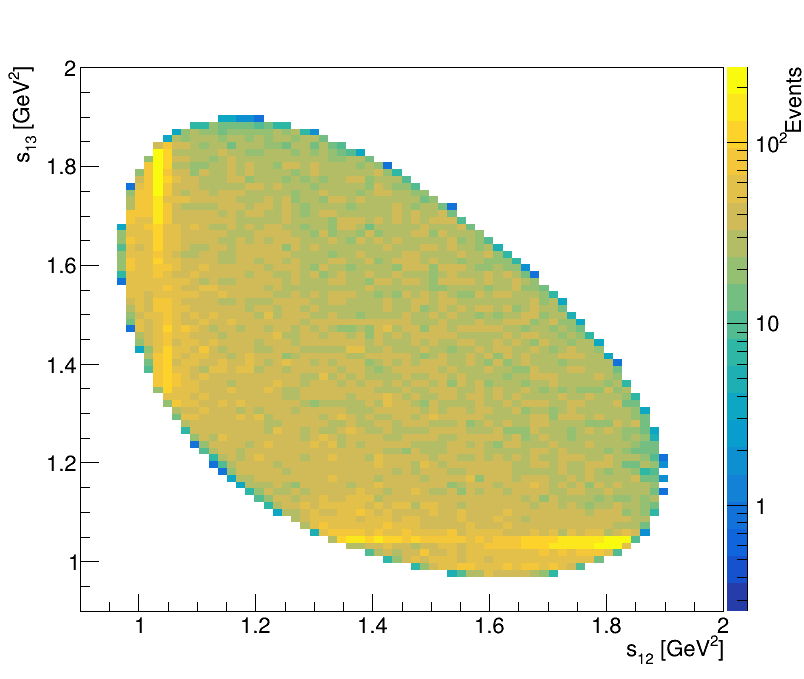
Results
Final Dalitz Plot and Projections
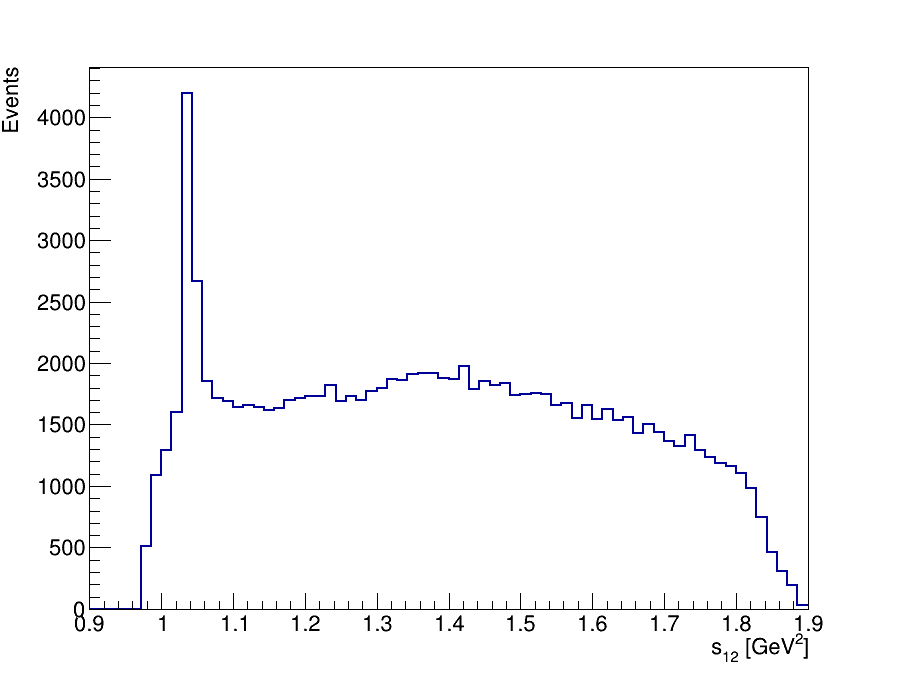
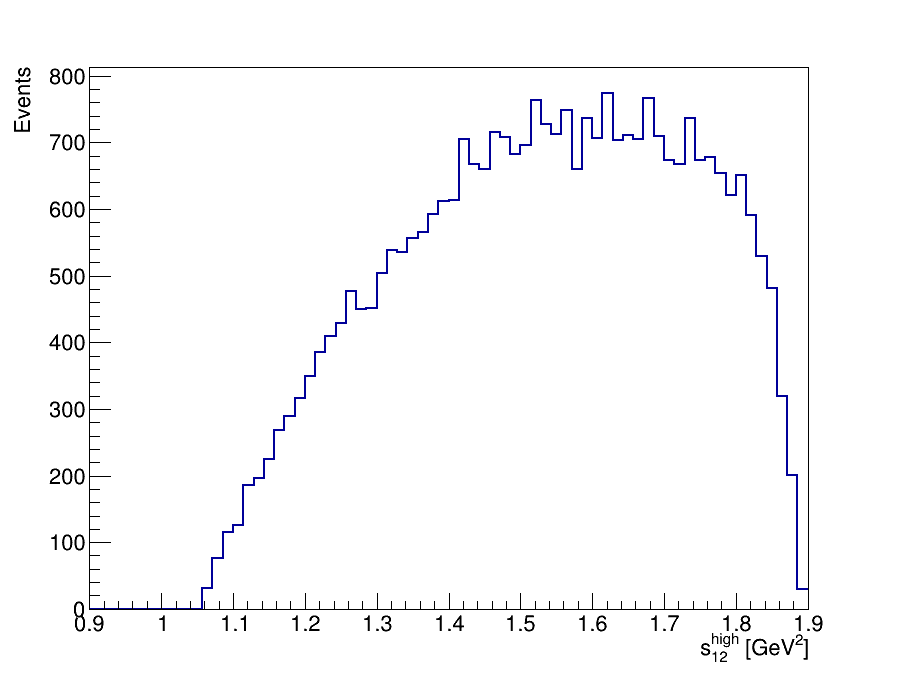
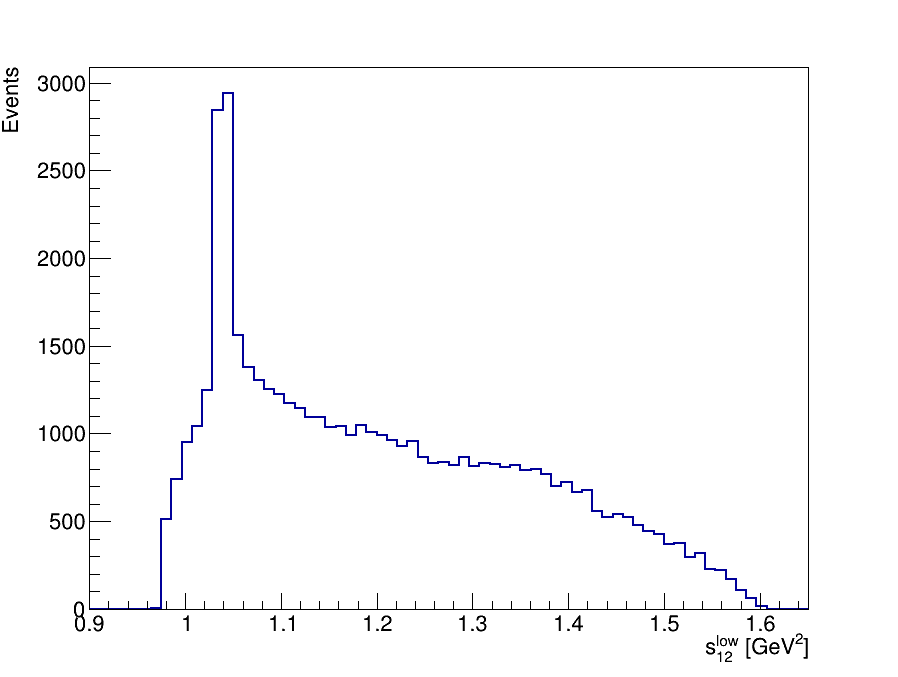
Thank you!
LHCb Summer Students Presentations 2021
By Sebastian Ordoñez



