Advanced RAG Techniques with LlamaIndex

2024-04-16 Unstructured Data Meetup
What are we talking about?
- What is RAG?
- What is LlamaIndex
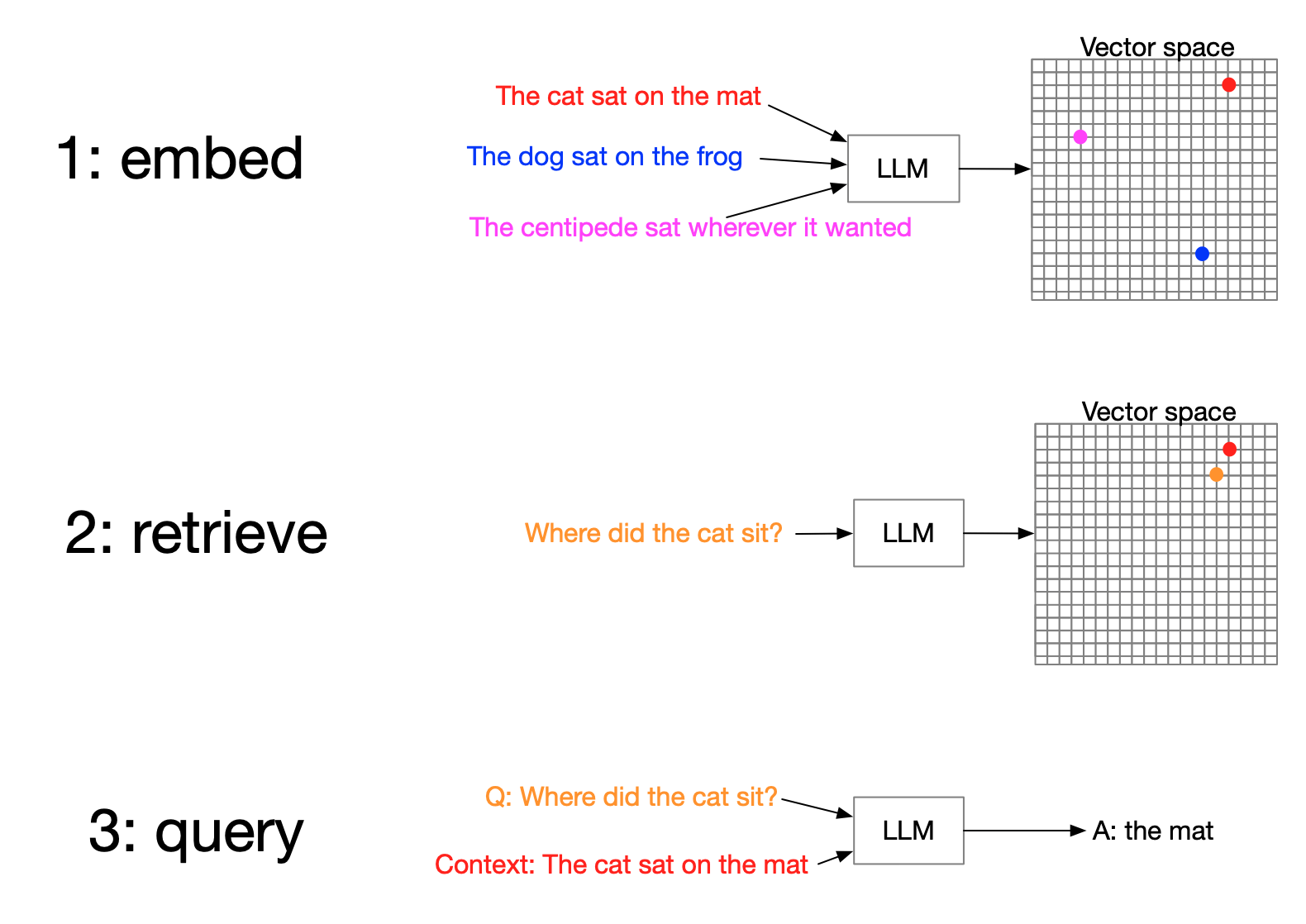
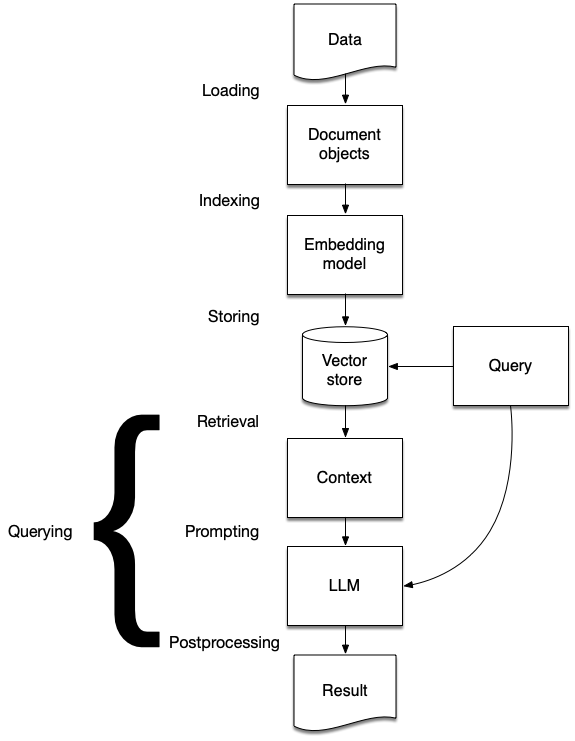
- The stages of RAG
- Ingestion
- Indexing
- Storing
- Querying
- Advanced querying strategies x7
- Getting into production
RAG recap
- Retrieve most relevant data
- Augment query with context
- Generate response
A solution to limited context windows
You have to be selective
and that's tricky
Accuracy
RAG challenges:
Faithfulness
RAG challenges:
Recency
RAG challenges:
Provenance
RAG challenges:
How do we do RAG?
1. Keyword search
How do we do RAG?
2. Structured queries
How do we do RAG?
3. Vector search
Vector embeddings
Turning words into numbers
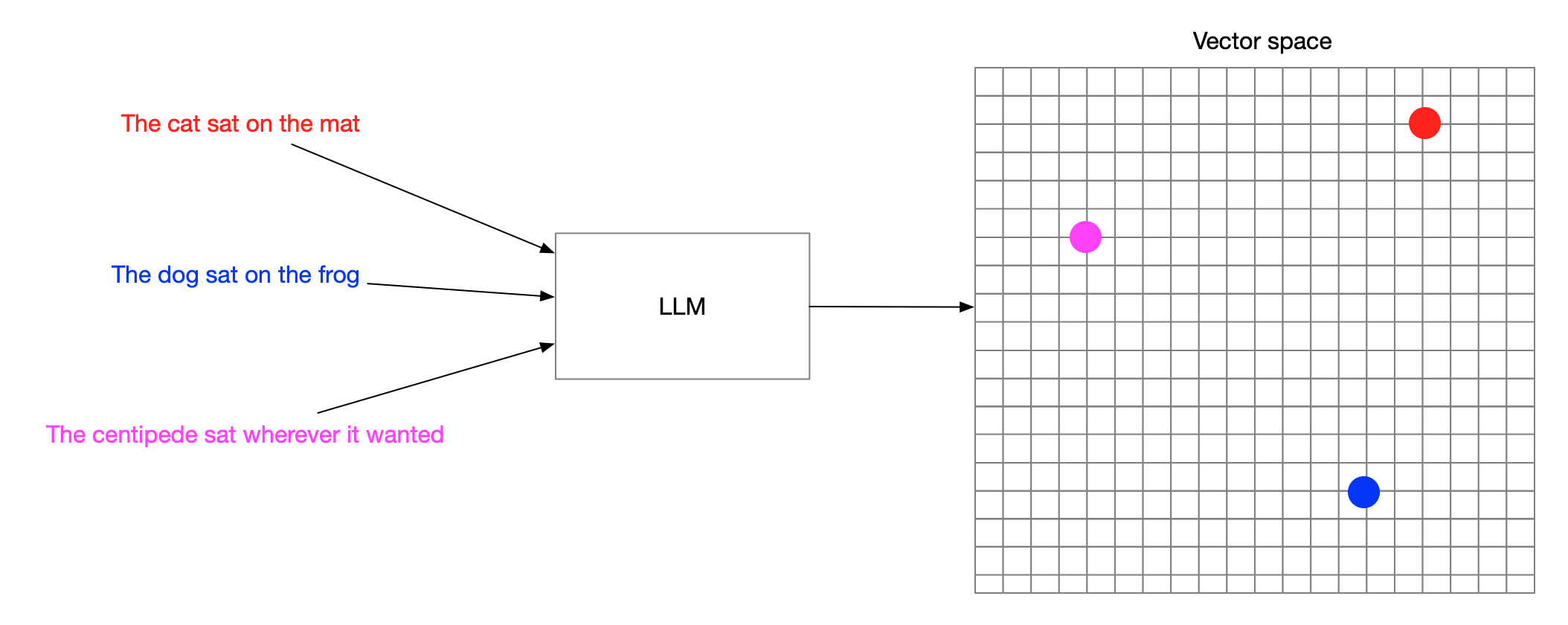
Search by meaning
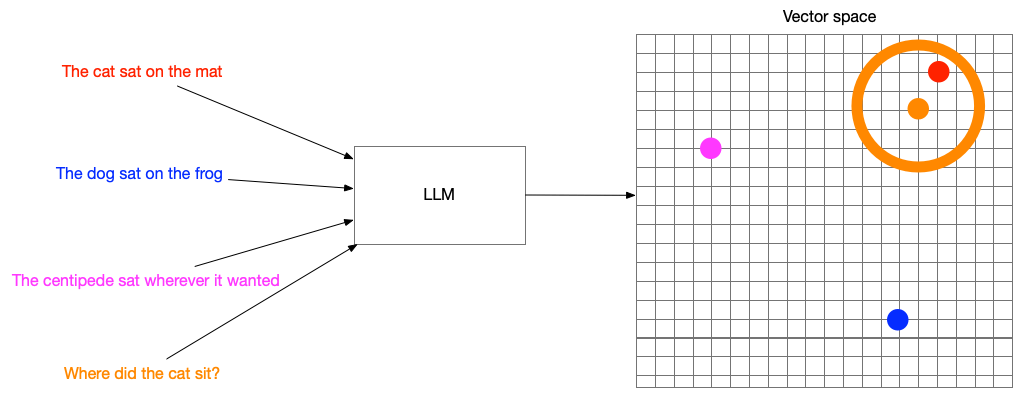
What is LlamaIndex?
- OSS libraries in Python and TypeScript
- LlamaParse - PDF parsing as a service
- LlamaCloud - managed ingestion service
Supported LLMs
5 line starter
documents = SimpleDirectoryReader("./data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("What's up?")
print(response)LlamaHub
LlamaParse
part of LlamaCloud
from llama_parse import LlamaParse
from llama_index.core import SimpleDirectoryReader
parser = LlamaParse(
result_type="markdown"
)
file_extractor = {".pdf": parser}
reader = SimpleDirectoryReader(
"./data",
file_extractor=file_extractor
)
documents = reader.load_data()Supported embedding models
- OpenAI
- Langchain
- CohereAI
- Qdrant FastEmbed
- Gradient
- Azure OpenAI
- Elasticsearch
- Clarifai
- LLMRails
- Google PaLM
- Jina
- Voyage
...plus everything on Hugging Face!
Supported Vector databases
- Apache Cassandra
- Astra DB
- Azure Cognitive Search
- Azure CosmosDB
- BaiduVector DB
- ChatGPT Retrieval Plugin
- Chroma
- DashVector
- Databricks
- Deeplake
- DocArray
- DuckDB
- DynamoDB
- Elasticsearch
- FAISS
- Jaguar
- LanceDB
- Lantern
- Metal
- MongoDB Atlas
- MyScale
- Milvus / Zilliz
- Neo4jVector
- OpenSearch
- Pinecone
- Postgres
- pgvecto.rs
- Qdrant
- Redis
- Rockset
- Simple
- SingleStore
- Supabase
- Tair
- TiDB
- TencentVectorDB
- Timescale
- Typesense
- Upstash
- Weaviate
Advanced query strategies
SubQuestionQueryEngine
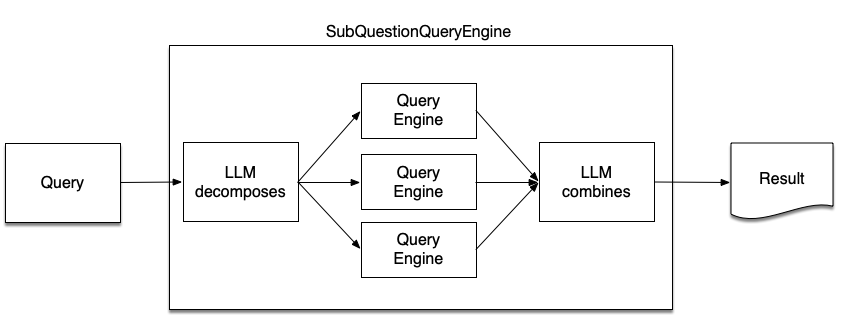
Problems with precision
Small-to-big retrieval
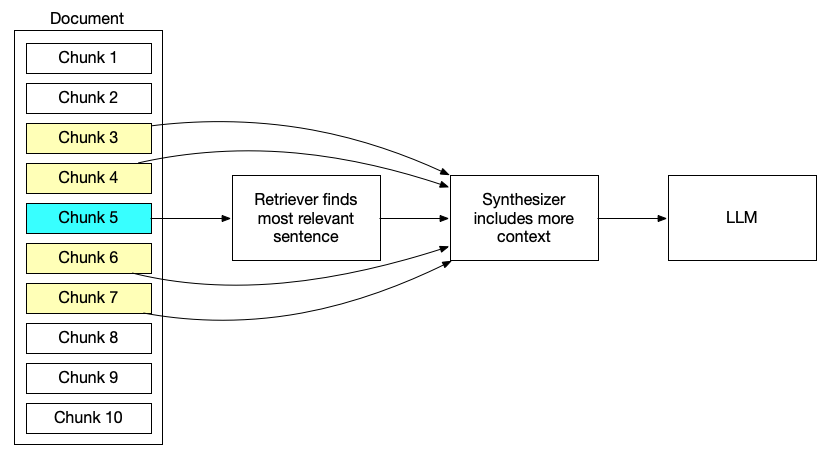
Precision through preprocessing
Metadata support
- Apache Cassandra
- Astra DB
- Azure AI Search
- BaiduVector DB
- Chroma
- DashVector
- Databricks
- Deeplake
- DocArray
- DuckDB
- Elasticsearch
- Qdrant
- Redis
- Simple
- SingleStore
- Supabase
- Tair
- TiDB
- TencentVectorDB
- Timescale
- Typesense
- Weaviate
- Jaguar
- LanceDB
- Lantern
- Metal
- MongoDB Atlas
- MyScale
- Milvus / Zilliz
- OpenSearch
- Pinecone
- Postgres
- pgvecto.rs
Hybrid Search
Hybrid search support
- Azure Cognitive Search
- BaiduVector DB
- DashVector
- Elasticsearch
- Jaguar
- Lantern
- MyScale
- OpenSearch
- Pinecone
- Postgres
- pgvecto.rs
- Qdrant
- TencentVectorDB
- Weaviate
Text to SQL
Multi-document agents
SECinsights.ai
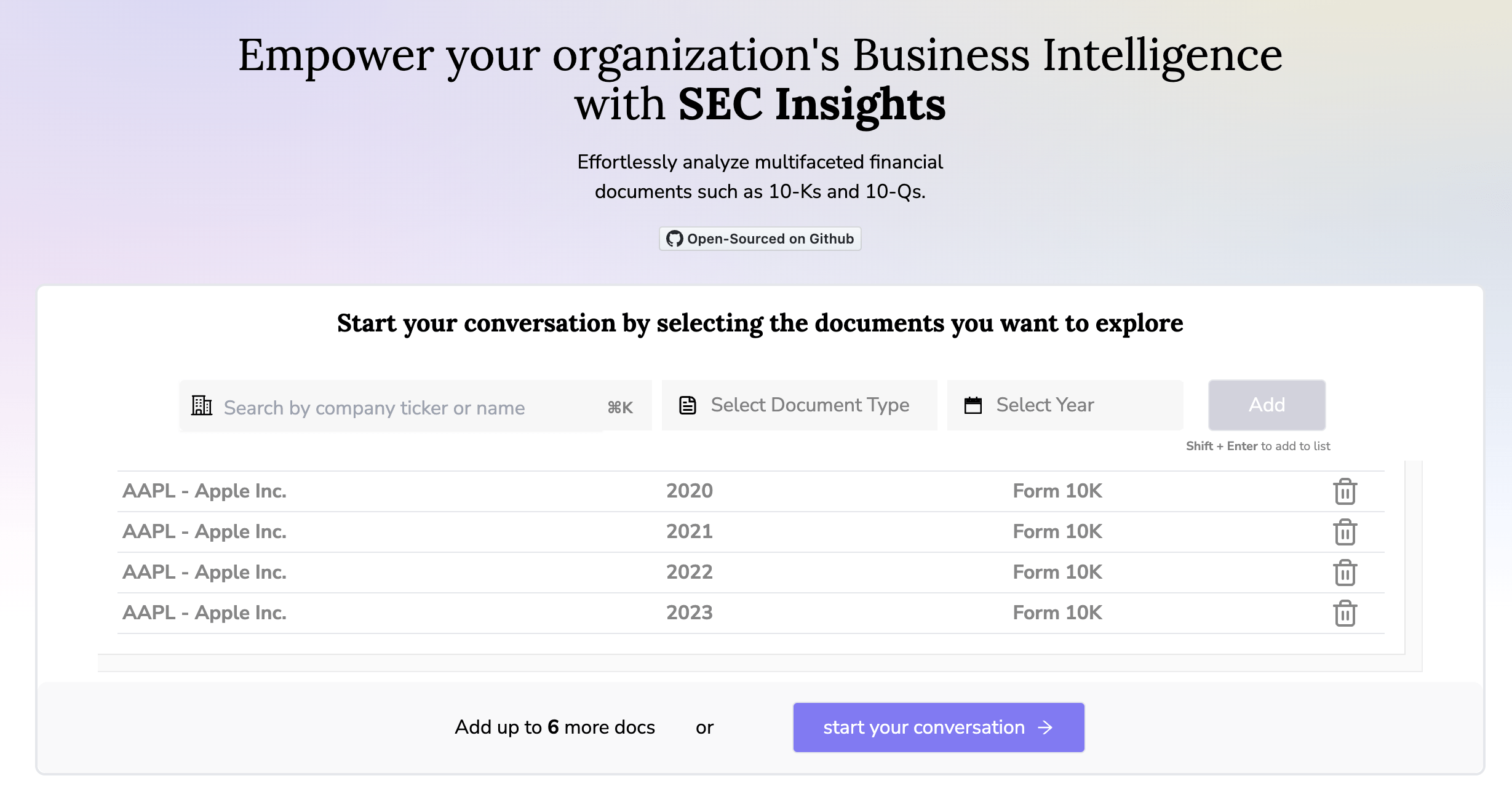
Composability
"2024 is the year of LlamaIndex in production"
– Shawn "swyx" Wang, Latent.Space podcast
npx create-llama
What next?
Follow me on Twitter: @seldo
Advanced RAG techniques lightning talk
By Laurie Voss



