Scratch slides for deeplearning.ai

2024-02-29 AGI Builders meetup
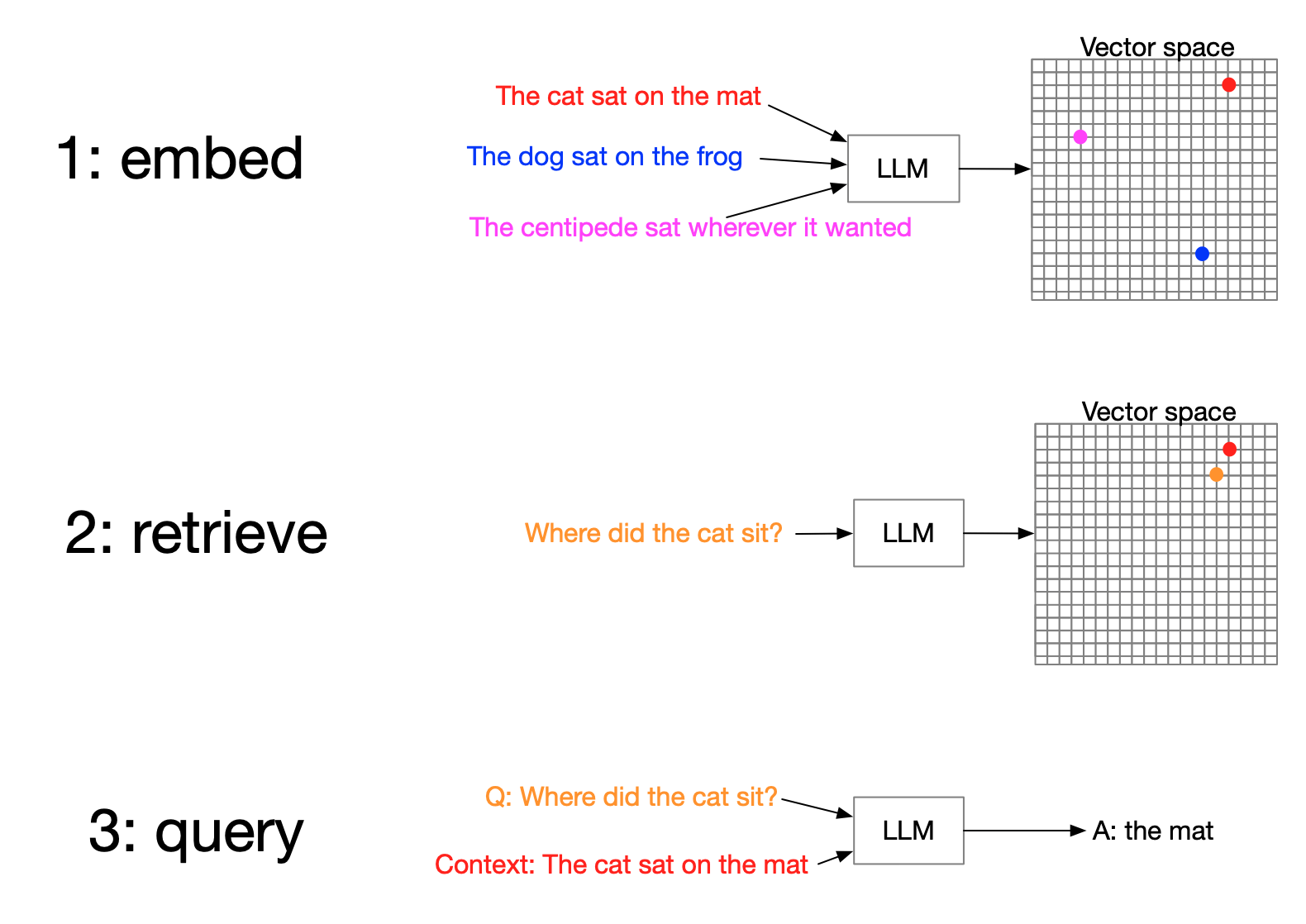
RAG recap
- Retrieve most relevant data
- Augment query with context
- Generate response
A solution to limited context windows
You have to be selective
and that's tricky
Vector embeddings
Turning words into numbers
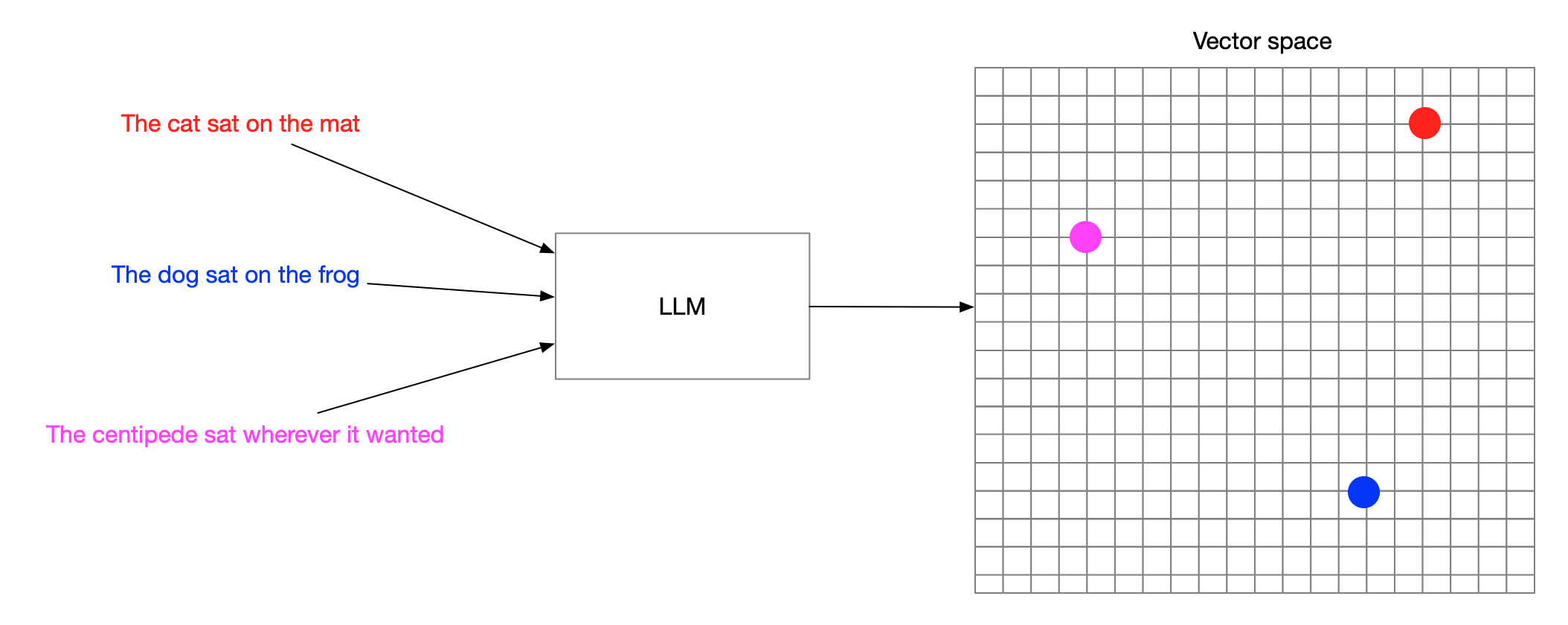
Search by meaning
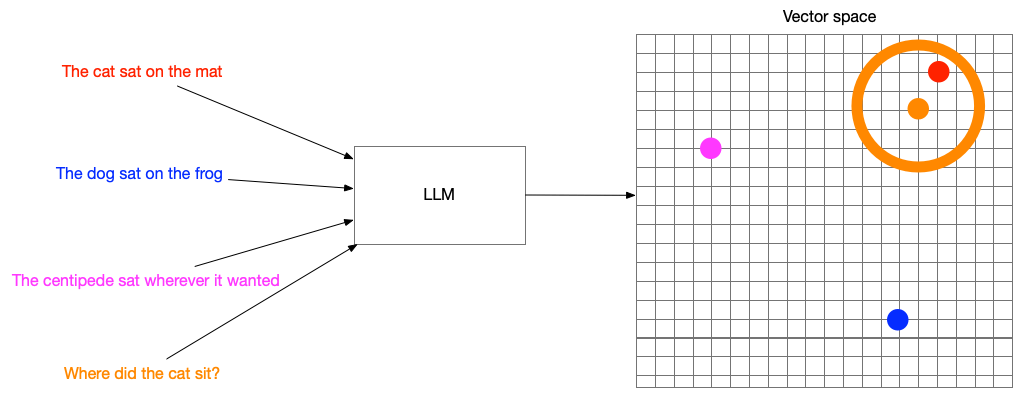
Hybrid approaches
What is LlamaIndex?
- OSS libraries in Python and TypeScript
- LlamaParse - PDF parsing as a service
- LlamaCloud - managed ingestion service
Supported LLMs
Basic ingestion
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)LlamaHub
Loading
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)Ingestion pipeline
# create the pipeline with transformations
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=25, chunk_overlap=0),
TitleExtractor(),
OpenAIEmbedding(),
]
)
# run the pipeline
nodes = pipeline.run(
documents=SimpleDirectoryReader("data").load_data()
)
index = VectorStoreIndex(nodes)Ingestion caching
# save
pipeline.persist("./pipeline_storage")
# load and restore state
new_pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=25, chunk_overlap=0),
TitleExtractor(),
],
)
new_pipeline.load("./pipeline_storage")
# will run instantly due to the cache
nodes = pipeline.run(
documents=SimpleDirectoryReader("data").load_data()
)
index = VectorStoreIndex(nodes)Supported embedding models
- OpenAI
- Langchain
- CohereAI
- Qdrant FastEmbed
- Gradient
- Azure OpenAI
- Elasticsearch
- Clarifai
- LLMRails
- Google PaLM
- Jina
- Voyage
...plus everything on Hugging Face!
VectorStoreIndex
KnowledgeGraphIndex
Supported Vector databases
- Apache Cassandra
- Astra DB
- Azure Cognitive Search
- Azure CosmosDB
- ChatGPT Retrieval Plugin
- Chroma
- DashVector
- Deeplake
- DocArray
- DynamoDB
- Elasticsearch
- FAISS
- LanceDB
- Lantern
- Metal
- MongoDB Atlas
- MyScale
- Milvus / Zilliz
- Neo4jVector
- OpenSearch
- Pinecone
- Postgres
- pgvecto.rs
- Qdrant
- Redis
- Rockset
- SingleStore
- Supabase
- Tair
- TencentVectorDB
- Timescale
- Typesense
- Weaviate
Querying
We don't talk about prompting (much)
See prompts
query_engine = index.as_query_engine()
prompts_dict = query_engine.get_prompts()Modify prompts
# shakespeare!
qa_prompt_tmpl_str = (
"Context information is below.\n"
"---------------------\n"
"{context_str}\n"
"---------------------\n"
"Given the context information and not prior knowledge, "
"answer the query in the style of a Shakespeare play.\n"
"Query: {query_str}\n"
"Answer: "
)
qa_prompt_tmpl = PromptTemplate(qa_prompt_tmpl_str)
query_engine.update_prompts(
{"response_synthesizer:text_qa_template": qa_prompt_tmpl}
)Basic querying
query_engine = index.as_query_engine()
response = query_engine.query(
"What is the capital of South Dakota?"
)
print(response)Configure retriever
index = VectorStoreIndex.from_documents(documents)
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=5,
)
response_synthesizer = get_response_synthesizer(
response_mode="tree_summarize",
)
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
)
response = query_engine.query(
"What is the capital of South Dakota?"
)
print(response)Configure synthesizer
index = VectorStoreIndex.from_documents(documents)
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=5,
)
response_synthesizer = get_response_synthesizer(
response_mode="tree_summarize",
)
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
)
response = query_engine.query(
"What is the capital of South Dakota?"
)
print(response)Create query engine
index = VectorStoreIndex.from_documents(documents)
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=5,
)
response_synthesizer = get_response_synthesizer(
response_mode="tree_summarize",
)
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
)
response = query_engine.query(
"What is the capital of South Dakota?"
)
print(response)Advanced query strategies
SubQuestionQueryEngine
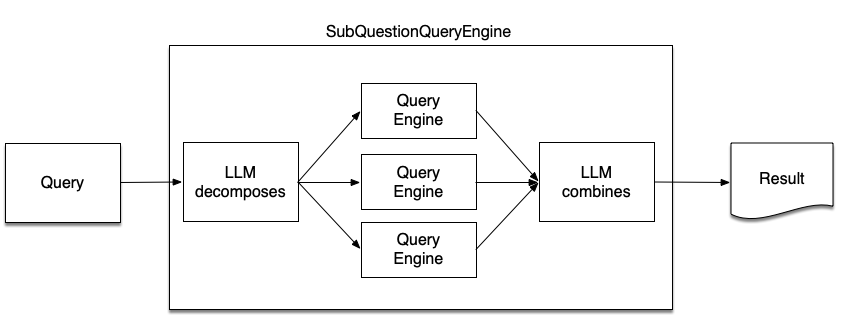
SubQuestionQueryEngine
# setup base query engine as tool
query_engine_tools = [
QueryEngineTool(
query_engine=simple_query_engine,
metadata=ToolMetadata(
name="pg_essay",
description="Paul Graham essay on What I Worked On",
),
),
]
query_engine = SubQuestionQueryEngine.from_defaults(
query_engine_tools=query_engine_tools
)Problems with precision
Small-to-big retrieval
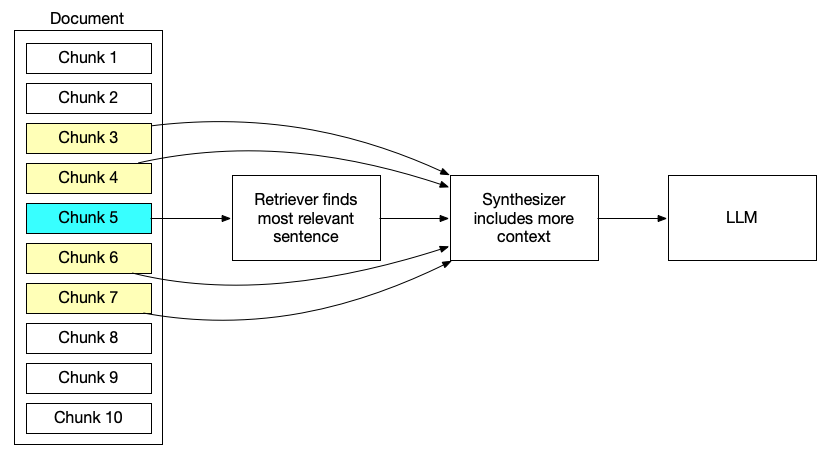
Small-to-big retrieval
query_engine = index.as_query_engine(
similarity_top_k=2,
node_postprocessors=[
MetadataReplacementPostProcessor(target_metadata_key="window")
],
)
response = query_engine.query(
"What happened on August 3rd?"
)
print(response)Precision through preprocessing
Metadata filtering
query_engine = index.as_query_engine(
filters=MetadataFilters(
filters=[ExactMatchFilter(key="year", value="2021")]
)
)
response = query_engine.query(
"What was the annual profit in 2021?"
)
print(response)Auto-retrieval
vector_store_info = VectorStoreInfo(
content_info="Brief summary of a movie",
metadata_info=[
MetadataInfo(
name="year",
description="The year the movie was released",
type="integer",
),
MetadataInfo(
name="director",
description="The name of the movie director",
type="string",
),
],
)
retriever = VectorIndexAutoRetriever(
index, vector_store_info=vector_store_info
)Metadata support
- Apache Cassandra
- Astra DB
- Chroma
- DashVector
- Deeplake
- DocArray
- Elasticsearch
- LanceDB
- Lantern
- Metal
- MongoDB Atlas
- MyScale
- Milvus / Zilliz
- OpenSearch
- Pinecone
- Postgres
- pgvecto.rs
- Qdrant
- Redis
- Simple
- SingleStore
- Supabase
- Tair
- TencentVectorDB
- Timescale
- Typesense
- Weaviate
Hybrid Search
Hybrid search
query_engine = index.as_query_engine(
vector_store_query_mode="hybrid",
similarity_top_k=2,
alpha=0.5
)
response = query_engine.query(
"What did the author do growing up?",
)Hybrid search support
- Azure Cognitive Search
- Elasticsearch
- Lantern
- MyScale
- Pinecone
- Postgres
- pgvecto.rs
- TencentVectorDB
- Weaviate
Complex document strategies
PandasQueryEngine
reader = PyMuPDFReader()
table_dfs = #...parse tables into pandas structures...
df_query_engines = [
PandasQueryEngine(table_df)
for table_df in table_dfs
]IndexNodes
# define index nodes
summaries = [
(
"This node provides information about the world's richest billionaires"
" in 2023"
),
(
"This node provides information on the number of billionaires and"
" their combined net worth from 2000 to 2023."
),
]
df_nodes = [
IndexNode(text=summary, index_id=f"pandas{idx}")
for idx, summary in enumerate(summaries)
]
df_id_query_engine_mapping = {
f"pandas{idx}": df_query_engine
for idx, df_query_engine in enumerate(df_query_engines)
}Sub-Retriever
doc_nodes = service_context.node_parser.get_nodes_from_documents(docs)
vector_index = VectorStoreIndex(doc_nodes + df_nodes)
vector_retriever = vector_index.as_retriever(similarity_top_k=1)RecursiveRetriever
recursive_retriever = RecursiveRetriever(
"vector",
retriever_dict={"vector": vector_retriever},
query_engine_dict=df_id_query_engine_mapping,
)
response_synthesizer = get_response_synthesizer()
query_engine = RetrieverQueryEngine.from_args(
recursive_retriever, response_synthesizer=response_synthesizer
)
response = query_engine.query(
"What's the net worth of the second richest billionaire in 2023?"
)
Text to SQL
SQLDatabase
engine = create_engine("sqlite:///:memory:")
sql_database = SQLDatabase(
engine,
include_tables=["city_stats"]
)Querying SQLDatabase
query_engine = NLSQLTableQueryEngine(
sql_database=sql_database,
tables=["city_stats"],
)
query_str = "Which city has the highest population?"
response = query_engine.query(query_str)SQLTableRetrieverQueryEngine
table_node_mapping = SQLTableNodeMapping(sql_database)
table_schema_objs = [
(SQLTableSchema(table_name="city_stats"))
]
obj_index = ObjectIndex.from_objects(
table_schema_objs,
table_node_mapping,
VectorStoreIndex,
)
query_engine = SQLTableRetrieverQueryEngine(
sql_database, obj_index.as_retriever(similarity_top_k=1)
)Manually add table metadata
city_stats_text = (
"This table gives information regarding the population and country of a"
" given city. The user will query with codewords, where 'foo' corresponds"
" to population and 'bar'corresponds to city."
)
table_node_mapping = SQLTableNodeMapping(sql_database)
table_schema_objs = [
(SQLTableSchema(table_name="city_stats", context_str=city_stats_text))
]Multi-document agents
SECinsights.ai
Create query engines
documents = SimpleDirectoryReader("2020").load_data()
index2020 = VectorStoreIndex.from_documents(documents)
query_engine_2020 = index2020.as_query_engine()
documents = SimpleDirectoryReader("2021").load_data()
index2021 = VectorStoreIndex.from_documents(documents)
query_engine_2021 = index2021.as_query_engine()
documents = SimpleDirectoryReader("2022").load_data()
index2022 = VectorStoreIndex.from_documents(documents)
query_engine_2022 = index2022.as_query_engine()Define tools
query_engine_tools = [
QueryEngineTool(
query_engine=query_engine_2020,
metadata=ToolMetadata(
name="2020_facts_tool",
description=(
"Contains facts about filings "
"about the company from the year 2020"
),
),
),
# ... etc ...
]Define agent
function_llm = OpenAI(model="gpt-4")
agent = OpenAIAgent.from_tools(
query_engine_tools,
llm=function_llm,
system_prompt=f"""\
You are a specialized agent designed to answer queries about financial filings.
You must ALWAYS use at least one of the tools provided when answering a question; do NOT rely on prior knowledge.\
""",
)Composability
"2024 is the year of LlamaIndex in production"
– Shawn "swyx" Wang, Latent.Space podcast
npx create-llama
LlamaIndex in production
- Datastax
- OpenBB
- Springworks
- Gunderson Dettmer
- Jasper
- Replit
- Red Hat
- Clearbit
- Berkeley
- W&B
- Instabase
- Adyen
Case study:
Gunderson Dettmer

Recap
- What LlamaIndex is
- Orchestration
- LlamaParse
- LlamaCloud
- A registry of software
- A path to production
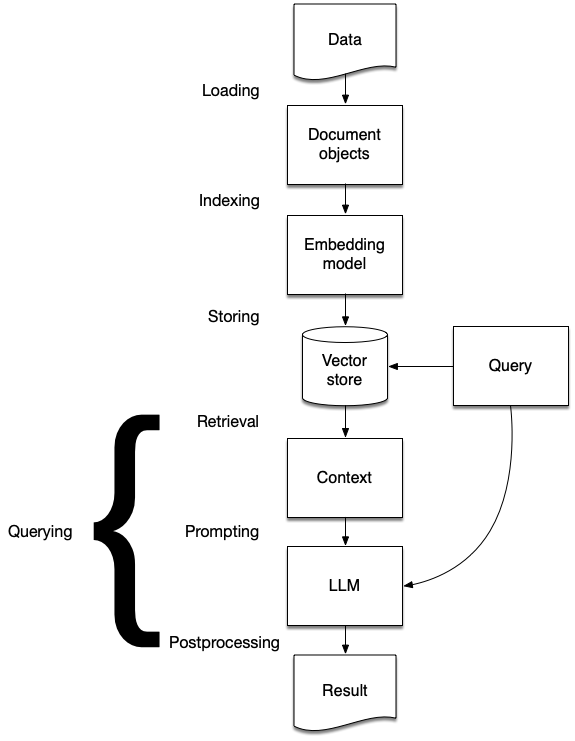
- Stages of RAG
- Ingestion
- Indexing
- Storing
- Querying
Advanced retrieval strategies
- SubQuestionQueryEngine
- Small-to-big retrieval
- Metadata filtering
- Hybrid search
- Recursive retrieval
- Text-to-SQL
- Multi-document agents
What next?
Follow me on twitter: @seldo
Scratch slides for DeepLearning
By Laurie Voss



