Enterprise Retrieval-Augmented Generation with LlamaIndex

2024-02-08 Streamlit at GitHub
What are we talking about?
- RAG recap
- Enterprise challenges of RAG
- How do we RAG?
- The stages of RAG
- How LlamaIndex helps
- Looking forward
RAG recap
- Retrieve most relevant data
- Augment query with context
- Generate response
A solution to limited context windows
You have to be selective
and that's tricky
Accuracy
Enterprise challenges of RAG:
Faithfulness
Enterprise challenges of RAG:
Recency
Enterprise challenges of RAG:
Provenance
Enterprise challenges of RAG:
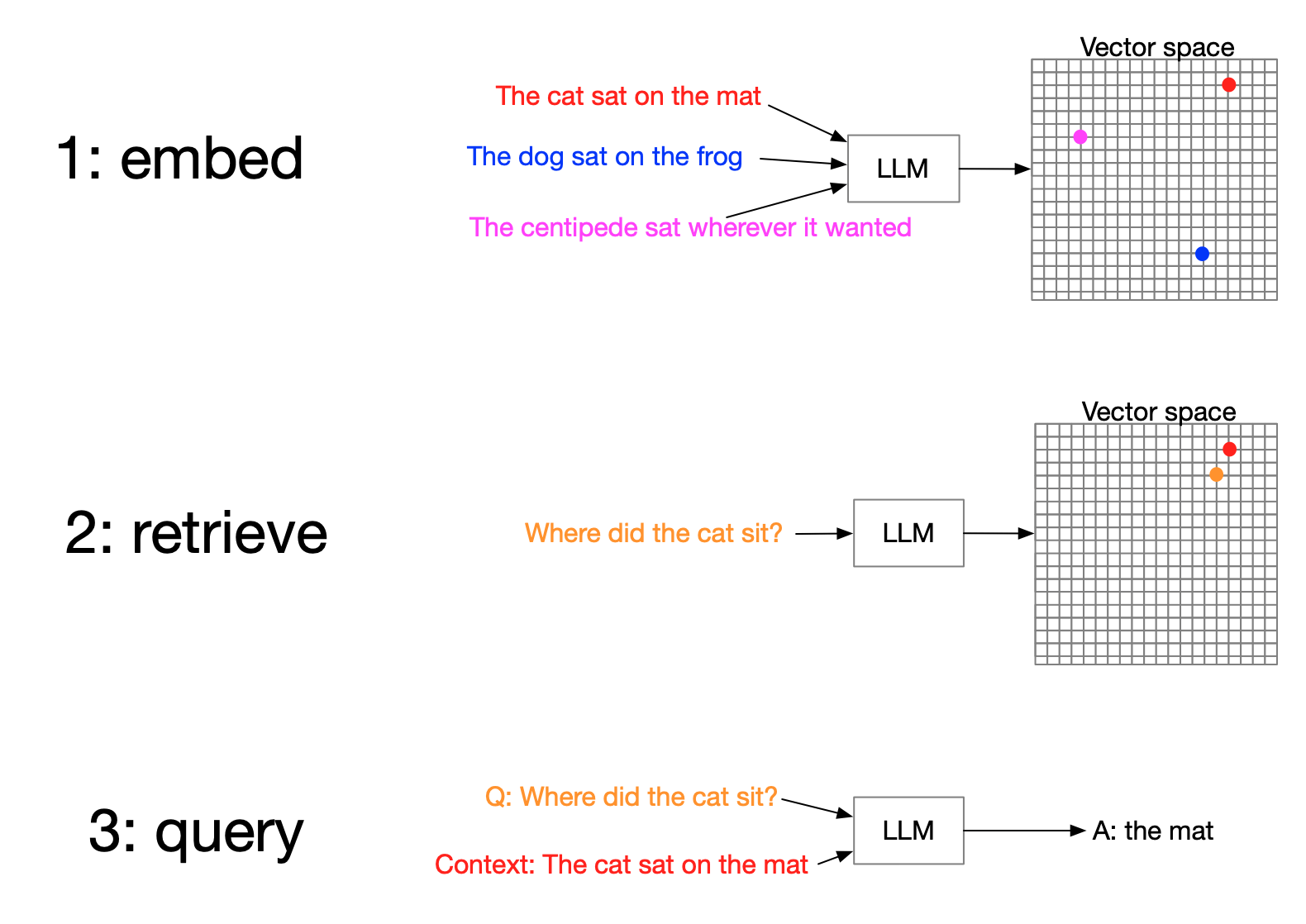
How do we do RAG?
1. Keyword search
How do we do RAG?
2. Structured queries
How do we do RAG?
3. Vector search
Vector embeddings
Turning words into numbers
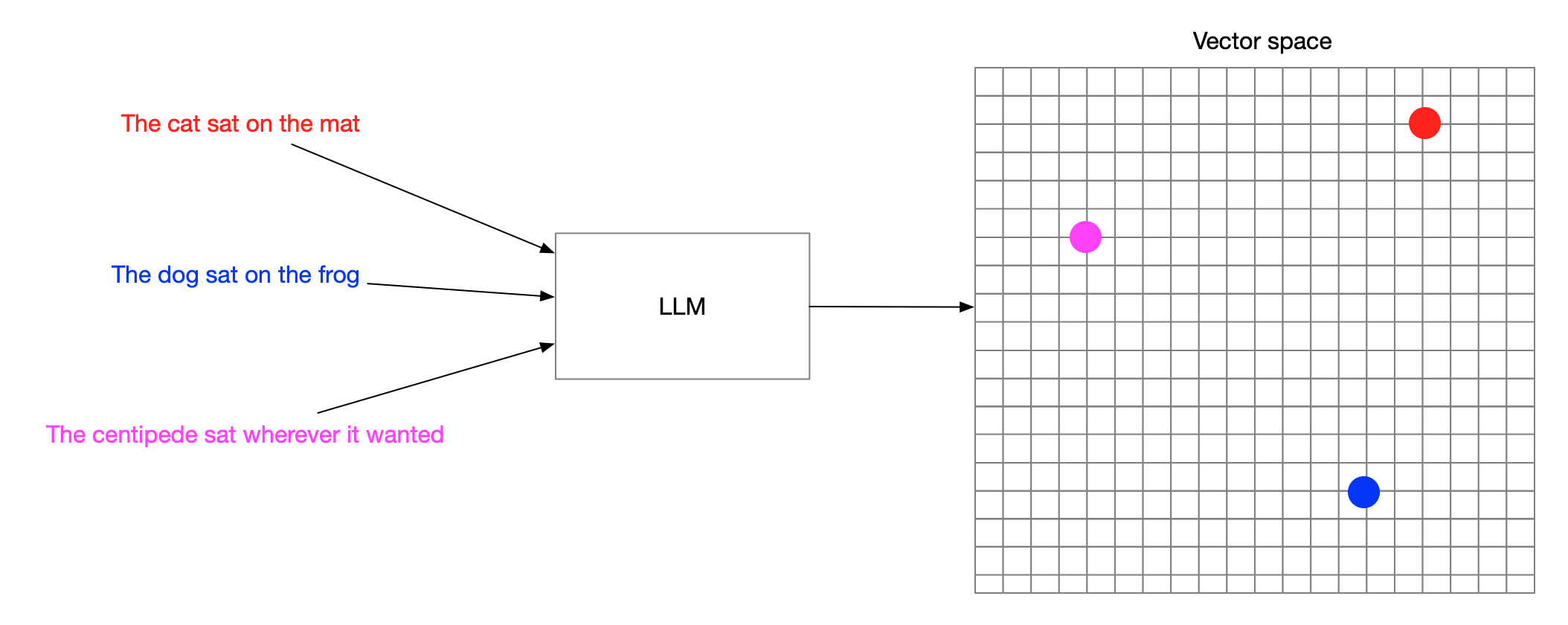
Search by meaning
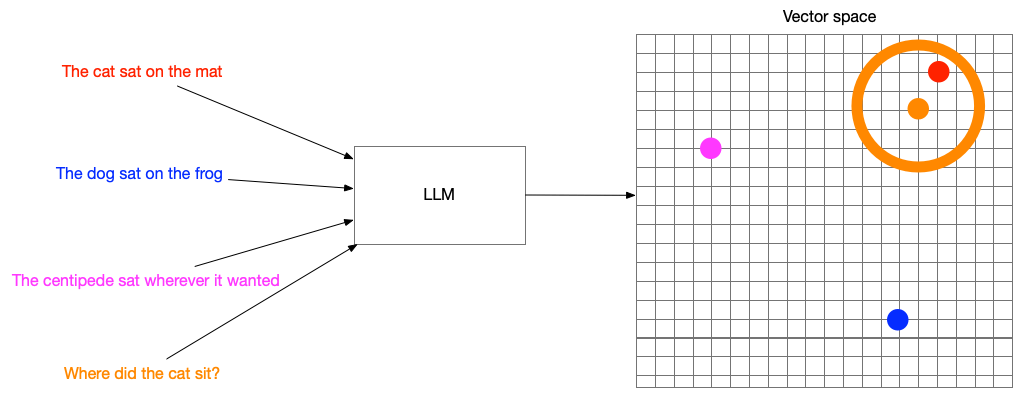
Hybrid approaches

Supported LLMs
LlamaHub

Ingestion pipeline
Supported embedding models
- OpenAI
- Langchain
- CohereAI
- Qdrant FastEmbed
- Gradient
- Azure OpenAI
- Elasticsearch
- Clarifai
- LLMRails
- Google PaLM
- Jina
- Voyage
...plus everything on Hugging Face!
Supported Vector databases
- Apache Cassandra
- Astra DB
- Azure Cognitive Search
- Azure CosmosDB
- ChatGPT Retrieval Plugin
- Chroma
- DashVector
- Deeplake
- DocArray
- DynamoDB
- Elasticsearch
- FAISS
- LanceDB
- Lantern
- Metal
- MongoDB Atlas
- MyScale
- Milvus / Zilliz
- Neo4jVector
- OpenSearch
- Pinecone
- Postgres
- pgvecto.rs
- Qdrant
- Redis
- Rockset
- SingleStore
- Supabase
- Tair
- TencentVectorDB
- Timescale
- Typesense
- Weaviate
Retrieval
Agentic strategies
That's a lot of stuff!
from llama_index import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)Let's do it in 5 lines of code:
npx create-llama
Create Llama Templates
SECinsights.ai
LlamaBot
LlamaHub (again)
"2024 is the year of LlamaIndex in production"
– Shawn "swyx" Wang, Latent.Space podcast
LlamaIndex in production
- Datastax
- OpenBB
- Springworks
- Gunderson Dettmer
- Jasper
- Replit
- Red Hat
- Clearbit
- Berkeley
- W&B
- Instabase
Case study:
Gunderson Dettmer

Recap
Retrieve, Augment, Generate
- Challenges:
- Accuracy
- Faithfulness
- Recency
- Provenance
- The stages of RAG:
- Loading
- Indexing
- Storing
- Retrieval
- Synthesis
- Processing
What now?
Follow me on twitter: @seldo
Enterprise RAG with LlamaIndex
By Laurie Voss



