Retrieval-Augmented Generation with LlamaIndex
and Azure Cosmos DB

2024-01-09 Azure Cosmos DB User Group
Who is this guy?
What are we talking about?
- What is AI?
- What is LlamaIndex?
- Retrieval-Augmented Generation (RAG)
- RAG with Azure Cosmos DB
- 7 advanced RAG strategies
What is AI?
Machine Learning (ML)
AI = ML + Marketing
Large Language Models (LLMs)
Are LLMs
"completing prompts" or "thinking"?

Retrieval-Augmented Generation (RAG)
Context
Selection
Hallucinations
Provenance
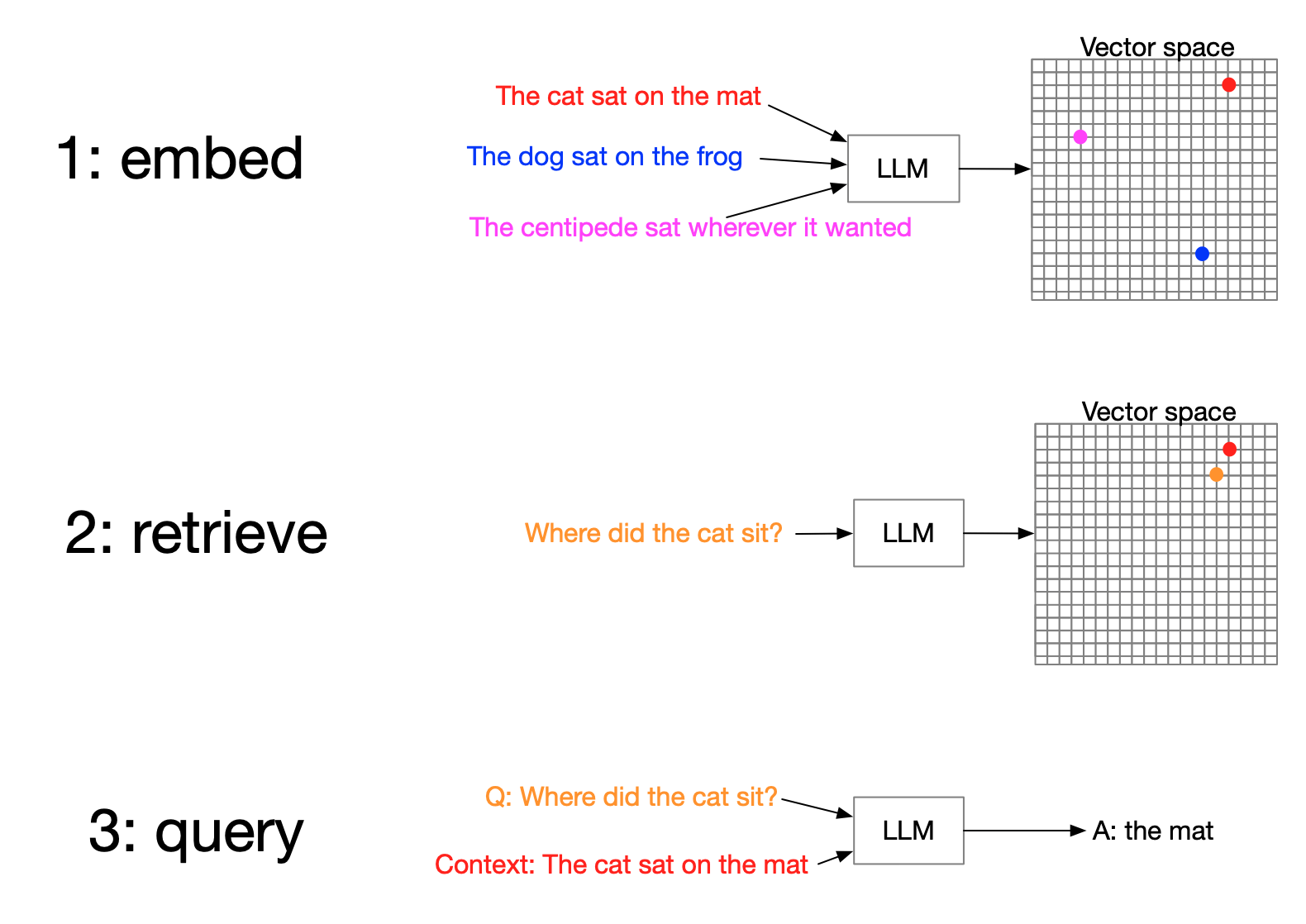
RAG
Retrieve context
Augment prompt
Generate answer
Vector embeddings
Turning words into numbers
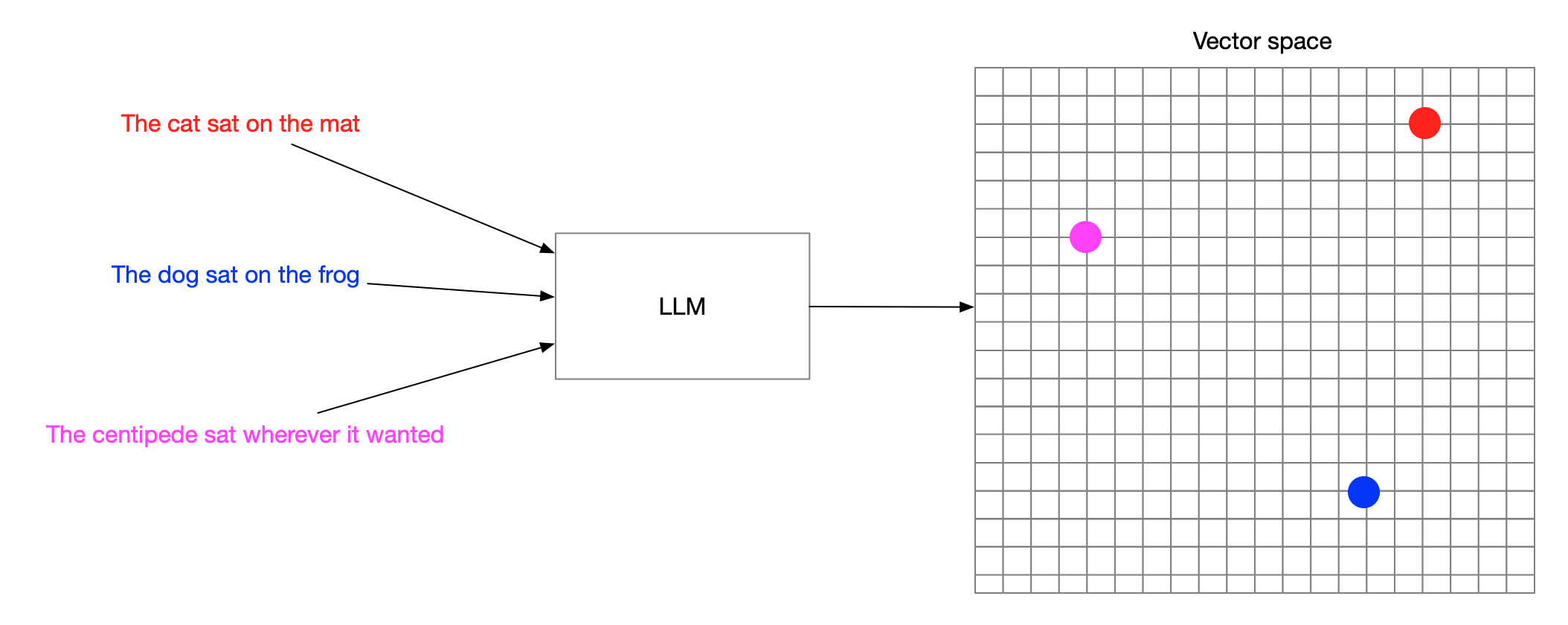
Search by meaning
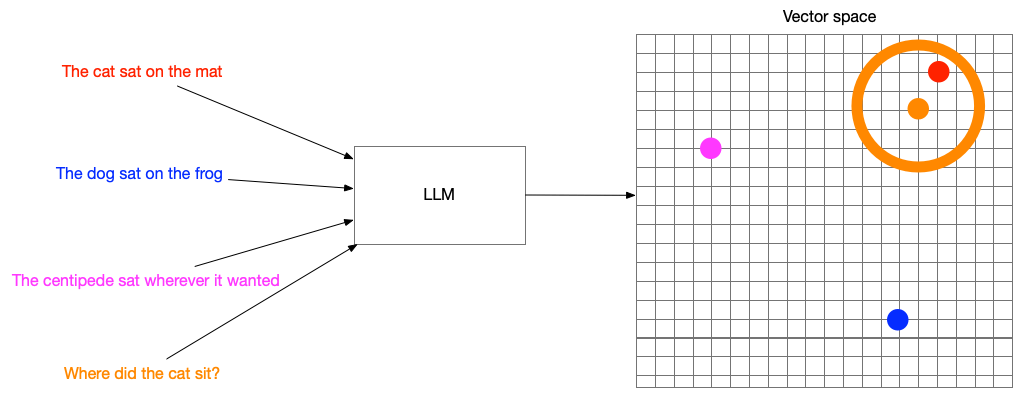

What is LlamaIndex?
LlamaHub
- Data loaders
- Agent tools
- Llama packs
- Llama datasets
npx create-llama
Supported LLMs
Supported Vector databases
- Apache Cassandra
- Astra DB
- Azure Cognitive Search
- Azure CosmosDB
- ChatGPT Retrieval Plugin
- Chroma
- DashVector
- Deeplake
- DocArray
- DynamoDB
- Elasticsearch
- FAISS
- LanceDB
- Lantern
- Metal
- MongoDB Atlas
- MyScale
- Milvus / Zilliz
- Neo4jVector
- OpenSearch
- Pinecone
- Postgres
- pgvecto.rs
- Qdrant
- Redis
- Simple
- SingleStore
- Supabase
- Tair
- TencentVectorDB
- Timescale
- Typesense
- Weaviate
LlamaIndex is the batteries-included framework
Get started in 6 lines
from llama_index import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(reponse)Get started in 6 lines
from llama_index import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(reponse)Get started in 6 lines
from llama_index import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(reponse)Get started in 6 lines
from llama_index import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(reponse)Get started in 6 lines
from llama_index import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(reponse)Azure Cosmos DB demo repo
Architecture

Architecture
Architecture

vCore Cluster creation





Import data
json_file = 'tinytweets.json'
# Load environment variables from local .env file
from dotenv import load_dotenv
load_dotenv()
import os
import json
from pymongo.mongo_client import MongoClient
# Load the tweets from a local file
with open(json_file, 'r') as f:
tweets = json.load(f)
# Create a new client and connect to the server
client = MongoClient(os.getenv('MONGODB_URI'))
db = client[os.getenv("MONGODB_DATABASE")]
collection = db[os.getenv("MONGODB_COLLECTION")]
# Insert the tweets into mongo
collection.insert_many(tweets)Load
query_dict = {}
reader = SimpleMongoReader(uri=os.getenv("MONGODB_URI"))
documents = reader.load_data(
os.getenv("MONGODB_DATABASE"),
os.getenv("MONGODB_COLLECTION"),
field_names=["full_text"],
query_dict=query_dict
)Index
# Create a new client and connect to the server
client = MongoClient(os.getenv("MONGODB_URI"))
# create Azure Cosmos as a vector store
store = AzureCosmosDBMongoDBVectorSearch(
client,
db_name=os.getenv('MONGODB_DATABASE'),
collection_name=os.getenv('MONGODB_VECTORS'),
index_name=os.getenv('MONGODB_VECTOR_INDEX')
)Store
storage_context = StorageContext.from_defaults(vector_store=store)
index = VectorStoreIndex.from_documents(
documents, storage_context=storage_context,
show_progress=True
)Query!
query_engine = index.as_query_engine(similarity_top_k=20)
response = query_engine.query("What does the author think of web frameworks?")
print(response)
Going beyond
naive RAG
Why?
- Scale
- Precision of provenance
- Complexity
SubQuestionQueryEngine
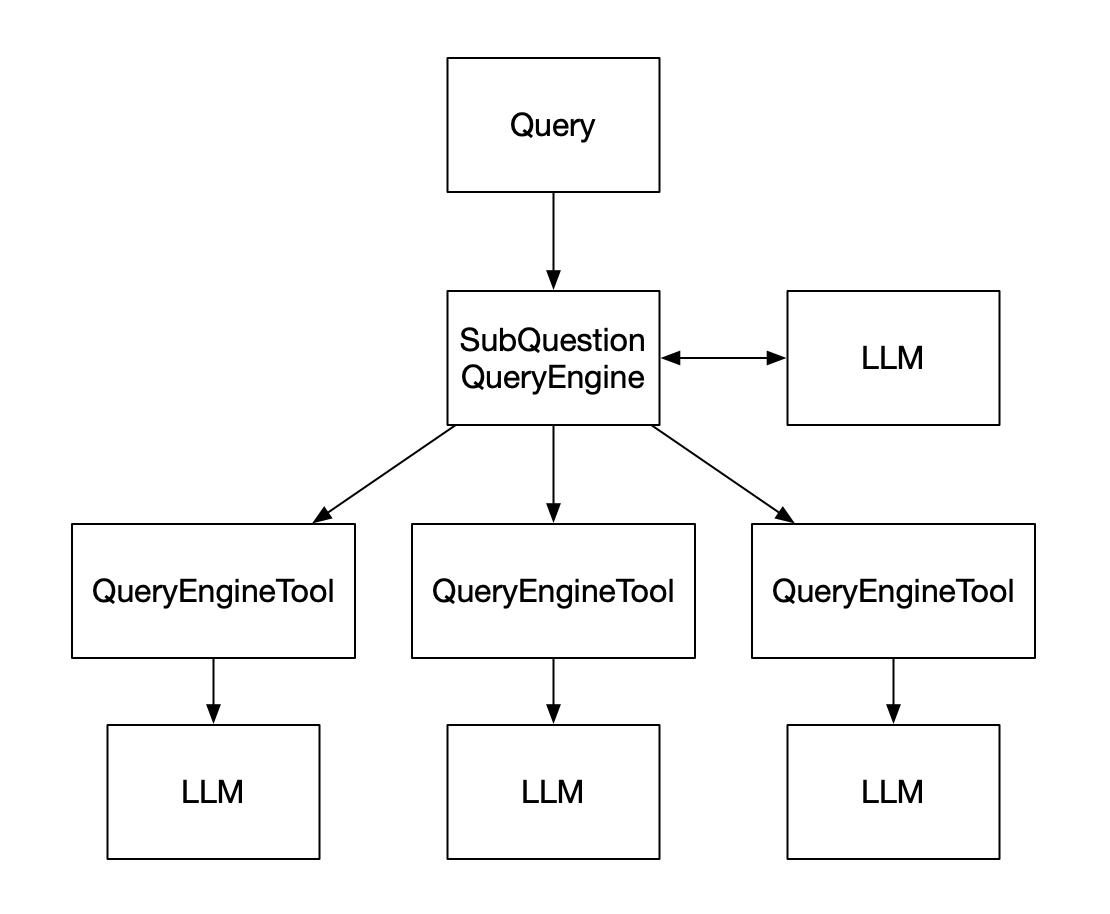
Small-to-big retrieval

Metadata filtering
Hybrid search
Recursive retrieval

Text to SQL
Multi-document agents
SECinsights.ai
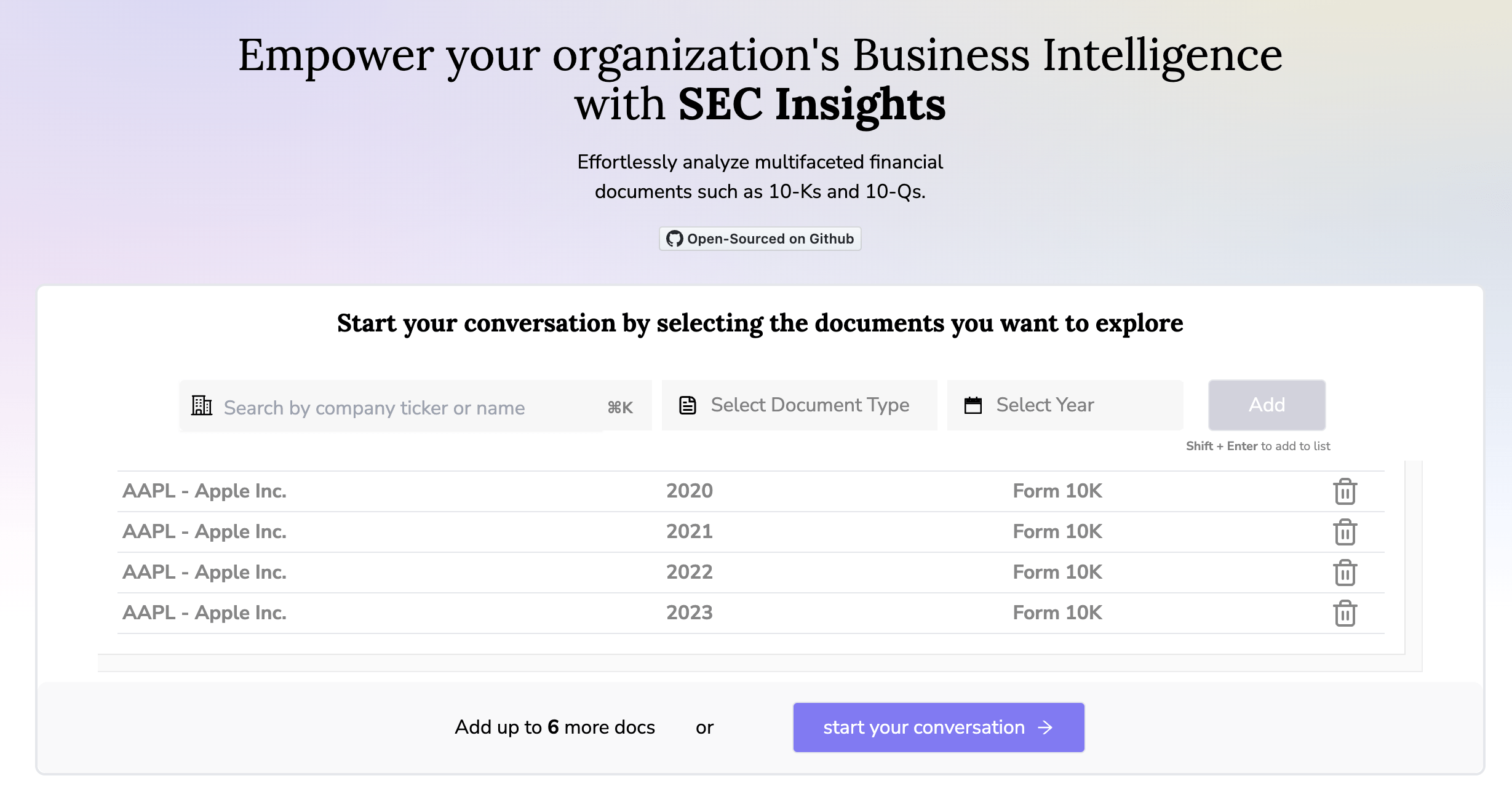
Recap
- What is AI?
- What is RAG?
- Vector search
- What is LlamaIndex?
- LlamaHub
- create-llama
- Building RAG with Azure Cosmos DB
- 7x Advanced query strategies
What next?
Follow me on twitter: @seldo
RAG with Azure Cosmos DB
By Laurie Voss



