




Stéphane Fréchette
Cloud Solution Architect - Data Platform @Microsoft. Databases | Data Engineering | Analytics. Drums, good food, fine wine. I speak for myself ♥ != endorse
Stéphane Fréchette
twitter: @sfrechette | blog: stephanefrechette.com
TimescaleDB
TimescaleDB is an open-source time-series database optimized for fast ingest and complex queries. It speaks "full SQL" and is correspondingly easy to use like a traditional relational database, yet scales in ways previously reserved for NoSQL databases.
TimescaleDB
TimescaleDB
TimescaleDB
TimescaleDB
"Time-series data is data that collectively represents how a system, process, or behaviour changes over time."
TimescaleDB
TimescaleDB utilizes a "wide-table" data model, which is quite common in the world of relational databases. This makes Timescale somewhat different than most other time-series databases, which typically use a "narrow-table" model.
TimescaleDB
TimescaleDB is implemented as an extension on PostgreSQL, which means that a Timescale database runs within an overall PostgreSQL instance. The extension model allows the database to take advantage of many of the attributes of PostgreSQL such as reliability, security, and connectivity to a wide range of third-party tools.
TimescaleDB
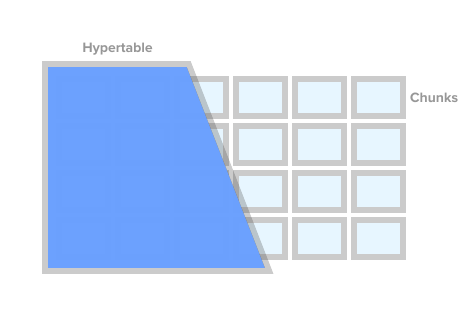
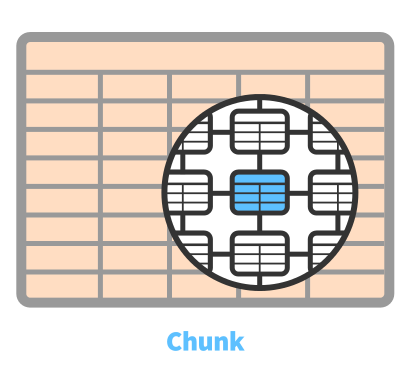
TimescaleDB exposes what look like singular tables, called hypertables, that are actually an abstraction or a virtual view of many individual tables holding the data, called chunks.
TimescaleDB
TimescaleDB
TimescaleDB
The current open-source release of TimescaleDB only supports single-node deployments. Of note is that the single-node version of TimescaleDB has been benchmarked to over 10-billion-row hypertables on commodity machines without a loss in insert performance.
*clustered deployments (in development)
TimescaleDB
TimescaleDB offers three key benefits over vanilla PostgreSQL or other traditional RDBMSs for storing time-series data:
TimescaleDB
TimescaleDB
TimescaleDB includes new functions for time-oriented analytics, including some of the following:
TimescaleDB
SELECT time_bucket('3 hours', time) AS period
asset_code,
first(price, time) AS opening, last(price, time) AS closing,
max(price) AS high, min(price) AS low
FROM prices
WHERE time > NOW() - interval '7 days'
GROUP BY period, asset_code
ORDER BY period DESC, asset_code;
Last and first aggregates: These functions allow you to get the value of one column as ordered by another. For example, last(temperature, time) will return the latest temperature value based on time within a group (e.g., an hour).
TimescaleDB
SELECT time_bucket('1 day', time) AS day,
asset_code,
last(price, time_recorded)
FROM prices
WHERE time > '2017-01-01'
GROUP BY day, asset_code
ORDER BY day DESC, asset_code;TimescaleDB allows efficient deletion of old data at the chunk level, rather than at the row level, via its drop_chunks functionality.
TimescaleDB
SELECT drop_chunks(interval '7 days', 'conditions');TimescaleDB
TimescaleDB
Compared to general NoSQL databases (e.g., MongoDB, Cassandra) or even more specialized time-oriented ones (e.g., InfluxDB, KairosDB), TimescaleDB provides both qualitative and quantitative differences:
TimescaleDB
If any of the following is true, you might not want to use TimescaleDB:
TimescaleDB
Web: https://www.timescale.com/
Blog: https://blog.timescale.com/
Github: https://github.com/timescale/timescaledb/
Slack: https://slack-login.timescale.com/
Twitter: @timescaledb
Podcasts:
TimescaleDB
By Stéphane Fréchette
TimescaleDB [April 2018]

