
2018
Agenda
- Introduction to Numpy and PyTorch
- Why use PyTorch
- Pitfalls
- What is missing in PyTorch
- What is coming up in PyTorch
Numpy
-
ndarray -n-dimensional array of homogenous data
- Fast routines for
ndarray
eg linear algebra, statistical operations, Fourier transforms etc
- Tools for integrating C/C++ and Fortran code
- Many benefits over inbuilt Python sequences
import numpy as np
given_list = [24, 12, 57]
new_array = np.array(given_list)
print(type(new_array))
# <class 'numpy.ndarray'>import numpy as np
given_list = [24, 12, 57]
new_array = np.array(given_list)
print(type(new_array))
# <class 'numpy.ndarray'>given_list = [24, 12, 57]
new_array = np.array(given_list)
print([x+3 for x in given_list])
# [27, 15, 60]
print(new_array+3)
# [27 15 60]
first_array = np.random.rand(128, 5)
second_array = np.random.rand(5, 128)
print(np.matmul(first_array, second_array))
'''
[[1.15351208 1.95227908 1.96715651 ... 1.98488703 1.2217091 2.22688756]
[1.29874346 1.74803279 1.89340905 ... 2.07696858 1.9904079 2.20042014]
...
[0.82158841 1.07577147 1.75924153 ... 1.68843334 1.36875145 1.2564471 ]
[1.42693331 2.52156631 2.39800496 ... 2.47794813 2.10389287 2.72979265]]
'''def square_python(num=100000):
squares = []
for i in range(1, num):
squares.append(i ** 2)
def square_numpy(num=100000):
squares = np.arange(1, num) ** 2%%timeit
square_python()
# 10 loops, best of 3: 38.6 ms per loop
%%timeit
square_numpy()
# 1000 loops, best of 3: 314 µs per loopPyTorch
- Open-sourced Machine Learning framework
- Development initiated at Facebook AI Research
PyTorch
- Tensor computation (like NumPy)
with strong GPU acceleration
- Deep neural networks
built on top of reverse mode
automatic differentiation
PyTorch
- Python-First
- Hybrid Front-End
- Distributed Training
- Ecosystem of solutions
PyTorch
- Tensor computation (like NumPy)
with strong GPU acceleration
-
torch
.Tensor is the counterpart to np.ndarray
- Much of the talk would focus on how to
augment Numpy with Pytorch (and vice-versa)
Creation Operations
-
Creation ops
api calls are very similar
shape = (2, 3)
print(np.ones(shape))
# [[1. 1. 1.]
# [1. 1. 1.]]Creation Operations
-
Creation ops
api calls are very similar
shape = (2, 3)
print(np.ones(shape))
# [[1. 1. 1.]
# [1. 1. 1.]]Creation Operations
-
Creation ops
api calls are very similar
shape = (2, 3)
#print(np.ones(shape))
print(torch.ones(shape))
# tensor([[1., 1., 1.],
# [1., 1., 1.]])Creation Operations
-
Creation ops
api calls are very similar
shape = (2, 3)
#print(np.ones(shape))
print(torch.ones(shape))
# tensor([[1., 1., 1.],
# [1., 1., 1.]])Creation Operations
shape = (3, 3)
x = 2 * np.ones(shape)
y = np.eye(shape[0])
print(x+y)
Creation Operations
shape = (3, 3)
x = 2 * np.ones(shape)
y = np.eye(shape[0])
print(x+y)
x = 2 * torch.ones(shape)
y = torch.eye(shape[0])
print(x+y)
Creation Operations
shape = (3, 3)
x = 2 * np.ones(shape)
y = np.eye(shape[0])
print(x+y)
x = 2 * torch.ones(shape)
y = torch.eye(shape[0])
print(x+y)
Creation Operations
np.array([[1, 2], [3, 4]])
Creation Operations
np.array([[1, 2], [3, 4]])
torch.tensor([[1, 2], [3, 4]])PyTorch vs Numpy
Numpy supports two styles for variable assignment:
- Compute the value and assign to a variable using the `assignment` operator.
- Compute and assign the value to a variable using a function call.
Torch supports both as well
Numpy
shape = (3, 3)
x = 2 * np.ones(shape)
y = np.eye(shape[0])
y = np.add(x, y)
np.add(x, y, out=y)
Numpy
shape = (3, 3)
x = 2 * np.ones(shape)
y = np.eye(shape[0])
y = np.add(x, y)
np.add(x, y, out=y)
Numpy
shape = (3, 3)
x = 2 * np.ones(shape)
y = np.eye(shape[0])
y = np.add(x, y)
np.add(x, y, out=y)
PyTorch
shape = (3, 3)
x = 2 * torch.ones(shape)
y = torch.eye(shape[0])
y = torch.add(x, y)
torch.add(x, y, out=y)
PyTorch
shape = (3, 3)
x = 2 * torch.ones(shape)
y = torch.eye(shape[0])
y = torch.add(x, y)
torch.add(x, y, out=y)
PyTorch vs Numpy
- Much of the `Tensor` operations in Torch have an API similar to their Numpy counterparts.
- Support for advanced indexing (along the lines of Numpy)
Advanced Indexing: Numpy
x = np.arange(10)
print(x[1:7:2])
# [1 3 5]
y = np.arange(35).reshape(5,7)
print(y[1:5:2,::3])
# [[ 7 10 13]
# [21 24 27]]Advanced Indexing: Torch
x = torch.arange(10)
print(x[1:7:2])
# tensor([1, 3, 5])
y = torch.arange(35).reshape(5,7)
print(y[1:5:2,::3])
# tensor([[ 7, 10, 13],
# [21, 24, 27]])Advanced Indexing: Numpy
x = np.arange(10,1,-1)
indexing_array = np.array([3,3,-3,8])
print(x[indexing_array])
# [7 7 4 2]
indexing_array = np.array([[1,1],[2,3]])
print(x[indexing_array])
# [[9 9]
# [8 7]]
Advanced Indexing: Torch
x = torch.arange(10,1,-1)
indexing_array = torch.tensor([3,3,-3,8])
print(x[indexing_array])
# tensor([7, 7, 4, 2])
indexing_array = torch.tensor([[1,1],[2,3]])
print(x[indexing_array])
# tensor([[9, 9],
# [8, 7]])PyTorch vs Numpy
Some Differences
| Numpy | Torch |
|---|---|
| axis | dim |
| copy | clone |
| np.expand_dims(x, 1) | x.unsqueeze(1) |
| tile | repeat |
PyTorch vs Numpy
np.sum(np_array, axis=1)
torch.sum(torch_array, dim=1)PyTorch vs Numpy
Some Differences
A more complete comparison is available at
https://github.com/shagunsodhani/pytorch-for-numpy-users
PyTorch vs Numpy
x = np.linspace(start=10.0, stop=20, num=5)
print(x)
# [10. 12.5 15. 17.5 20. ]
PyTorch vs Numpy
x = np.linspace(start=10.0, stop=20, num=5)
print(x)
# [10. 12.5 15. 17.5 20. ]
x = torch.linspace(start=10, end=20, steps=5)
print(x)
# tensor([10.0000, 12.5000, 15.0000, 17.5000, 20.0000])
PyTorch vs Numpy
x = np.linspace(start=10.0, stop=20, num=5)
print(x)
# [10. 12.5 15. 17.5 20. ]
x = torch.linspace(start=10, end=20, steps=5)
print(x)
# tensor([10.0000, 12.5000, 15.0000, 17.5000, 20.0000])
PyTorch vs Numpy
x = np.linspace(start=10.0, stop=20, num=5)
print(x)
# [10. 12.5 15. 17.5 20. ]
x = torch.linspace(start=10, end=20, steps=5)
print(x)
# tensor([10.0000, 12.5000, 15.0000, 17.5000, 20.0000])
Though the APIs are similar, PyTorch is NOT a drop-in replacement for Numpy.
We will later see that this is
not as bad as it sounds.
Why should I use PyTorch
GPU Acceleration
%%timeit
np.random.seed(1)
n = 10000
x = np.array(np.random.randn(n,n),
dtype = np.float32)
y = np.matmul(x, x)
# 1 loop, best of 3: 36.6 s per loop%%timeit
torch.manual_seed(1)
n = 10000
device = torch.device('cuda:0')
x = torch.rand(n, n,
dtype=torch.float32,
device=device)
y = torch.matmul(x, x)
# 10 loops, best of 3: 797 ms per loopThis is all good. But I dont want to rewrite my Numpy code into Torch code
Good News! You do not have to.
Numpy to PyTorch
- Numpy arrays can be EASILY converted into
Torch tensors
- Torch tensors can be EASILY converted into
Numpy arrays
Numpy to PyTorch
torch_array = torch.from_numpy(numpy_array)
PyTorch to Numpy
numpy_array = torch_array.numpy()PyTorch to Numpy
shape = (5, 3)
numpy_array = np.array(shape)
# Make a Numpy array
PyTorch to Numpy
shape = (5, 3)
numpy_array = np.array(shape)
# Make a Numpy array
torch_array = torch.from_numpy(numpy_array)
# Convert it into a Torch tensor
PyTorch to Numpy
shape = (5, 3)
numpy_array = np.array(shape)
# Make a Numpy array
torch_array = torch.from_numpy(numpy_array)
# Convert it into a Torch tensor
recreated_numpy_array = torch_array.numpy()
# Convert the Torch tensor into Numpy array
PyTorch to Numpy
shape = (5, 3)
numpy_array = np.array(shape)
# Make a Numpy array
torch_array = torch.from_numpy(numpy_array)
# Convert it into a Torch tensor
recreated_numpy_array = torch_array.numpy()
# Convert the Torch tensor into Numpy array
if (recreated_numpy_array == numpy_array).all():
print("Numpy -> Torch -> Numpy")Numpy + PyTorch
# Existing Numpy logic
#
# Move data to GPU
# Use GPUs for costly operations
# Move data back to Numpy
# Existing Numpy logicPyTorch on GPUs
- By default, tensors are created (and live) on
cpu
- They can be easily moved to a
gpu
-
Infact they can be easily moved betweengpus .
Tensors on GPUs
gpu_device = torch.device('cuda:0')
cpu_device = torch.device('cpu')
tensor_on_gpu = tensor.to(gpu_device)
tensor_on_cpu = tensor.to(cpu_device)PyTorch + Numpy
Some Pitfalls to look out for
Pitfall 1
numpy_array = np.array([1, 2, 3])
torch_array = torch.from_numpy(numpy_array)
torch_array[0] = -100
print(numpy_array[0])
# -100Pitfall 1
- When using from_numpy() the data is shared between Torch and Numpy.
- If you want to make a new copy, use Tensor()
Pitfall 1
numpy_array = np.array([1, 2, 3])
torch_array = torch.Tensor(numpy_array)
torch_array[0] = -100
print(numpy_array[0])
# 1Pitfall 2
- Whenever you move data to GPU, a new copy is created.
- Recommended: Move data to gpu once,
do all the computations
bring the data back to cpu
Pitfall 2
numpy_array = np.array([1, 2, 3])
torch_array = torch.from_numpy(numpy_array).to(gpu_device)
torch_array[0] = -100
print(numpy_array[0])
# 1Pitfall 3
torch_array = torch.tensor([1, 2, 3],
device = gpu_device)
numpy_array = torch_array.numpy()
# TypeError: can't convert CUDA tensor to
# numpy. Use Tensor.cpu() to copy the
# tensor to host memory first.Pitfall 3
torch_array = torch.tensor([1, 2, 3],
device = gpu_device)
numpy_array = torch_array
.to(cpu_device)
.numpy()
Pitfall 3
- Can not directly convert a gpu tensor to Numpy array.
- Recommended: Move the tensor to cpu
If it is already on cpu, to(cpu_device) is a no-op
I dont have fancy GPUs, would PyTorch be too slow for me?
- While I do not have any exhaustive benchmarks, I have not observed much difference between the performance of Numpy and PyTorch (on CPU).
- If you find a usecase which is much slower, you should file an issue. The core team is very responsive to these issue.
What about CuPy
- Drop-in replacement for Numpy (on GPUs)
- Very useful when you want "just" Numpy capabilities on a GPU
- Think of Numpy to CuPy as transition to a better hardware.
- PyTorch is a better choice when you want to have more powerful primitives (for machine learning) and the ability to access more powerful hardware.
Why should I use PyTorch
Other benefits of PyTorch
- Recall that PyTorch is more than a tensor manipulation library.
- It is a deep learning platform built around Numpy-like tensor abstraction.
-
If you use NumPy, then you know how to use PyTorch
- Along with tensors-on-gpu, PyTorch supports a whole suite of deep-learning tools with an extremely easy-to-use interface.
Other benefits of PyTorch
def gradient(w, x, y):
"""Compute gradient for Linear Regression"""
y_estimate = x.dot(w).squeeze()
error = (y.squeeze() - y_estimate)
gradient = -(1.0/len(x)) * error.dot(x)
return gradient
## Credits: https://www.cs.toronto.edu/~frossard/post/linear_regression/Other benefits of PyTorch
torch.nn.Linear(input_size, 1)Other benefits of PyTorch
Flexibility + low level control
PyTorch Ecosystem
What about other Deep Learning Frameworks
Other benefits of PyTorch
- Tensor can be easily converted into Nump array (and vice-versa)
- Hence it plays well with other libraries like scikit-learn, scipy etc.
- In some cases, wrappers exist
-
skorch: ScikitLearn + PyTorch
-
skorch: ScikitLearn + PyTorch
- The cool part is, we can use Scipy, Numpy etc for defining extensions in PyTorch
What is missing in PyTorch
- Note that there is no feature parity between PyTorch and Numpy
- Apis could differ in some cases (eg `axis` vs `dim`)
- Support for Sparse Tensors is limited for now
Where do I go from here
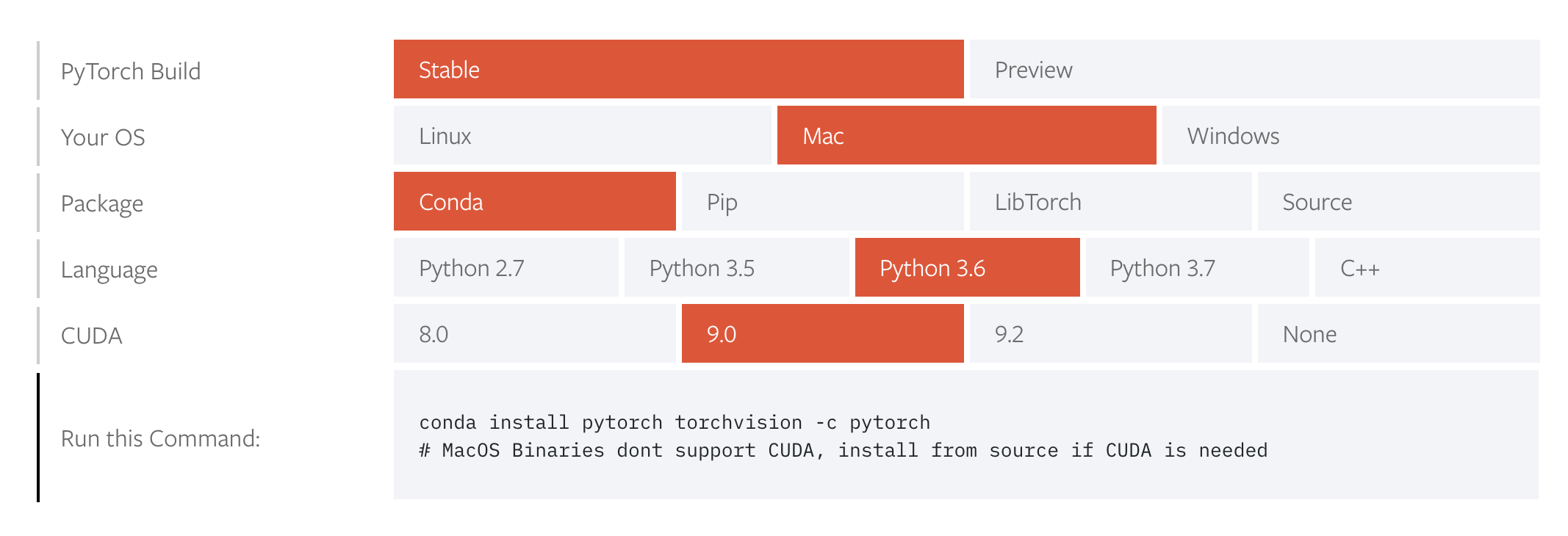
Where do I go from here

What is coming up
- First major release in December 2018: production ready PyTorch
- Close to Numpy: "expect to get closer and closer to NumPy’s API where appropriate"
- Distributed PyTorch: Already support a distributed package for TCP, MPI, Gloo and NCCL2
Community
https://github.com/pytorch/pytorch
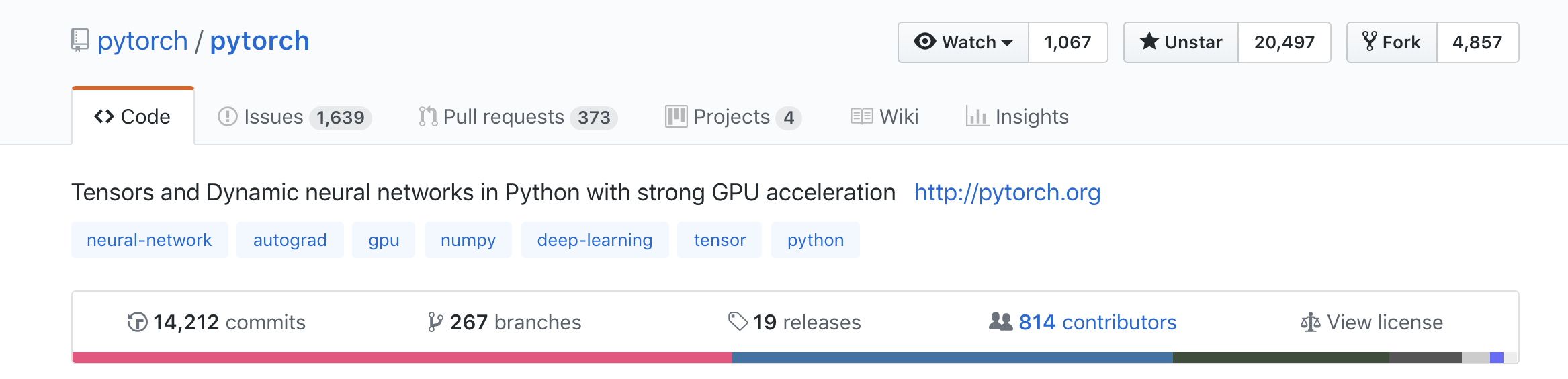
Community
https://discuss.pytorch.org/
Acknowledgements
- Adam Paszke (University of Warsaw)
References
- https://www.numpy.org
- https://pytorch.org
Thank You

Shagun Sodhani
Numpy To Torch
By Shagun Sodhani
Numpy To Torch
For PyCon Canada 2018



