From Zero to Hero -
The Npgsql Optimization Story

whoami
- Shay Rojansky
- Long-time Linux/open source developer/enthusiast (installed Slackware somewhere in 1994/5)
- Lead dev of Npgsql
- .NET driver for PostgreSQL (took over in 2012)
- Provider for Entity Framework Core
- Joining Microsoft's data access team in January
- Logistician for Doctors Without Borders (MSF)
whois Npgsql
- Open-source .NET driver for PostgreSQL
- Implements ADO.NET (System.Data.Common)
- Supports fully async (but also sync)
- Fully binary driver
- Fully-featured (PostgreSQL special types, data import/export API, notification support...)
Focus on high performance...
"Database drivers are boring"
- Everyone, including me in 2012
Perf in .NET Core 2.1 and Npgsql 4.0

TechEmpower Fortunes results, round 17
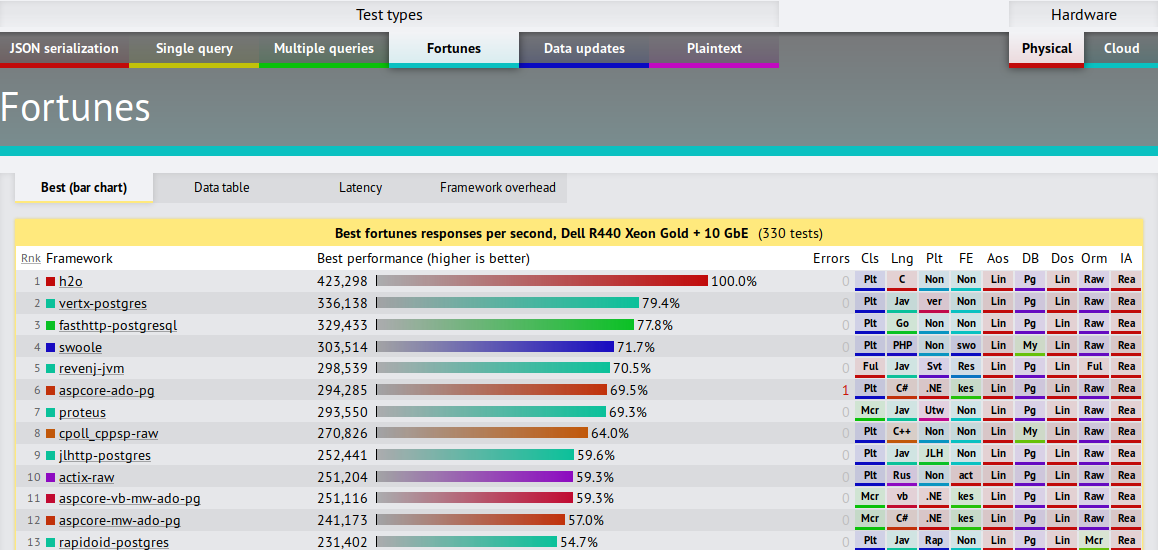
The Raw Numbers
| OS | .NET Core | Npgsql 3.2 RPS | Npgsql 4.0 RPS |
|---|---|---|---|
| Windows | 2.0 | 71,810 | 107,400 |
| Windows | 2.1 | 101,546 | 132,778 |
| Linux | 2.0 | 73,023 | 93,668 |
| Linux | 2.1 | 78,301 | 107,437 |
- On Windows, 3.2 -> 4.0 gives 50% boost
- .NET Core 2.0 -> 2.1 gives a further 24% (85% total)
- Linux perf is lower...
Topics
- Lock-free connection pool
- Async perf techniques
- Buffering / Network I/O
- Command preparation
Breadth rather than depth
Lock-Free Database Connection Pool
What is a DB connection pool?
- Physical DB connections are very expensive to create - especially in PostgreSQL (process spawned in the backend).
- If we open/close all the time, the app grinds to a halt.
- So the driver includes a pool.
- Pooled Open() and Close() must be very efficient (connection sometimes held for very short, e.g. to service one web request)
- It's also the one place where synchronization happens: once a connection is taken out there's no thread-safety.
Identifying Contention Bottlenecks
- Low local CPU usage (was only 91%)
- Network bandwidth far below saturation (10Gbps Ethernet, very little iowait)
- No resource starvation on the PostgreSQL side
- Profiler will show Monitor.Enter()
- Try reducing lock scopes if possible (already optimized)
Lock-Free Programming
- Lock-free programming means, well, no locking.
- All operations are interleaved, all the time, everywhere.
- "Interlocked" CPU instructions are used to perform complex operations atomically.
- It's really, really hard to get right.

Simple Rent
Connection[] _idle = new Connection[PoolSize];
public Connection Rent()
{
for (var i = 0; _idle.Length; i++)
{
// If the slot contains null, move to the next slot.
if (_idle[i] == null)
continue;
// If we saw a connector in this slot, atomically exchange it with a null.
// Either we get a connector out which we can use, or we get null because
// someone has taken it in the meantime. Either way put a null in its place.
var conn = Interlocked.Exchange(ref _idle[i], null);
if (conn != null)
return conn;
}
// No idle connection was found, create a new one
return new Connection(...);
}Simple Return
public void Return(Connection conn)
{
for (var i = 0; i < _idle.Length; i++)
if (Interlocked.CompareExchange(ref _idle[i], conn, null) == null)
return;
// No free slot was found, close the connection...
conn.Close();
}This simple implementation was used as a proof-of-concept.

Let's take it up a notch
- Since physical connections are very expensive, we need to enforce an upper limit (think multiple app instances, one DB backend).
- Once the max limit has been reached, wait until a connection is released.
- Release waiters in FIFO, otherwise some get starved.
- So add a waiting queue next to our idle list: if no idle conn was found, enqueue a TaskCompletionSource.
- When releasing, first check the waiting queue to release any pending attempts. Otherwise return to the idle list.
Two data structures, no locks
- One idle list, one waiting queue. By the time we finish updating one, the other may have changed.
- Example: rent attempt enters waiting queue, at the same time as a release puts a connection back in the idle list. Rent attempt waits forever.
- Need a way to have a single, atomically-modified state (how many busy, idle, waiting)
Atomically manipulate states
[StructLayout(LayoutKind.Explicit)]
internal struct PoolState
{
[FieldOffset(0)]
internal short Idle;
[FieldOffset(2)]
internal short Busy;
[FieldOffset(4)]
internal short Waiting;
[FieldOffset(0)]
internal long All;
}// Create a local copy of the pool state, in the stack
PoolState newState;
newState.All = _state.All;
// Modify it
newState.Idle--;
newState.Busy++;
// Commit the changes
_state.All = newState.All;Problem: we have to have multiple counters (idle, busy, waiting), and manipulate them atomically.
But two operations may be racing, and we lose a change...
Handling race conditions
var sw = new SpinWait();
while (true)
{
// Create a local copy of the pool state, in the stack
PoolState oldState;
oldState.All = Volatile.Read(ref _state.All); // Volatile prevents unwanted "optimization"
var newState = oldState;
// Modify it
newState.Idle--;
newState.Busy++;
// Try to commit the changes
if (Interlocked.CompareAndExchange(ref _state.All, newState.All, oldState.All) == oldState.All)
break;
// Our attempt to increment the busy count failed, Loop again and retry.
sw.SpinOnce();
}- This is how a lot of lock-free code looks like: try until success.
- SpinWait is a nice tool for spinning, and will automatically context switch after some time.
- Beware of the ABA problem!
Very subtle issues
- An open attempt creates a new connection
(idle == 0, total < max). - But a network error causes an exception. State has already been updated (busy++), need to decrement.
- But we already did busy++, so maybe busy == max. Someone may have gone into the waiting queue - so we need to un-wait them.

Conclusion

https://medium.com/@tylerneely/fear-and-loathing-in-lock-free-programming-7158b1cdd50c
8% perf increase
But probably the most dangerous 8% I've ever done.
No standard connection pool API
- Pooling is an internal concern of the provider, there's no user-facing API (unlike JDBC).
var conn = new NpgsqlConnection("Host=...");
conn.Open();- This imposes a lookup on every open - we need to get the pool for the given connection string. This is bad especially since an application typically has just one pool.
- Npgsql implements this very efficiently (iterate over list, do reference comparison). But a first-class pooling API would obviate this entirely.
No standard connection pool API
- A 1st-class pool API would allow us to take the pool out of the provider:
- One strong implementation
- Reuse across providers
- Different pooling strategies
- No need to lookup by connection string
- https://github.com/dotnet/corefx/issues/26714
Async Perf Tips
Avoid async-related allocations
- ValueTask allows us to avoid the heap allocation of a Task<T> when the async method completes synchronously.
- Not necessary if the method returns void, bool and some other values.
- Since 2.1, IValueTaskSource also allows us to eliminate the allocation when the method completes asynchronously. This is advanced.
Best async tip: avoid async
- Conventional wisdom is that for asynchronously-completing async methods, any async-related CPU overhead will be dominated by I/O latency etc.
- Not true for DbFortunesRaw (low-latency 10Gbps Ethernet, simple query with data in memory...).
- Even synchronously-yielding method invocations need to be treated very aggressively. The cost of the state machine is noticeable.
Refactoring to Reduce Async Calls
var msg = await ReadExpecting<SomeType>();
async ValueTask<T> ReadExpecting<T>()
{
var msg = await ReadMessage();
if (msg is T expected)
return expected;
throw new NpgsqlException(...);
}var msg = Expect<T>(await ReadMessage());
internal static T Expect<T>(IBackendMessage msg)
=> msg is T asT
? asT
: throw new NpgsqlException(...);
async ValueTask<T> ReadMessage() { ... }Reduced from ~7 layers to 2-3, ~3.5% RPS boost
Allows inlining
Creating Fast Paths
- A more extreme way to eliminate async is to build fast paths for when data is in memory.
Task Open()
{
// Attempt to get a connection from the idle list
if (pool.TryAllocateFast(connString, out var connection))
return connection;
// No dice, do the slow path
return OpenLong();
async Task OpenLong() {
...
}
}
- This is similar to ValueTask: ValueTask eliminates the memory overhead of the async method, but we also want to get rid of the CPU overhead.
- Of course, this causes code duplication...
Small Detour: async & sync paths
- Required by the ADO.NET API, may be considered legacy
- But sync still has advantages over async
- How to maintain two paths?
- Duplicate - no way
- Sync over async - deadlocks
- Async over sync - not true async
Async & sync paths
- Made possible by ValueTask (otherwise sync methods allocate for nothing)
- We still pay useless async state machine CPU overhead in sync path, but it's acceptable.
public Task Flush(bool async)
{
if (async)
return Underlying.WriteAsync(Buffer, 0, WritePosition);
Underlying.Write(Buffer, 0, WritePosition);
return Task.CompletedTask;
}Buffering, Network I/O and Minimizing Roundtrips
Golden Rules of I/O
- Do as little read/write system calls as possible.
- Pack as much data as possible in a memory buffer before writing.
- Read as much data from the socket in each read.
- No needless copying!
- If you do the above, for god's sake, disable Nagling (SO_NODELAY)
Read Buffering in ADO.NET
- The API requires at least row-level buffering - can access fields in random order.
using (var reader = cmd.ExecuteReader())
while (reader.Read())
Console.WriteLine(reader.GetString(1) + ": " + reader.GetInt32(0));- A special flag allows column-level buffering, for huge column access.
Current Implementation
- PostgreSQL wire protocol has length prefixes.
- In Npgsql, each physical connection has 8KB read and write buffers (tweakable).
- Type handlers know how to read/write values.
- Problem: need to constantly check we have enough data/space
- Problem: rowsize > 8KB? Oversize buffer, lifetime management...
These two problems are obviated by the new Pipelines API
Roundtrip per Statement
INSERT INTO...
OK
INSERT INTO...
OK
Batching/Pipelining
INSERT INTO...; INSERT INTO ...
OK; OK
Batching / Pipelining
-
The performance improvement is dramatic.
-
The further away the server is, the more the speedup (think cloud).
-
Supported for all CRUD operations, not just insert.
-
For bulk insert, binary COPY is an even better option.
-
Entity Framework Core takes advantage of this.
var cmd = new NpgsqlCommand("INSERT INTO ...; INSERT INTO ...", conn);
cmd.ExecuteNonQuery();Batching / Pipelining - No Real API
-
The batching "API" is shoving several statements into a single string.
-
This forces Npgsql to parse the text and split on semicolons...
-
(parsing needs to happen for other reasons)
var cmd = new NpgsqlCommand("INSERT INTO ...; INSERT INTO ...", conn);
cmd.ExecuteNonQuery();Less Obvious Batching
var tx = conn.BeginTransaction(); // Sends BEGIN
// do stuff in the transactionBEGIN
OK
INSERT INTO...
OK
Prepend, prepend
-
BeginTransaction() simply writes the BEGIN into the write buffer, but doesn’t send. It will be sent with the next query.
-
Another example: when closing a (pooled) connection, we need to reset its state.
-
This is also prepended, and will be sent when the connection is “reopened” and a query is sent.
The Future - Multiplexing?
- Physical connections are expensive, scarce resources
- Pooling is already hyper-efficient, but under extreme load we're starved for connections
- What if connections were shared between "clients", and we could send queries on any connection, at any time?
- The goal: have more pending queries out on the network, rather than waiting for a connection to be released.
Multiplexing
- When someone executes a query, we look for any physical connection and write.
- The client waits (on a TaskCompletionSource?). When the resultset arrives, we buffer it entirely in memory (need a good buffer pool, probably use Pipelines).
- Breaks the current ownership model: a connection only belongs to you when you're doing actual I/O
- Some exceptions need to be made for exclusive ownership (e.g. transactions)
Command Preparation
What are prepared statements?
- Typical applications execute the same SQL again and again with different parameters.
- Most database support prepared statements
- Preparation is very important in PostgreSQL:
SELECT table0.data+table1.data+table2.data+table3.data+table4.data
FROM table0
JOIN table1 ON table1.id=table0.id
JOIN table2 ON table2.id=table1.id
JOIN table3 ON table3.id=table2.id
JOIN table4 ON table4.id=table3.idUnprepared:
TPS: 953
Prepared:
TPS: 8722
Persisting Prepared Statements
-
Prepared statements + short-lived connections =
using (var conn = new NpgsqlConnection(...))
using (var cmd = new NpgsqlCommand("<some_sql>", conn) {
conn.Open();
cmd.Prepare();
cmd.ExecuteNonQuery();
}
-
In Npgsql, prepared statements are persisted.
-
Each physical connection has a prepared statement cache, keyed on the SQL.
-
The first time the SQL is executed on a physical connection, it is prepared. The next time the prepared statement is reused.
Automatic Preparation
-
Prepared statements + O/RMs =
-
O/RMs (or Dapper) don't call DbCommand.Prepare()
-
Npgsql includes optional automatic preparation: all the benefits, no need to call Prepare().
-
Statement is prepared after being executed 5 times.
-
We eject least-recently used statements to make room for new ones.
Closing Remarks
The ADO.NET API
- The API hasn't received significant attention in a long time.
- Pooling API
- Batching API
- Better support for prepared statements
- Generic parameters to avoid boxing
- However, it's still possible to do remarkably well on ADO.NET (no need to throw it out entirely).
Be careful
- Always keep perf in mind, but resist the temptation to over- (or pre-) optimize.
- Reducing roundtrips and preparing commands is much more important than reducing an allocation or a doing fancy low-level stuff.
- (even if it is slightly less sexy)


It's a Good Time to do Perf
- Perf tools (BDN, profilers) are getting much better, but progress still needs to be made (e.g. Linux)
- Microsoft has really put perf at the center.
- Great open-source relationship with Microsoft data team, around EF Core and Npgsql perf.
- Thanks to Diego Vega, Arthur Vickers, Andrew Peters, Stephen Toub...
- The TechEmpower fortunes benchmark is one of the more realistic ones (e.g. involves DB)
- But still, how many webapps out there send identical simple queries over a 10Gbps link to PostgreSQL, for a small dataset that is cached in memory?
- Performance is usually about tradeoffs: code is more brittle/less safe (e.g. lock-free), duplication (e.g. fast paths).
Is this all useful in the real world?
- No good answer, especially difficult to decide when you're a library...
- Important for .NET Core evangelism: show the world what the stack is capable of, get attention.
- Your spouse & family may hate you, but...
- You learn a ton of stuff and have lots of fun in the process.
So, is this all useful in the real world??
Thank you!
https://slides.com/shayrojansky/dotnetos-2018-11-05/
http://npgsql.org, https://github.com/npgsql/npgsql
Shay Rojansky, roji@roji.org, @shayrojansky

Dotnetos Presentation on Npgsql Performance (full)
By Shay Rojansky




