
Lecture 9: EECS Case Studies & Integration
Shen Shen
April 30, 2025
2:30pm, Room 32-144
Modeling with Machine Learning for Computer Science
- Case study of recent influential EECS works
- Robotics, CV, NLP, algorithmic discovery, circuit design, SWE
- Integration:
- Representation Learning
- Generative Modeling
- Reinforcement Learning
- Transfer Learning
Outline
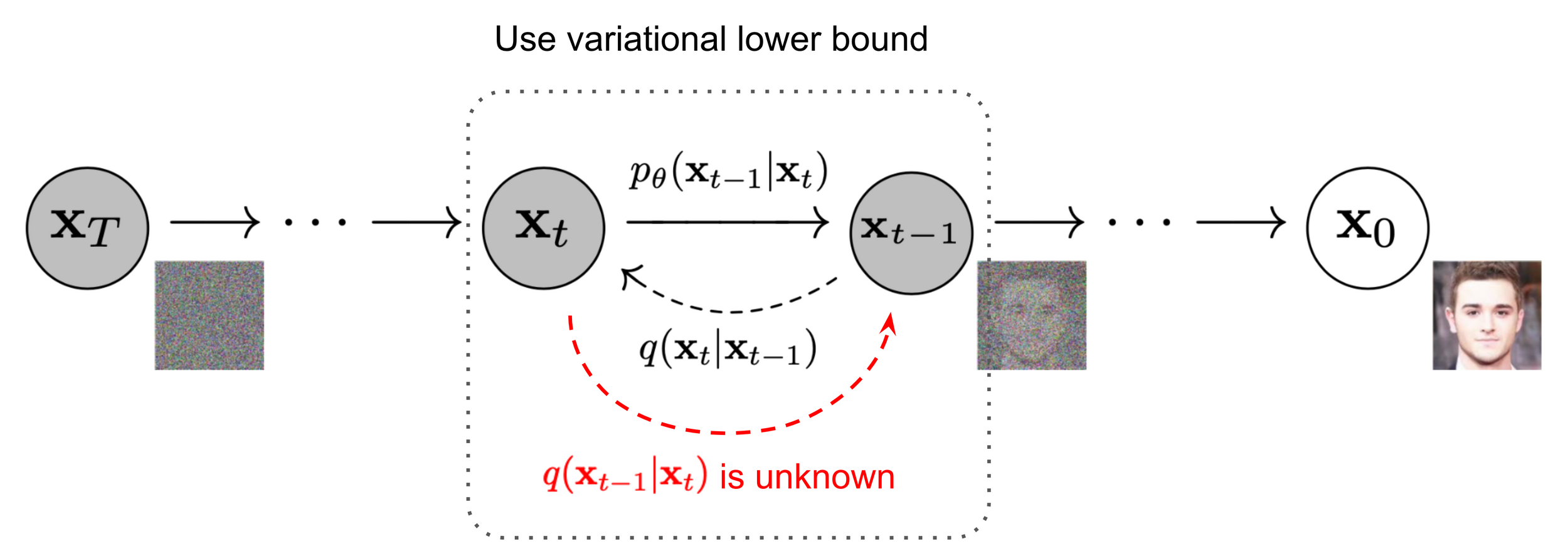
Denoising diffusion models
(for actions)
Image source: Ho et al. 2020
Denoiser can be conditioned on additional inputs, \(u\): \(p_\theta(x_{t-1} | x_t, u) \)
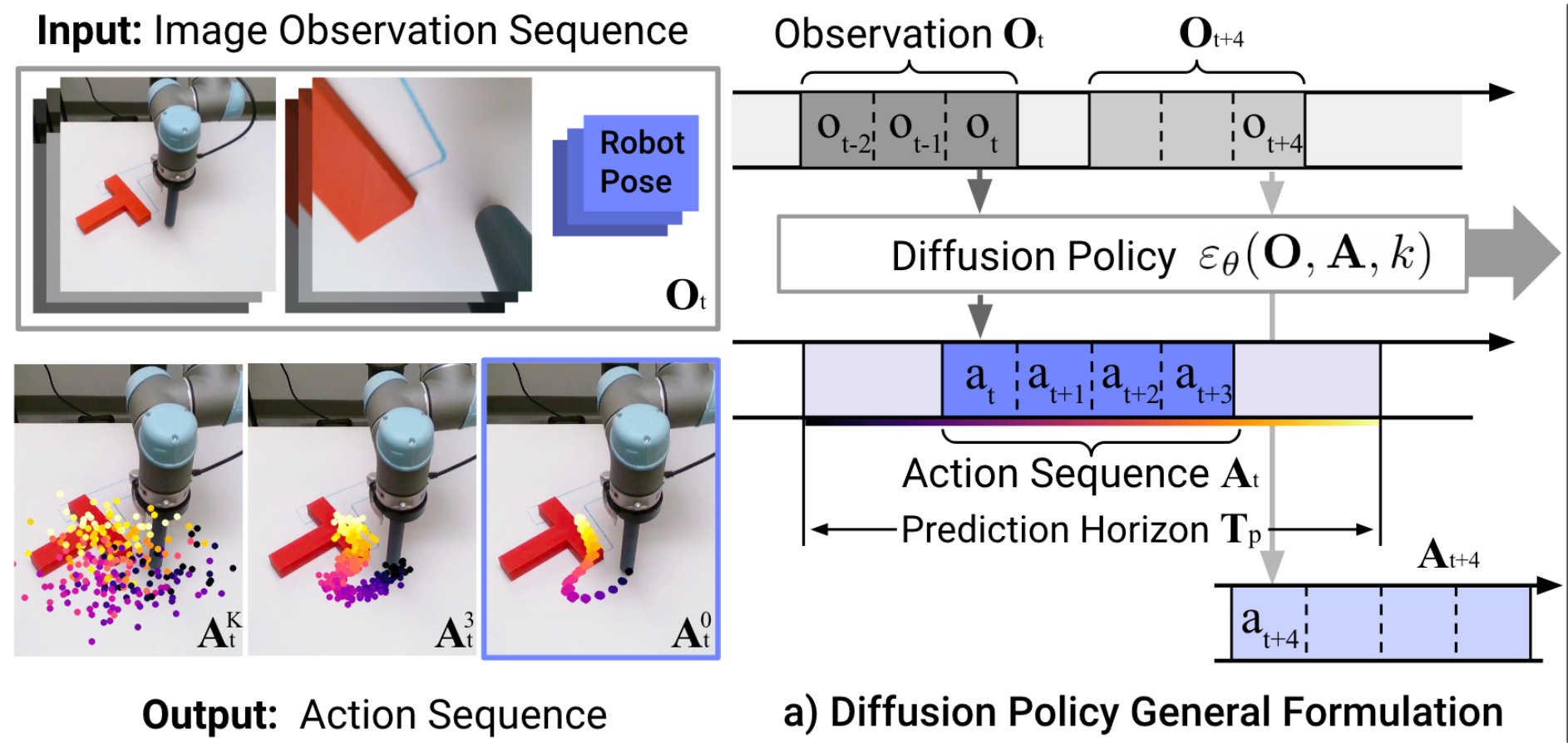
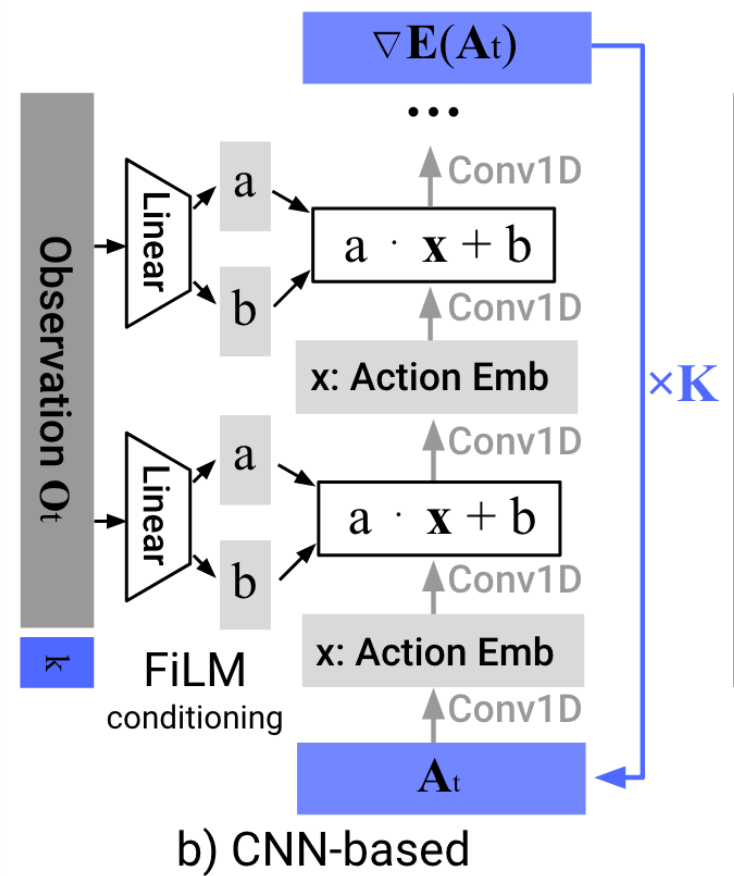
Image backbone: ResNet-18 (pretrained on ImageNet)
Total: 110M-150M Parameters
Training Time: 3-6 GPU Days ($150-$300)
LLMs for robotics
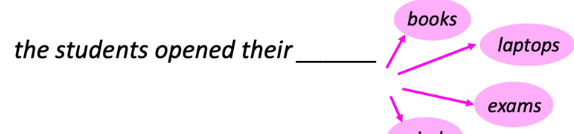
- Given a fixed list of options, can evaluate likelihood with LM
- Given all vocabularies, can sample with likelihood to generate
Ingredient 1
- Bind each executable skill to some text options
- Have a list of text options for LM to choose from
- Given instruction, choose the most likely one

Few-shot prompting of Large Language Models

LLMs can copy the logic and extrapolate it!
Prompt Large Language Models to do structured planning

LLMs for robotics
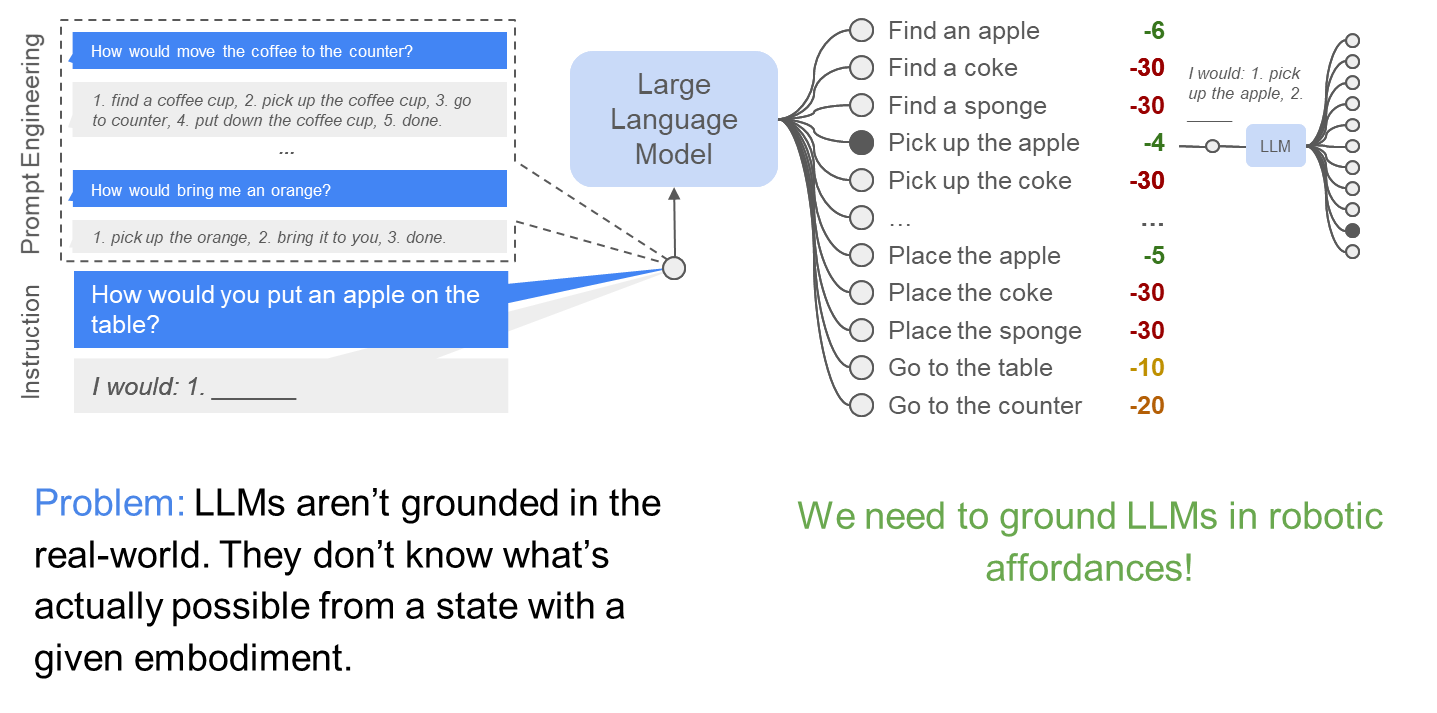
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances, Ahn et al. , 2022

What task-based affordances reminds us of in MDP/RL?
Value functions!
[Value Function Spaces, Shah, Xu, Lu, Xiao, Toshev, Levine, Ichter, ICLR 2022]
Robotic affordances
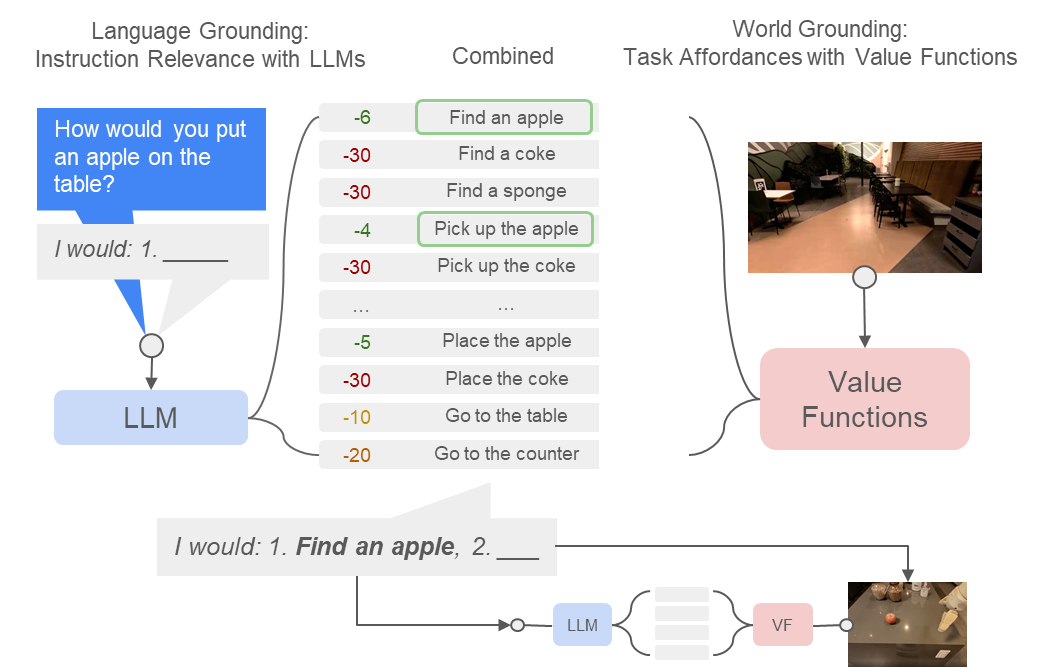
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances, Ahn et al. , 2022


- Language Models as Zero-Shot Planners:
Extracting Actionable Knowledge for Embodied Agents - Inner Monologue: Embodied Reasoning through Planning with Language Models
- PaLM-E: An Embodied Multimodal Language Model
- Chain-of-thought prompting elicits reasoning in large language models
- Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Extended readings in
LLM + Planning
Towards grounding everything in language
Language
Control
Vision
Tactile
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
https://socraticmodels.github.io
Lots of data
Less data
Less data

Roboticist
Vision
NLP
adapted from Tomás Lozano-Pérez
Why video
- Video is how human perceive the world (physics, 3D)
- Video is widely available on internet
- Internet videos contain human actions and tutorials
- Pre-train on entire youtube, first image + text -> video
- Finetune on some robot video
- Inference time, given observation image + text prompt -> video of robot doing the task -> back out actions
A lot of actions/tutorials
Video Prediction for Robots
Learning Universal Policies via Text-Guided Video Generation, Du et al. 2023

Video Prediction for Robots
Learning Universal Policies via Text-Guided Video Generation, Du et al. 2023

Video + Language
Video Language Planning, Du et al. 2023
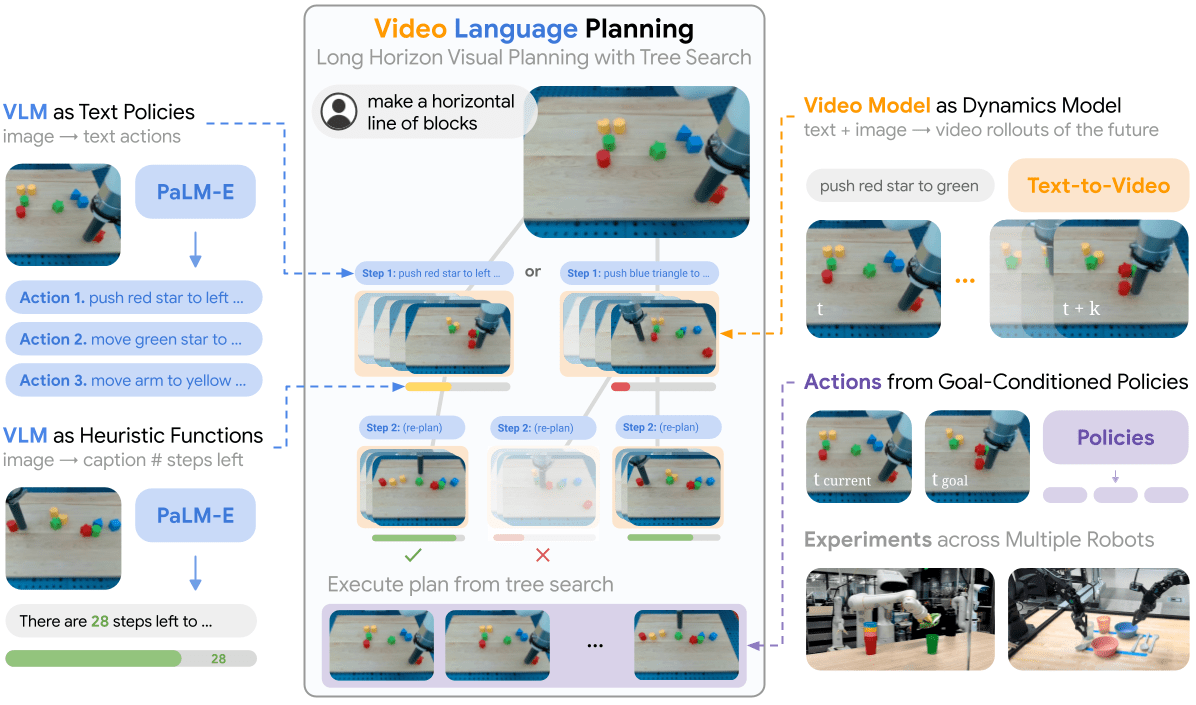
Video + Language
Video Language Planning, Du et al. 2023
Instruction: Make a Line
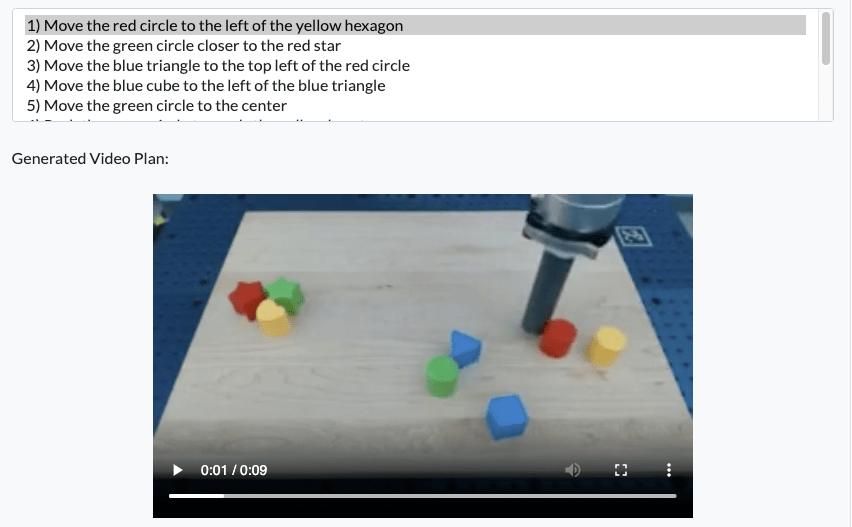
Video + RL
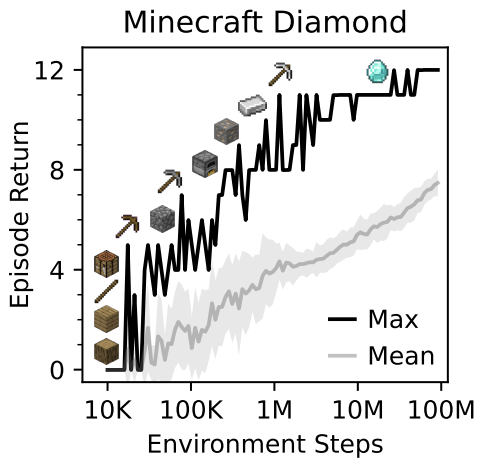
Mastering Diverse Domains through World Models, Hafner et al. 2023
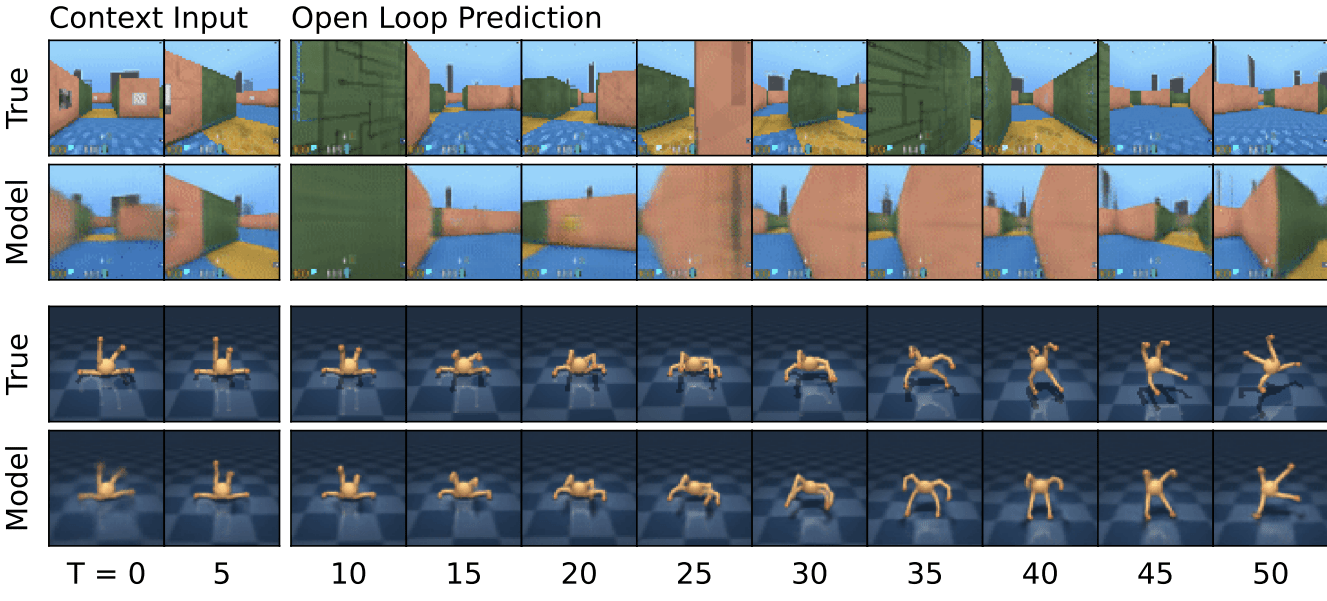

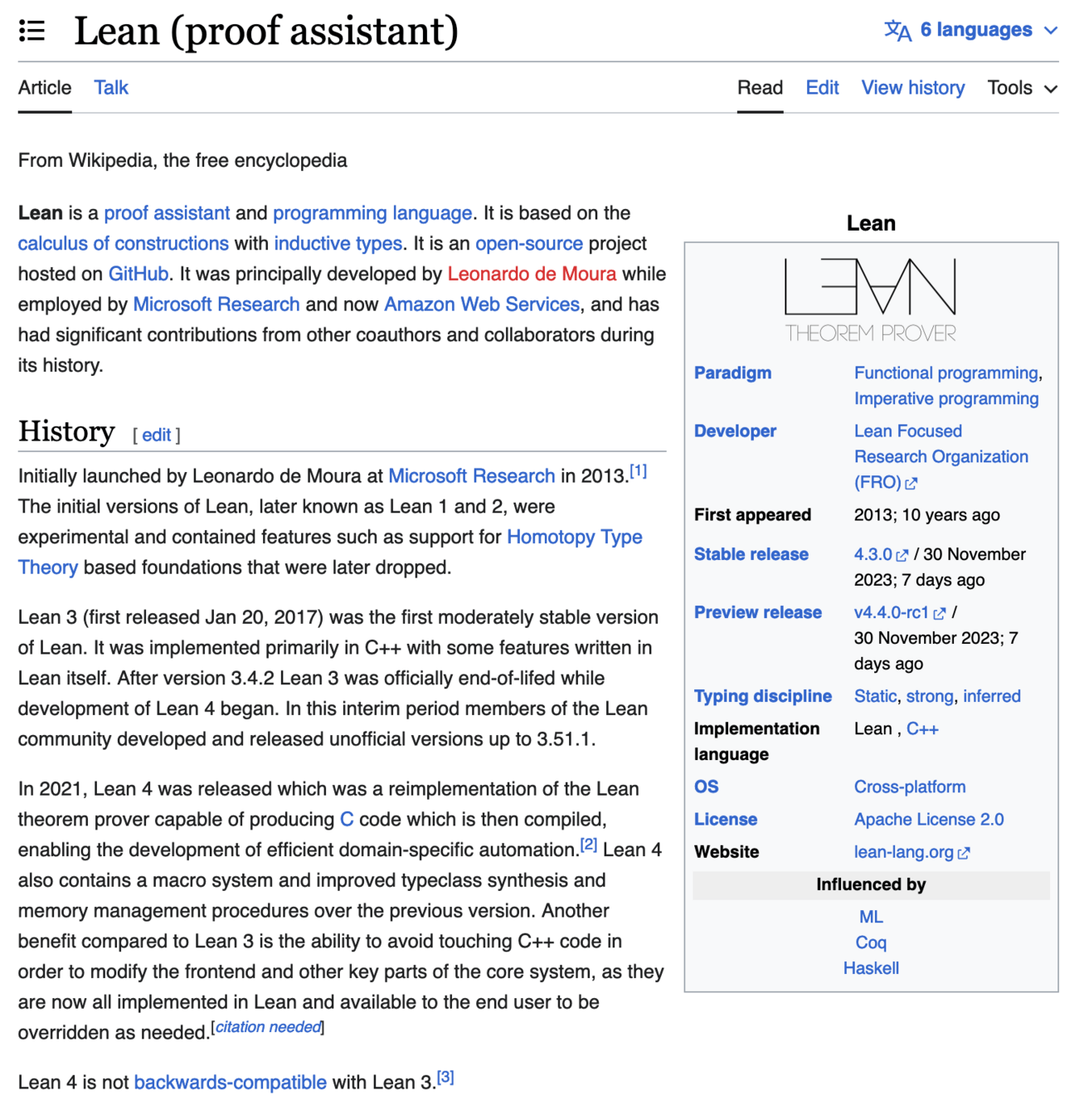
LeanDojo
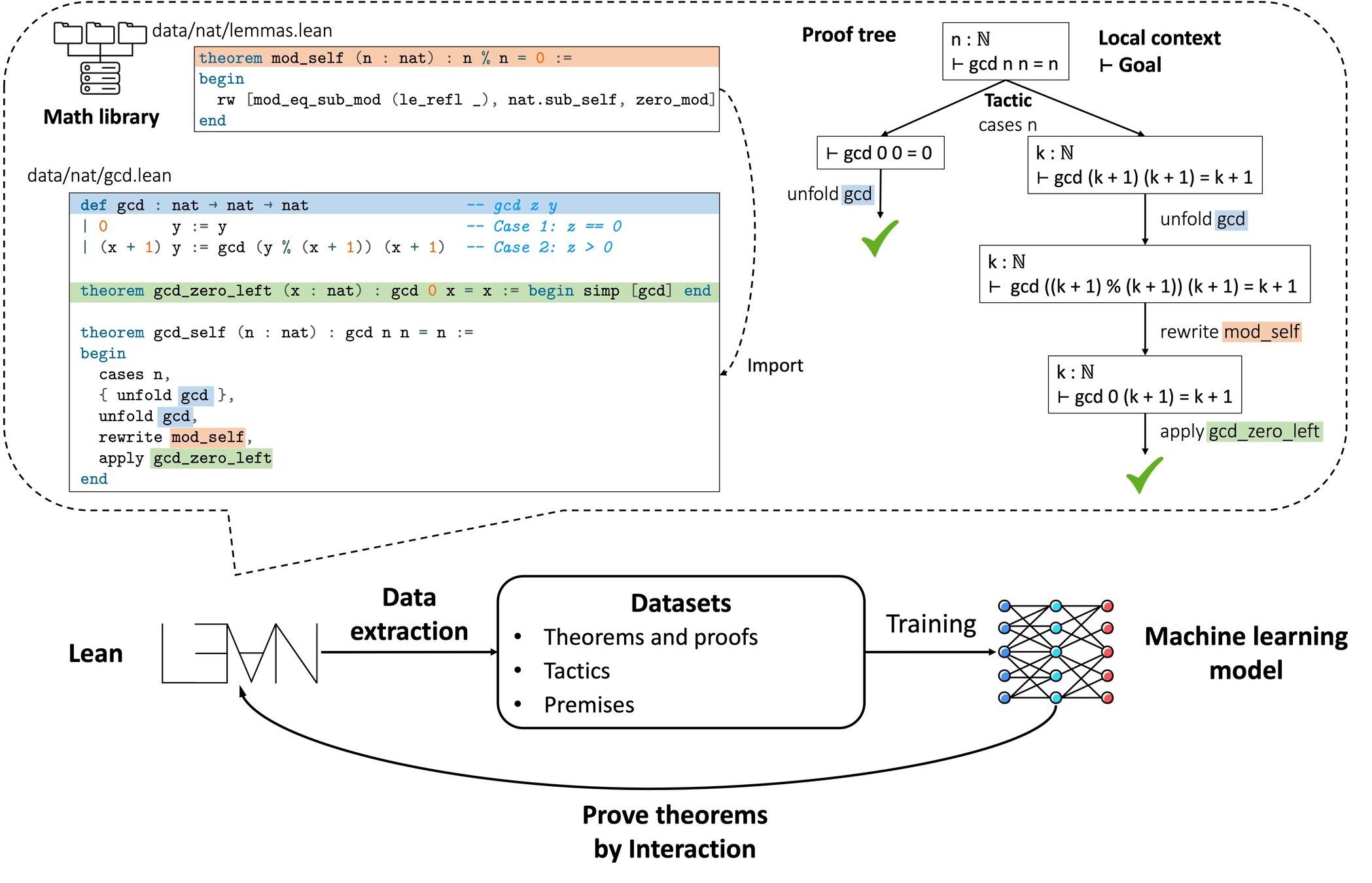
Impact: Formal verification, theorem proving automation, software correctness.

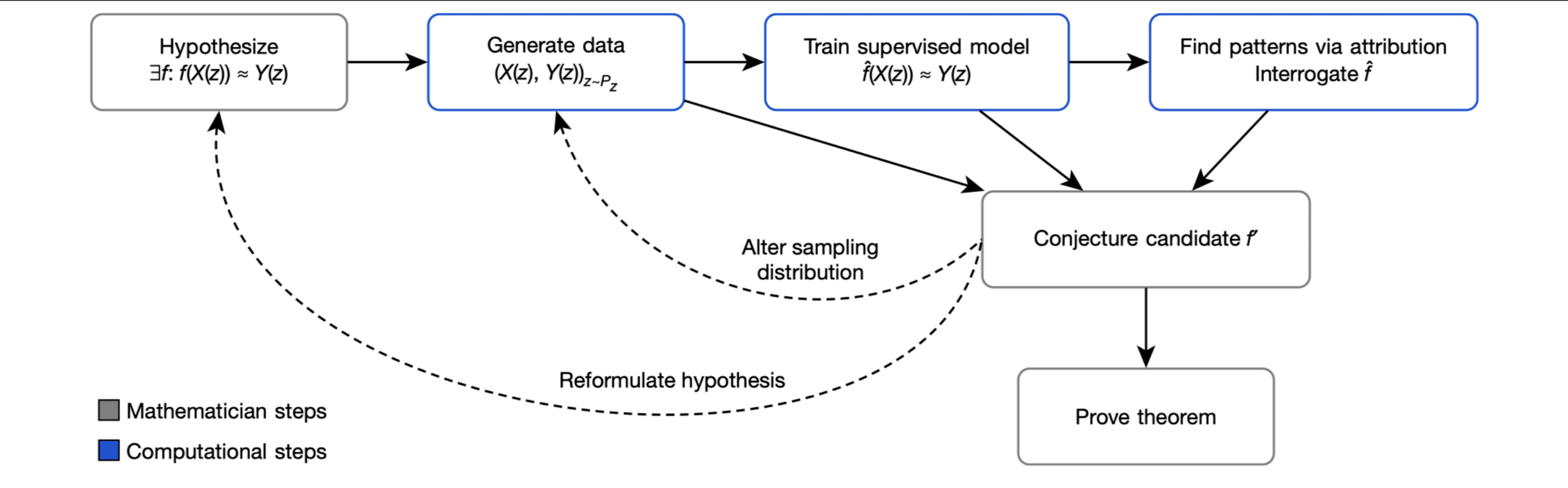

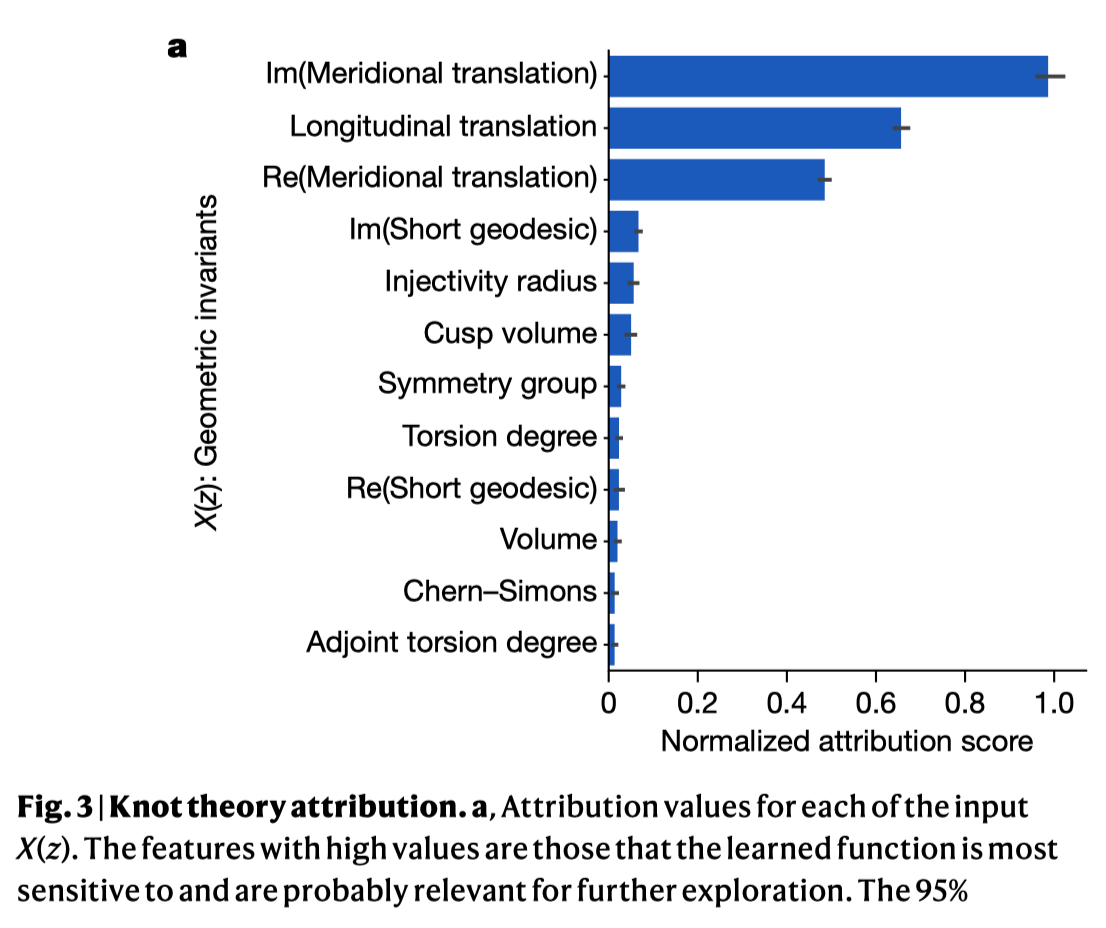

Impact: Pure mathematics, symbolic reasoning, novel conjectures.








Thanks!
We'd love to hear your thoughts.
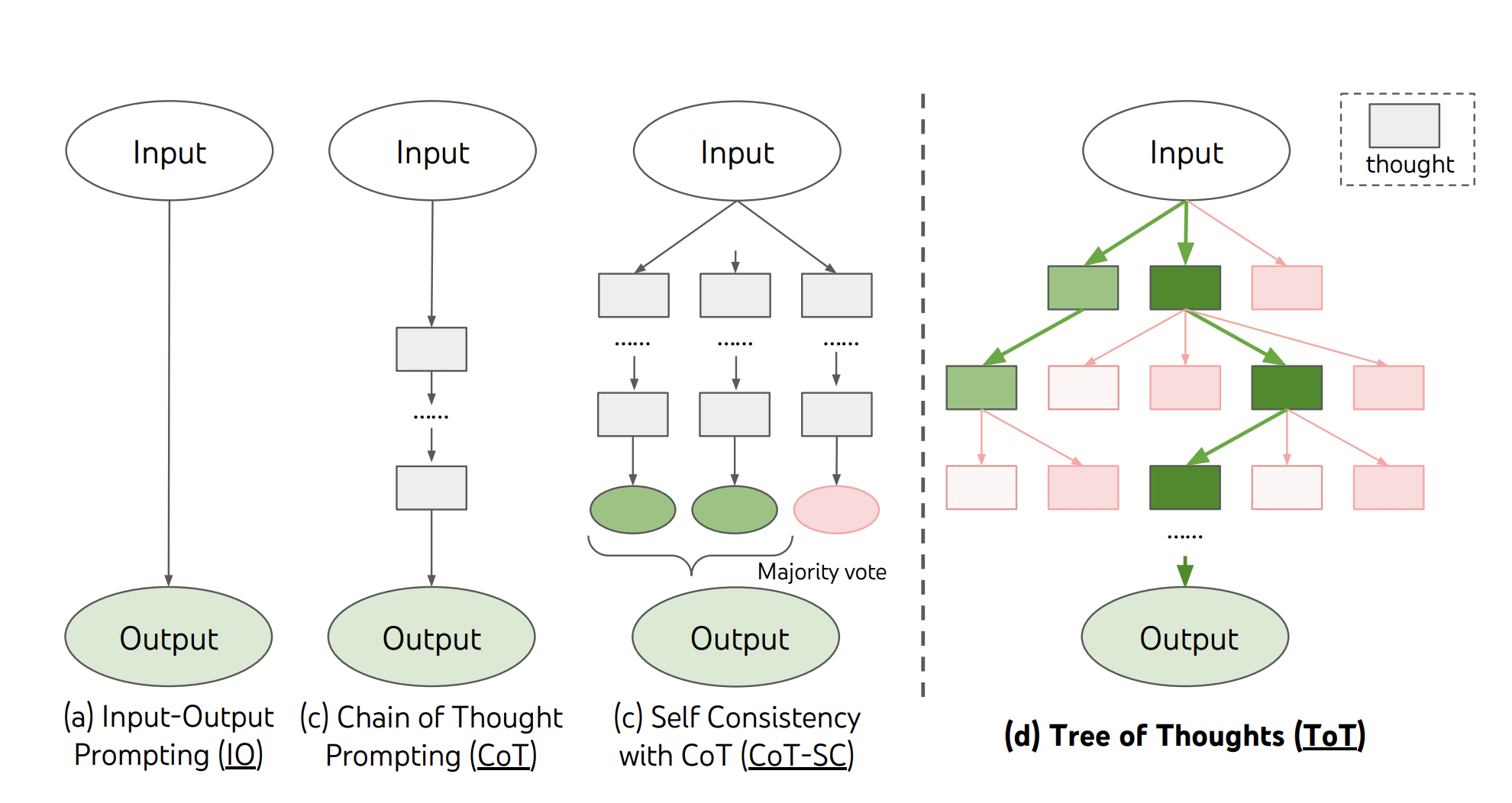
Example: Tree of Thought
Example: Model Based RL?
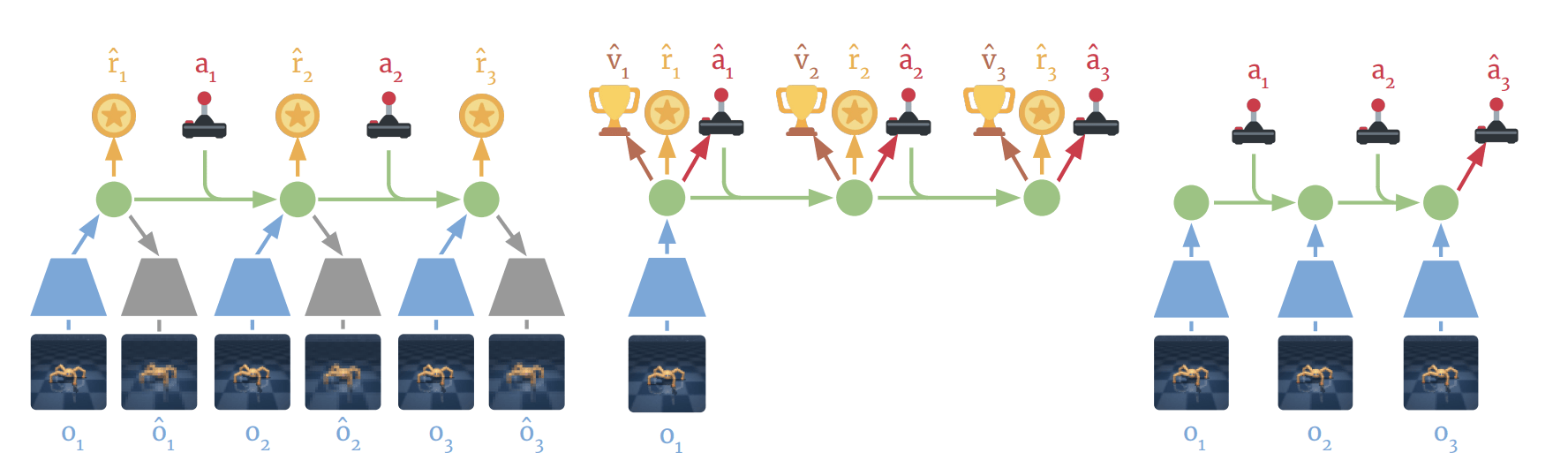
1. MBRL is definitely a policy by test time behavior
2. It does search to generate data

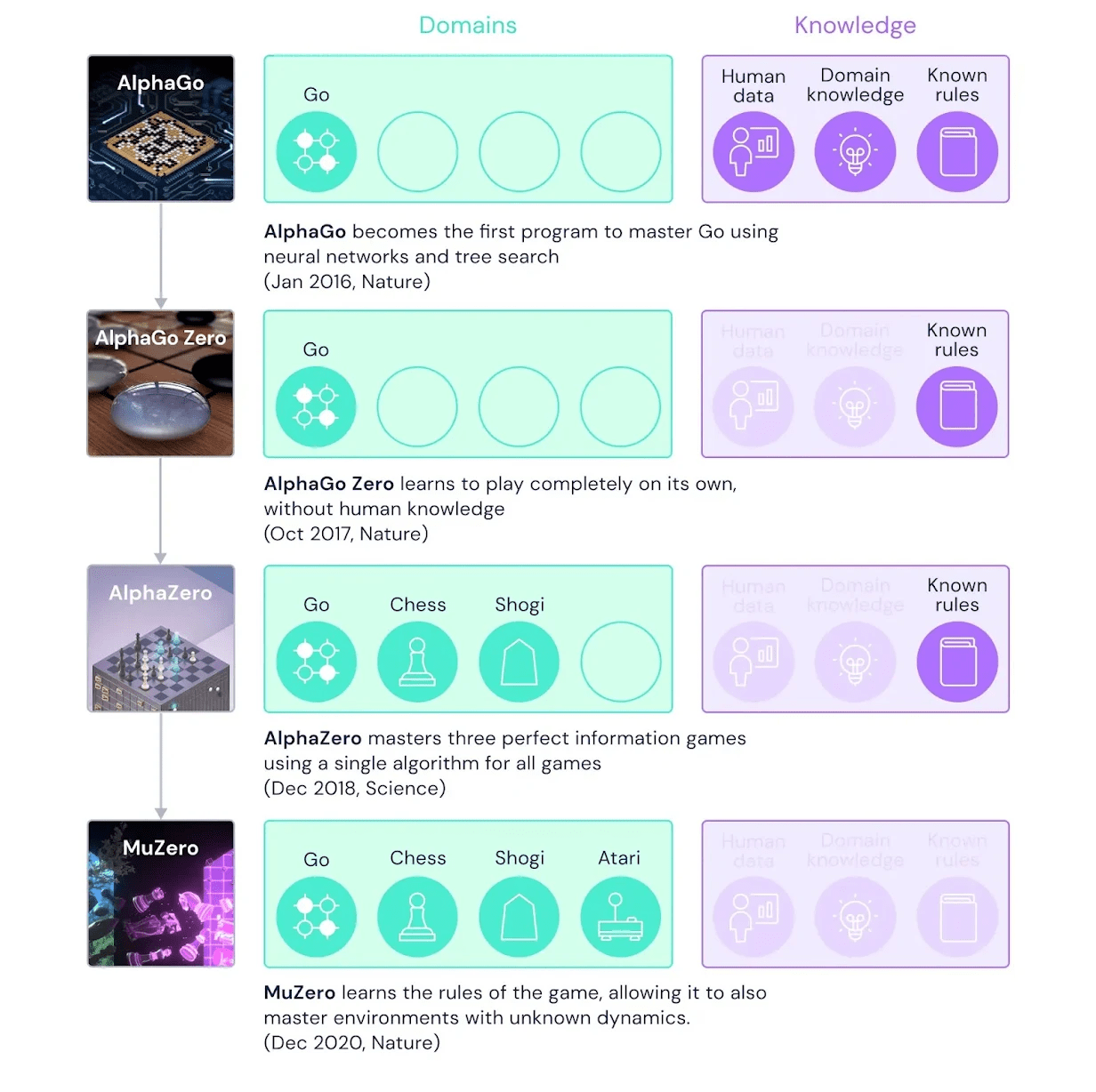
Example: Alpha GO
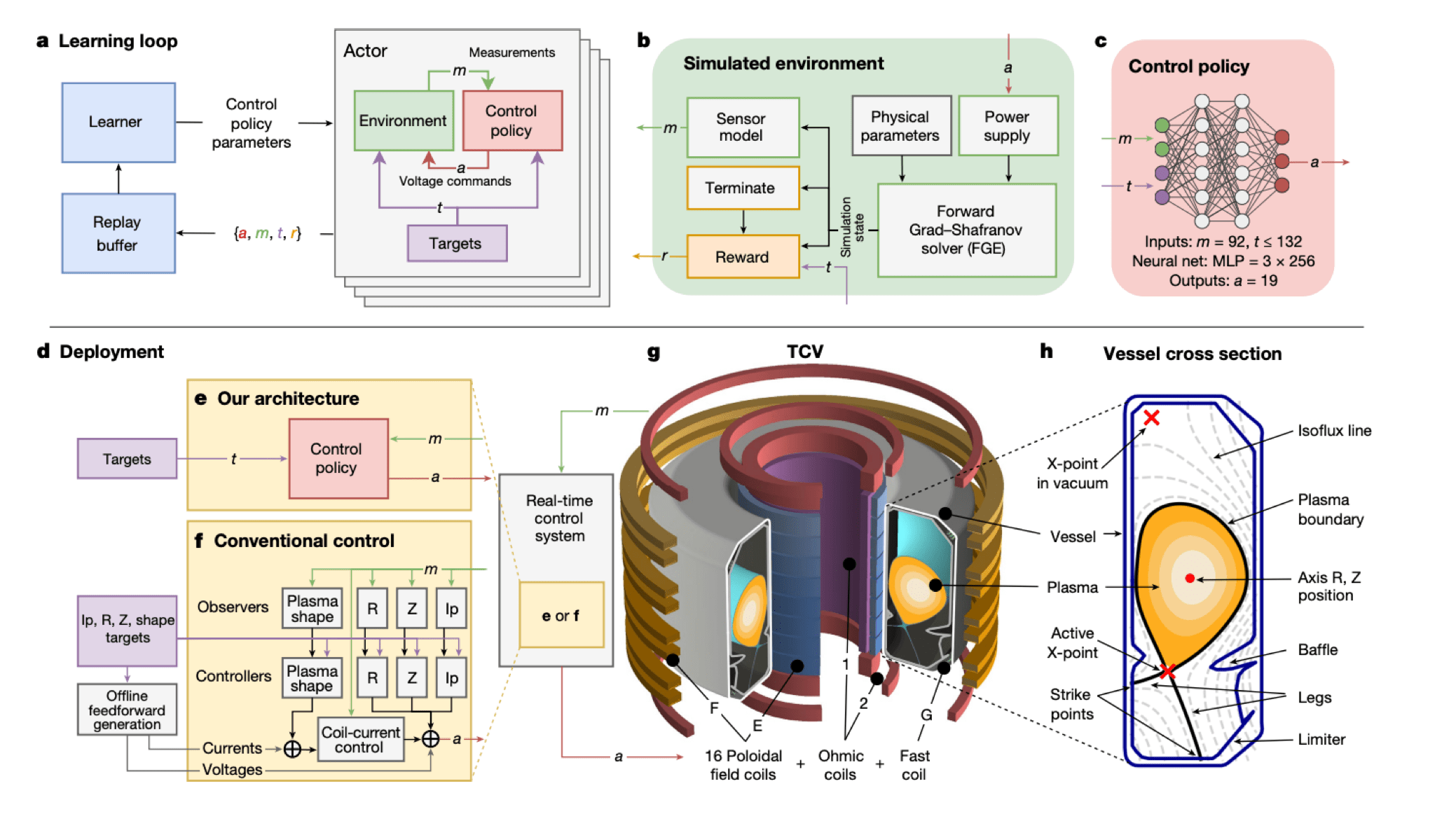
-
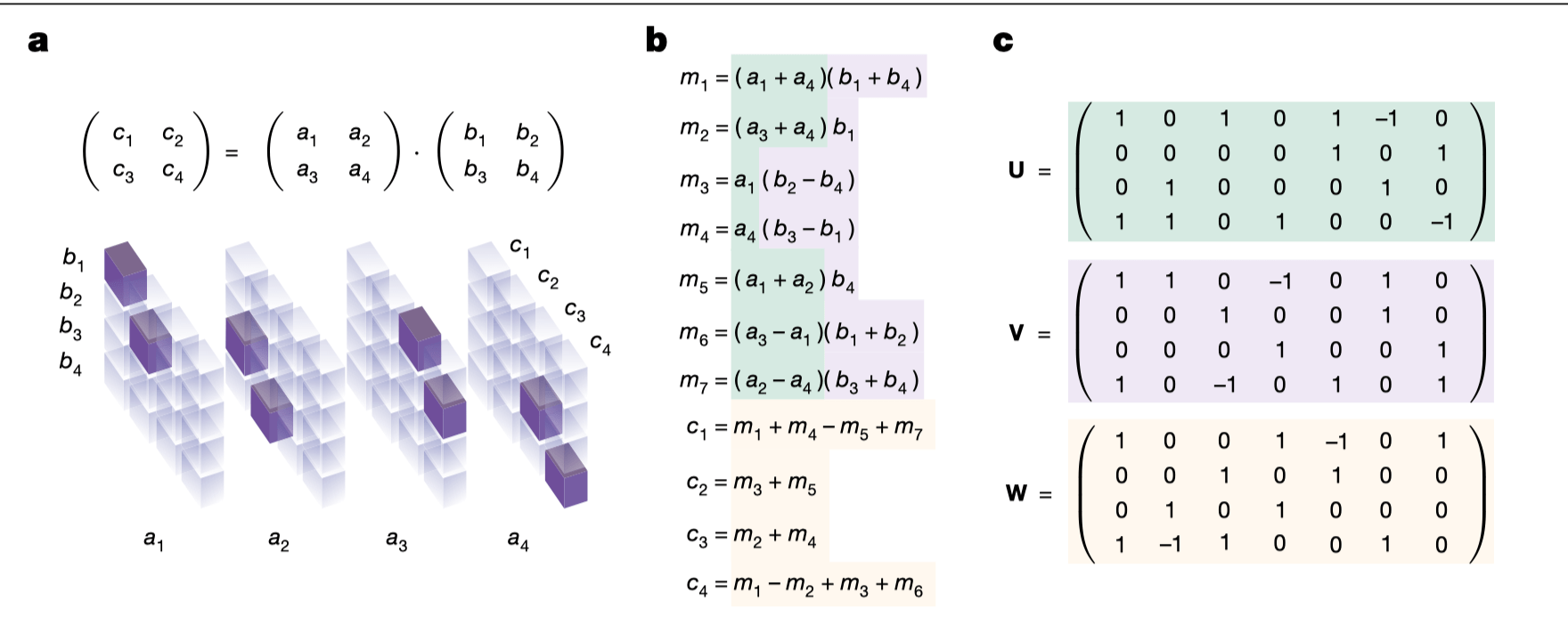
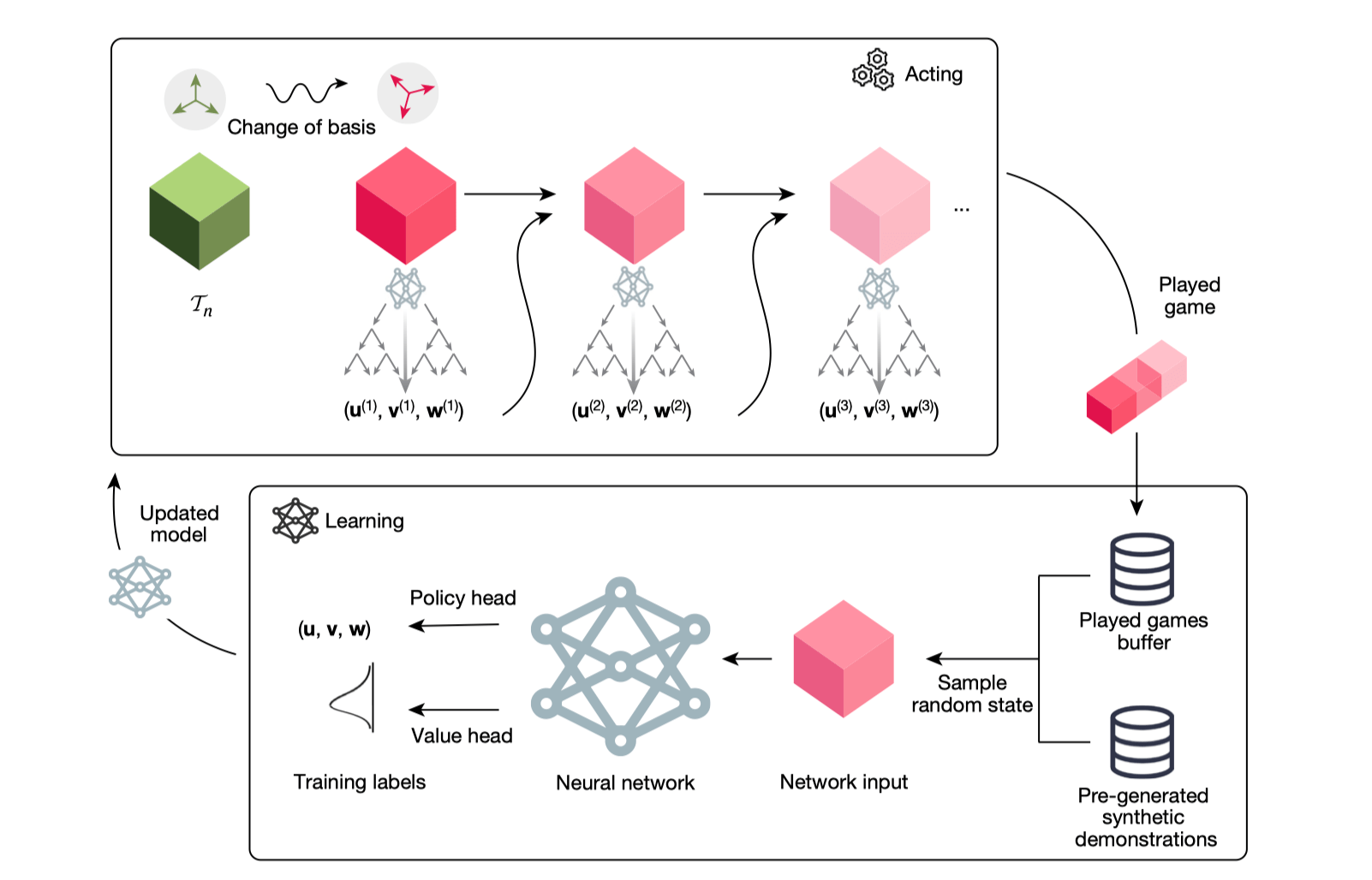
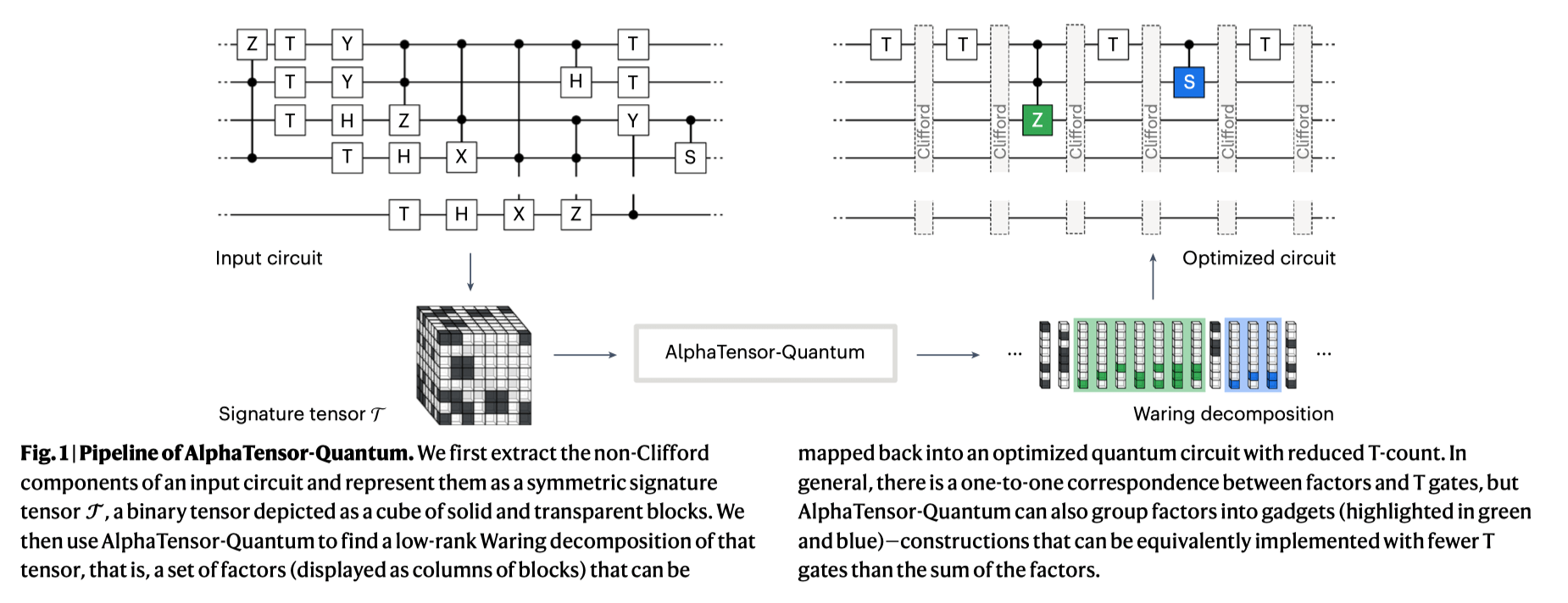
Goal: Minimize T-gate counts in quantum circuits (critical for practical quantum computing).
-
Methods:
- Frames T-count reduction as tensor decomposition.
- Uses deep reinforcement learning to discover optimal quantum circuits.
- Incorporates domain-specific quantum knowledge ("gadgets").
-
Secret Sauce:
- RL-driven automated algorithm discovery tailored to quantum computation.
- Integration of quantum domain knowledge to enhance optimization.
-
Impact:
- Reduces resource-intensive quantum operations.
- Enables scalable, efficient quantum computing algorithms.
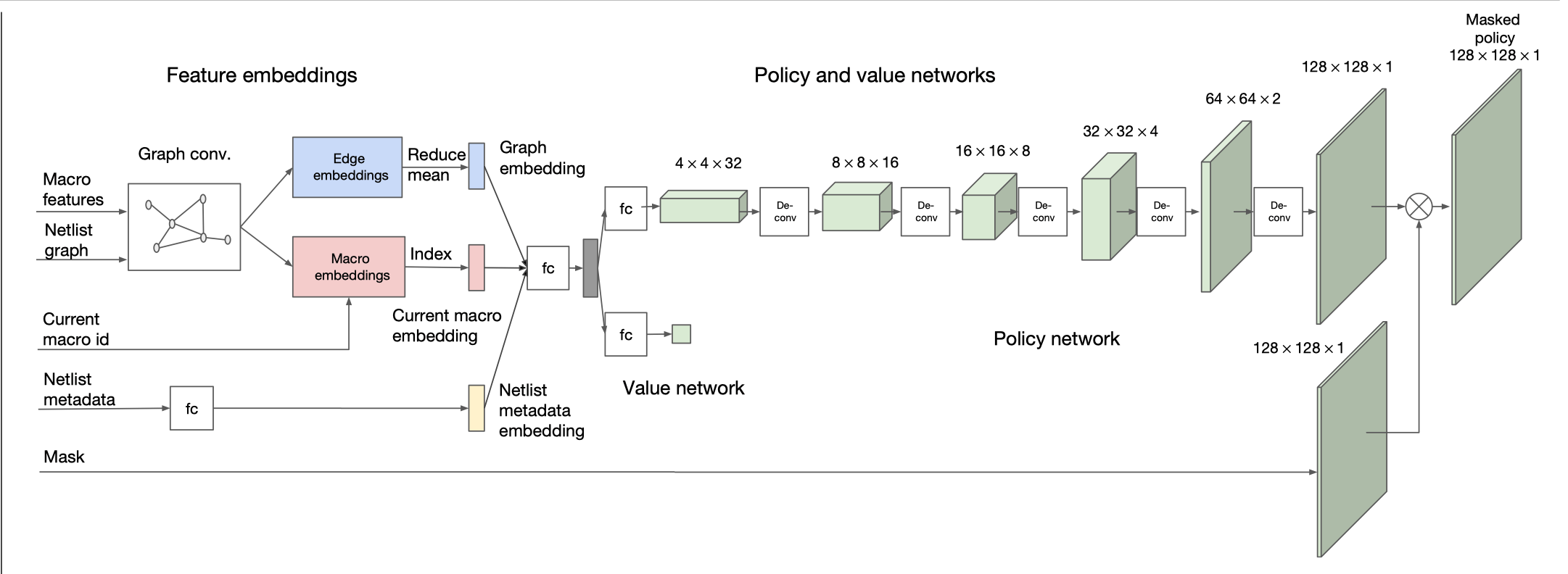
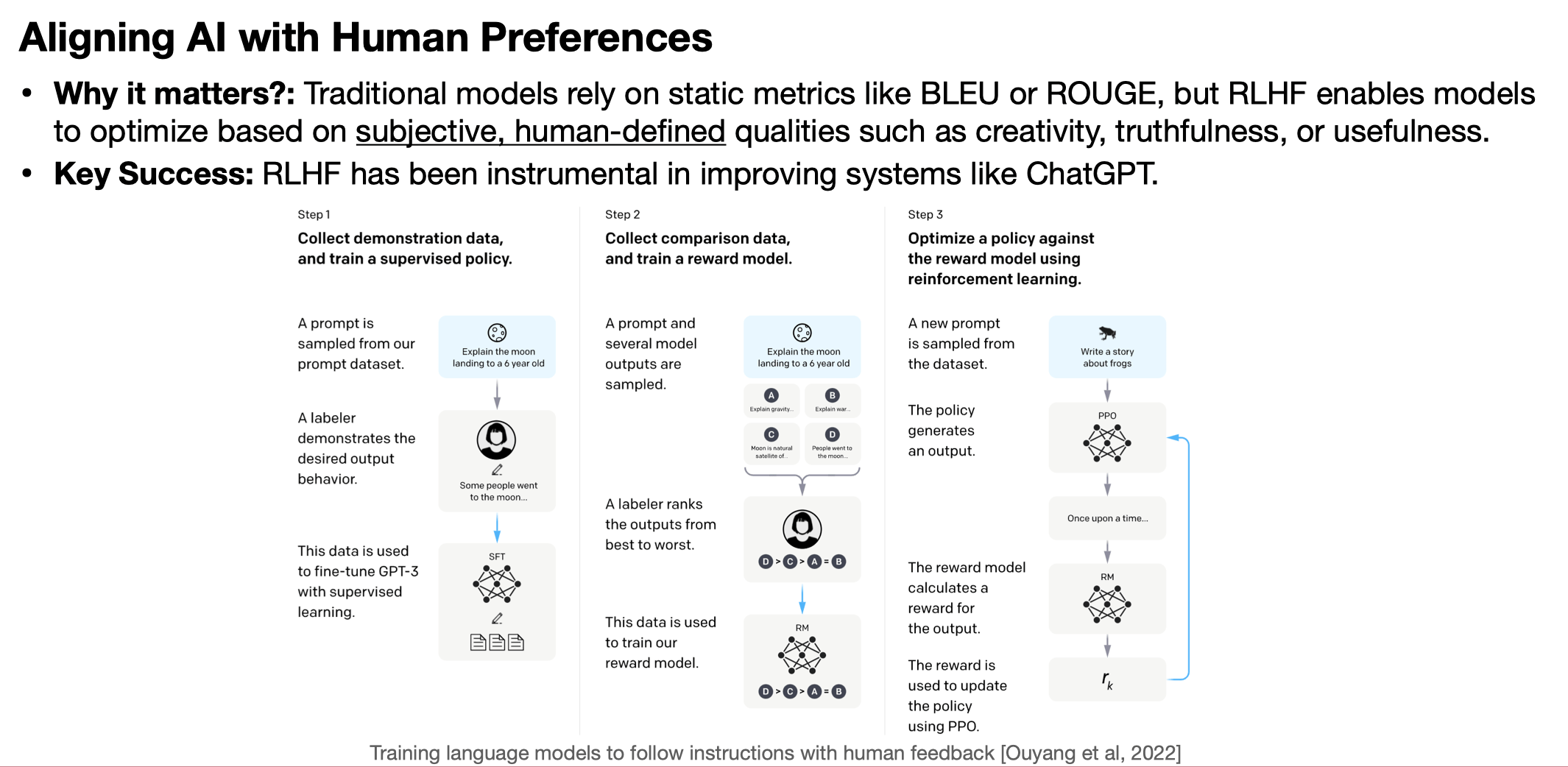
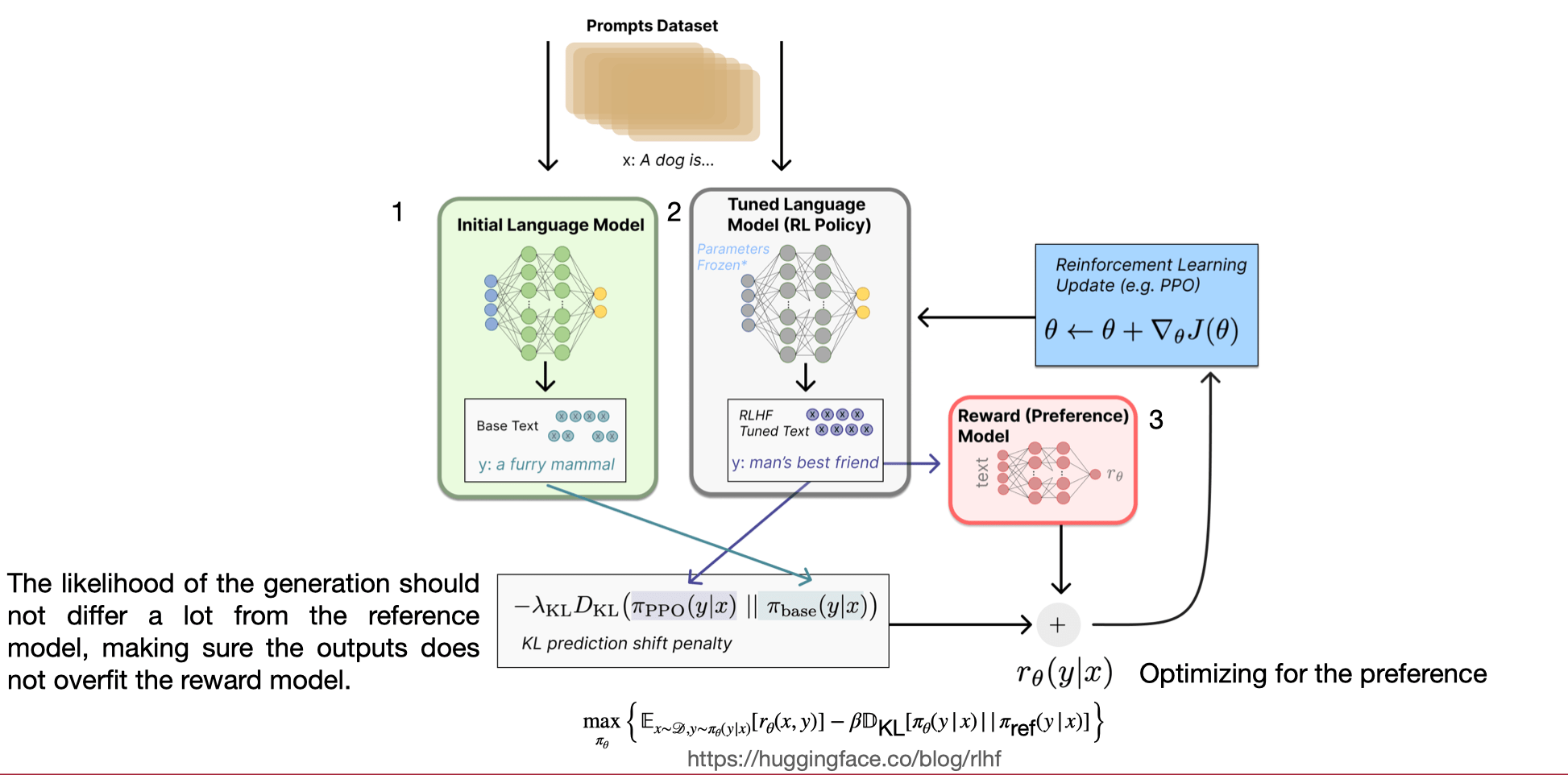
6.C011/C511 - ML for CS (Spring25) - Lecture 9 EECS Case Studies & Integration
By Shen Shen




