
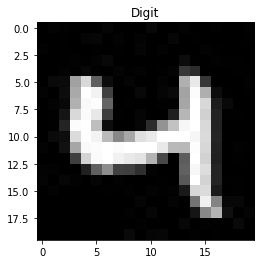


陳信嘉
Shinjia Chen
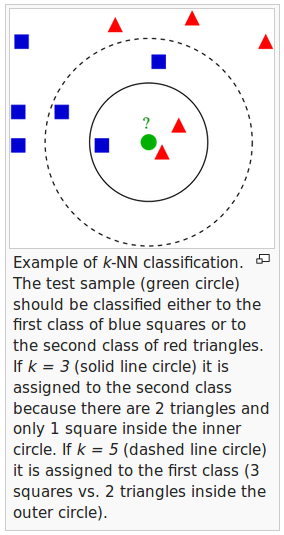
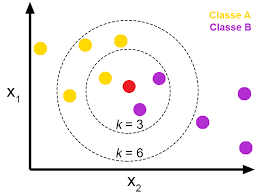
k-Nearest Neighbor (k-NN) classifier is a supervised learning algorithm, and it is a lazy learner. It is called lazy algorithm because it doesn't learn a discriminative function from the training data but memorizes the training dataset instead.
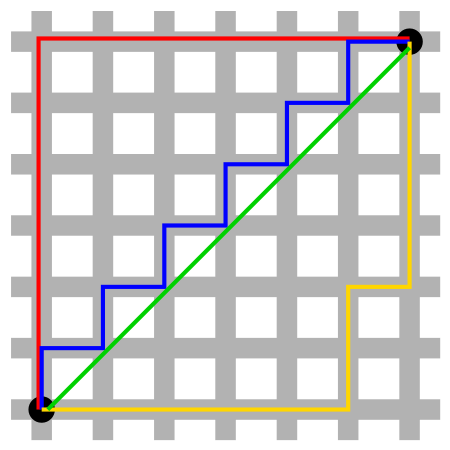
假設欲預測點是 x
找出離 x 最近的 k 筆資料中,
多數是哪一類,即為預測 x 的類型
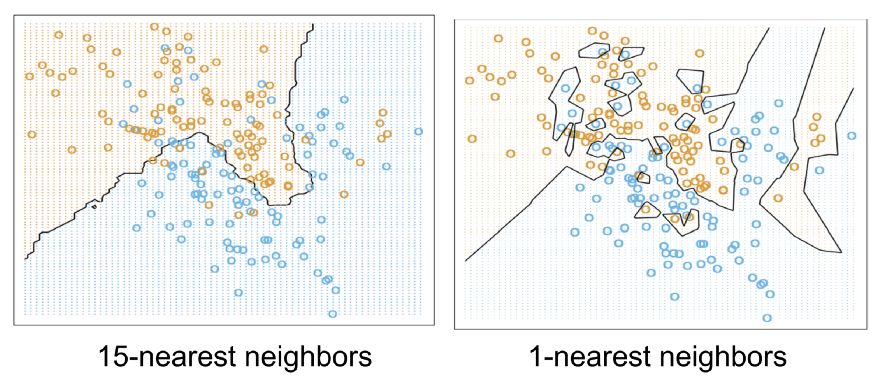
k 值的決定?
KNN屬於機器學習中的監督式學習 (Supervised learning),不過一般來說監督式學習是透過資料訓練 (training) 出一個 model,但是在 KNN 其實並沒有做 training 的動作。KNN 一般用來做資料的分類,如果你已經有一群分好類別的資料,後來加進去點就可以透過KNN的方式指定新增加資料的分類。
曼哈頓距離 (Manhattan Distance)
歐幾里得距離 (Euclidean Distance)
全圖為 1000x2000 像素,共 5000 張數字圖
每個數字有 500 張圖,每張圖尺寸 20x20
前一半做為訓練資料集
後一半做為測試資料集
(50,100,20,20)
(2500,400)
reshape
每個字變成一維陣列
共有 2500 個元素
(50,50,20,20)
分成兩個
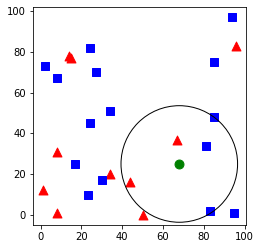
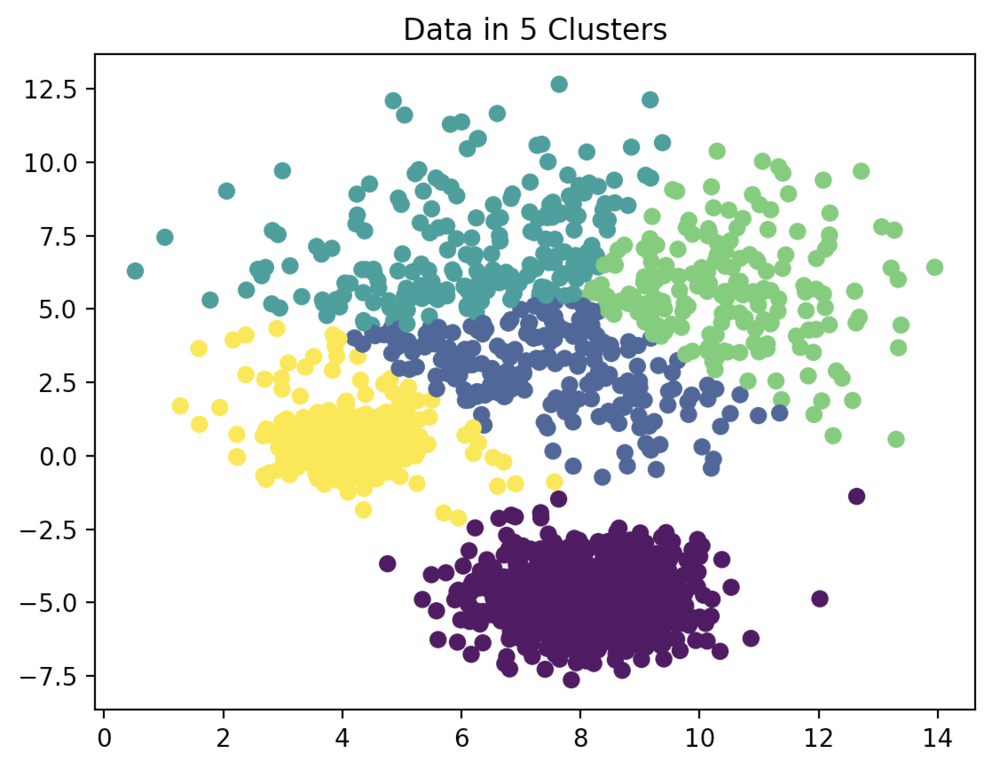
K-Means Clustering is an unsupervised learning algorithm.
分群就是對所有數據進行分組,將相似的數據歸類為一起,每一筆數據的能有一個分組,每一組稱作為群集(Cluster)。
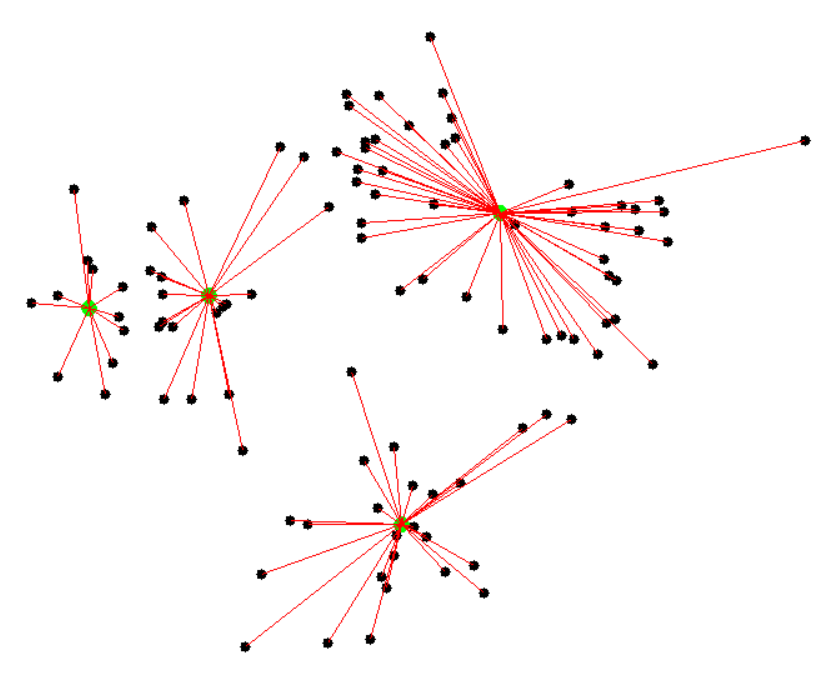
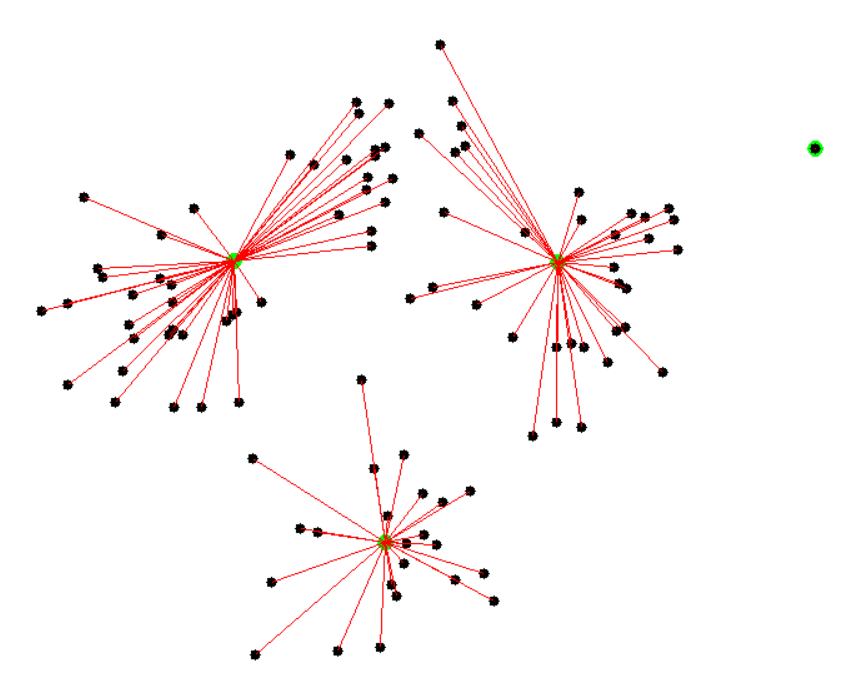
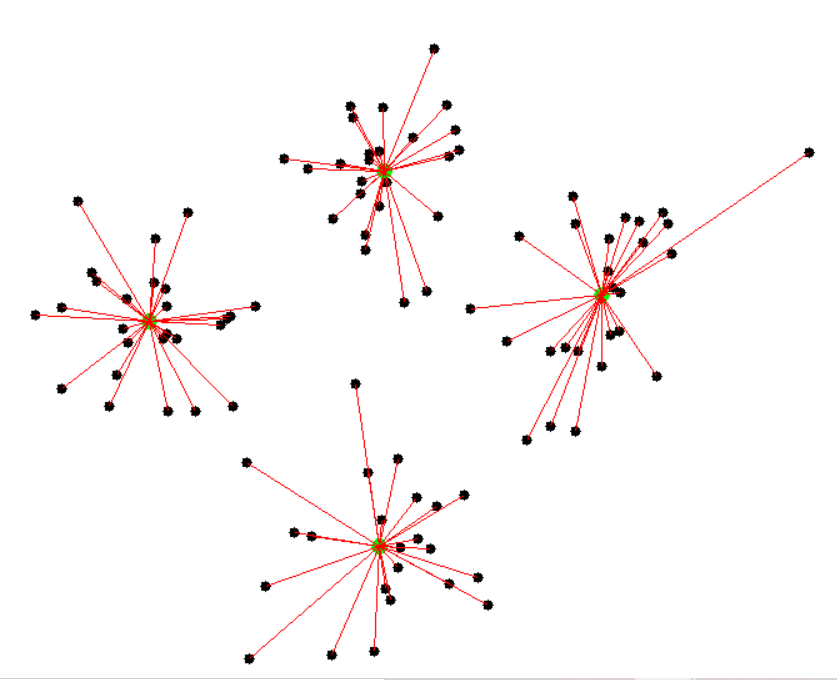
... 將每一個點分類到離自己最近的群集中心(可用直線距離)。 重新計算各組的群集中心(常用平均值)。
反覆上述動作,直到群集不變,群集中心不動為止。
k = 2
K-means 初始點的選擇有很大關係
參考此網站
原始資料分佈圖
4 left-most points
4 right-most points
4 top points
4 bottom points
4 random points
Text
Support Vector Machine
支援向量機
Text
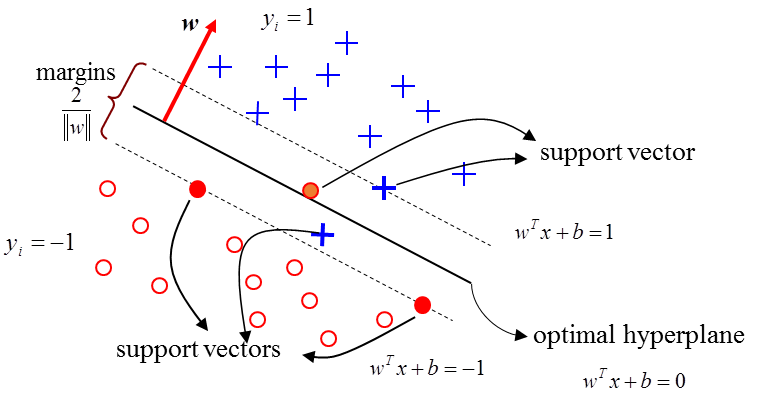
SVM是一種監督式的學習方法,用統計風險最小化的原則來估計一個分類的超平面(hyperplane)
其基礎的概念,就是找到一個決策邊界(decision boundary) 讓兩類之間的邊界(margins)最大化,使其可以完美區隔開來。
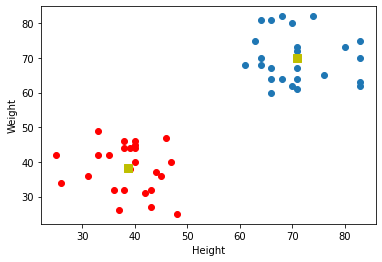
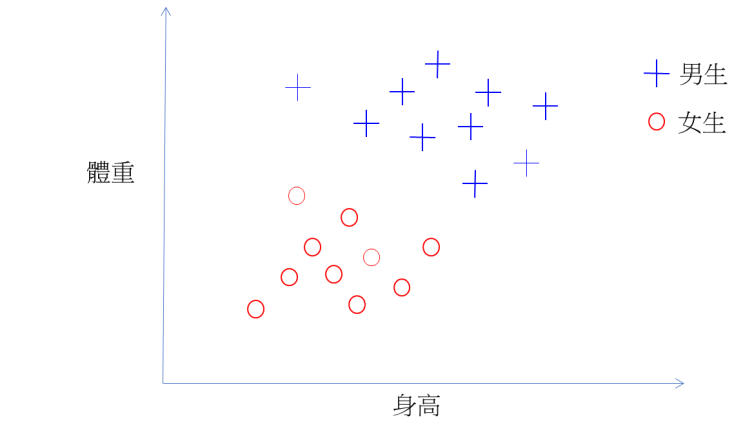
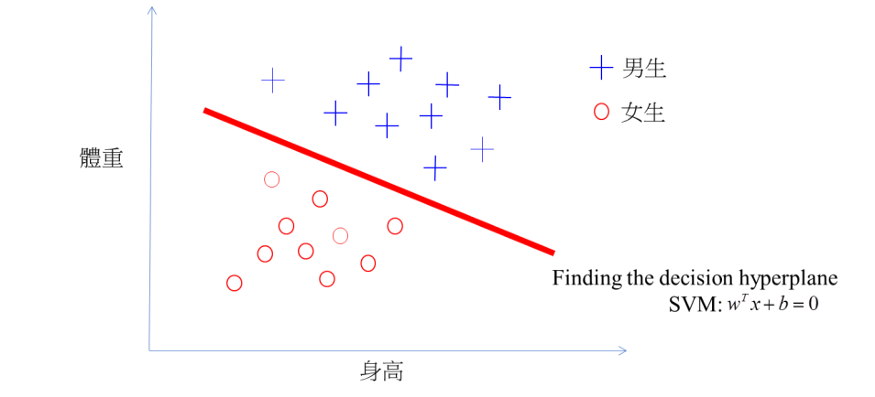
舉例說明要「如何只用身高體重就來判斷是男生還是女生」。
分類男生和女生兩類,特徵資料只有「身高」和「體重」。
目標:找到紅色那條分類的線
(不一定是直線,有可能是曲線)
SVM則是假設有一個 hyperplane(wTx+b=0)可以完美分割兩組資料,所以 SVM 就是在找參數 (w和b),讓兩組之間的距離最大化。
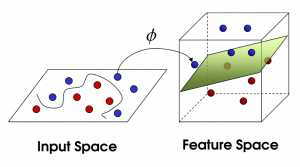
有一天上帝給了你一個考驗,要你用一個棍子將這兩顆不同顏色的球分開
By 陳信嘉



