Tales From Prod:
How I learnt to stop worrying and love the BigInt
Author: Steve Venzerul
A Wild Challenge Appears
My boss

What's the problem?
- Our current receiver is also our regular backend API server.
- Which is slow. Reeeeaaaaallllll slow.
- Wasting resources on fairly small, frequent requests from real-time data provider.
- Monitoring is coupled and mixed in with the rest of the regular server logs.
- The database table used to store the event data is growing quite large (~33 million rows) and even with tablespacing, indexing and optimized queries, it's becoming a serious bottle neck that's slowing down the rest of the API due to waiting on the DB.
- Trying to run analytics or BI type queries on this table in the DB replica is so slow it's causing severe replication lag everytime we try.
Something had to be done
I have an idea!
This receiver thing sure sounds like a low latency, high throughput micro-service.
Sounds like a job for NodeJS/Express with a little JSON parsing, Knex to talk to Postgres and Redis pitched in to queue events and keep some metrics.
Right...

A Journey of Failure

Let's look at the data
[
{
"meta": { "account": "municio", "event": "track" },
"payload": {
"id_str": "1091482500479000001",
"id": 1091482500479000001,
"connection_id": 2,
"connection_id_str": "2",
"asset": "354676050291234",
"loc": [75.2351, -170.15524],
"index": 0,
"received_at": "2018-10-17T21:51:24Z",
"recorded_at": "2018-10-17T21:51:24Z",
"recorded_at_ms": "2018-10-17T21:51:25.274783Z",
"fields": {
"MDI_EXT_BATT_VOLTAGE": { "b64_value": "AAAyyQ==" },
"MDI_DTC_MIL": { "b64_value": "AQ==" }
}
}
},
{
"meta": { "account": "municio", "event": "track" },
"payload": {
"id_str": "1091482500479000000",
"id": 1091482500479000000,
"connection_id": 1,
"connection_id_str": "1",
"asset": "354676050291234",
"loc": [67.05185, -169.21836],
"index": 0,
"received_at": "2018-10-17T21:51:24Z",
"recorded_at": "2018-10-17T21:51:24Z",
"recorded_at_ms": "2018-10-17T21:51:24.274783Z",
"fields": {
"MDI_EXT_BATT_VOLTAGE": { "b64_value": "AAAw1A==" },
"MDI_DTC_MIL": { "b64_value": "AA==" }
}
}
}
]
The Vendor Docs
The docs say that all incoming events can be de-duplicated and ordered by the "id" property of the event. Great!
"id_str": "1091482500479000001",
"id": 1091482500479000001Hmm, I wonder why they included the event id as a string. Oh well, doesn't seem useful right now since we have the id as an integer and it's much faster to do calculations with numbers.
const results = JSON.parse(req.body.toString('utf8'));
console.log(results);
[ { meta: { account: 'municio', event: 'track' },
payload:
{ id_str: '1091482500479000001',
id: 1091482500479000000,
connection_id: 2,
connection_id_str: '2',
asset: '354676050296432',
loc: [Array],
index: 0,
received_at: '2018-10-17T21:51:24Z',
recorded_at: '2018-10-17T21:51:24Z',
recorded_at_ms: '2018-10-17T21:51:25.274783Z',
fields: [Object] } } ]
undefined
>Let's try to parse the input data
Wait... Wat?!!
One of these things is not like the other
// Input
"id_str": "1091482500479000001",
"id": 1091482500479000001,
// Output
id_str: '1091482500479000001',
id: 1091482500479000000, // <-- WAT???How? What? Why? Node Bug? V8 Bug? Not even close. Just good ol' JavaScript.
JavaScript Numbers and IEEE 754

JS only has one number type: Number
Under the hood, this is a 64bit double-precision binary format IEEE 754 value capable of representing numbers between -(2^53-1) and (2^53-1).
Which does seem like quite a few numbers.
BUT...
Oh integers
// Max integer values
> Number.MAX_SAFE_INTEGER
9007199254740991
> Number.MIN_SAFE_INTEGER
-9007199254740991
// Comparing with our id from before
> 9007199254740991 < 1091482500479000001
true

To check for the largest available value or smallest available value within +/-Infinity, you can use the constants Number.MAX_VALUE or Number.MIN_VALUE and starting with ECMAScript 2015, you are also able to check if a number is in the double-precision floating-point number range using Number.isSafeInteger() as well as Number.MAX_SAFE_INTEGER and Number.MIN_SAFE_INTEGER. Beyond this range, integers in JavaScript are not safe anymore and will be a double-precision floating point approximation of the value.
approximation of the value.
How deep does the rabbit hole go?
We've all seen this:
> 0.1 + 0.2 === 0.3
false
// WAT??!?!?1!!111But what about this:
> JSON.parse('9999999999999999999')
10000000000000000000And more subtly:
> JSON.parse('1091482500479000001')
1091482500479000000 // Do you see it?Remember this?
"id_str": "1091482500479000001",
"id": 1091482500479000001That id_str is really making sense now!
So now what?
I Heard You Like Strings

Do I have to use strings for all large integers in JS??
Maybe... Sort of...
Looking around the landscape
Node-Redis docs

Knex docs


Node MySQL docs

Twitter API docs
Twitter has a whole page just about dealing with large ids: https://developer.twitter.com/en/docs/basics/twitter-ids
I'm sure you can see where this is going

"STRINGS"
Problems?


- Converting to and from strings is slow.
- In this case we can't even convert!
- Sorting integers stored as strings is beyond painful (seriously, just look at this: https://stackoverflow.com/questions/8107226/how-to-sort-strings-in-javascript-numerically)
- Calculations are impossible without some kind of lib, and they're always orders of magnitude slower than native operations.
- JSON.stringify will work, but what about JSON.parse?
- What if the some crappy API didn't even consider adding something like id_str to their payloads?
Strung Along
Are we doomed to use strings?


Maybe Not...

BigInt
Introducing BigInt
The BigInt type is a new numeric primitive in JavaScript that can represent integers with arbitrary precision. With BigInts, you can safely store and operate on large integers even beyond the safe integer limit for Numbers. A BigInt is created by appending n to the end of the integer or by calling the constructor.
Currently available in Node v10 and up using the --harmony-bigint flag!!
Look at this magnificent beast
// Things like our id from before.
> const num = BigInt('9999999999999991234');
> num
9999999999999991234n
// YES!
// Native notation
> let x = 2n ** 53n;
> x
9007199254740992n
// Double YES!!
> let y = 100;
> y * 10000000n
Thrown:
TypeError: Cannot mix BigInt and other types, use explicit conversions
// Oh oh...
> y = 100n;
> y * 100n
10000n
// Got it.
// Works as well: BigInt('100') * BigInt('100') === 10000n;
Tears of Joy?

Not so fast...
More Problems
- BigInt is still in the proposal stage and although quite stable, stage 3 proposals have been dropped before. (link: TC39 - BigInt)
- Cannot interchange with regular Numbers (yet). Not critical, but still a pain in the ass.
- Currently only implemented by V8 and by extension Chrome, but other browser vendors are coming.
BUT...
Time for more pain
> JSON.stringify(1091482500479000001n)
//Thrown:
//TypeError: Do not know how to serialize a BigInt
// at JSON.stringify (<anonymous>)
> JSON.parse('1091482500479000000n')
//Thrown:
//SyntaxError: Unexpected token n in JSON at position 19
> JSON.parse('{"id": 1091482500479000000n}')
//Thrown:
//SyntaxError: Unexpected token n in JSON at position 26

Ideas
// Eval
// Bad, also can't be done if you don't control the input data.
> c = JSON.parse('{ "id": "BigInt(\'1091482500479000000\')" }')
{ id: 'BigInt(\'1091482500479000000\')' }
> eval(c.id)
1091482500479000000n
// Bad-ish
// JSON reviver function.
// Will work, somewhat, but falls on it's face if you don't know in advance which
// keys are going to be large ints.
> let payload = '{ "id_str": "1091482500479000000" }';
> c = JSON.parse(payload, (key, val) => key === 'id_str' ? BigInt(val) : val)
{ id_str: 1091482500479000000n }
// Insane
// Modify V8s source to support parse/stringify, compile Node v10 with your
// modified version and run that in production.
// This is totally doable, and yet, thinking about it made me ask
// myself if I was smoking crack for lunch.Time to hit the Googles
YES!!

NO!!
What's wrong with the JSON-BigInt lib?
Nothing!
It'll work just fine for most use cases and no one will notice the difference.
However. I wanted break-neck performance, and without using native BigInt, there's no way to get there. (technically you can still have more by using a native parse/stringify...)

An improvement on JSON-BigInt
We could, for example, replace the bignumber.js library that JSON-BigInt uses by simply parsing using BigInt and let users know the lib only supports Node v10 and up and reminding them to use the --harmony-bigint flag to turn on support.
Looking at the relevant snippet from the lib:
<...snip...>
number = +string;
if (!isFinite(number)) {
error("Bad number");
} else {
if (BigNumber == null)
BigNumber = require('bignumber.js');
//if (number > 9007199254740992 || number < -9007199254740992)
// Bignumber has stricter check: everything with length > 15 digits disallowed
if (string.length > 15)
return (_options.storeAsString === true) ? string : new BigNumber(string);
return number;
}
<...snip...>We can see this should be quite easy.
But can we do better?
Yes.
Ok, how?
By getting a little nuttier.

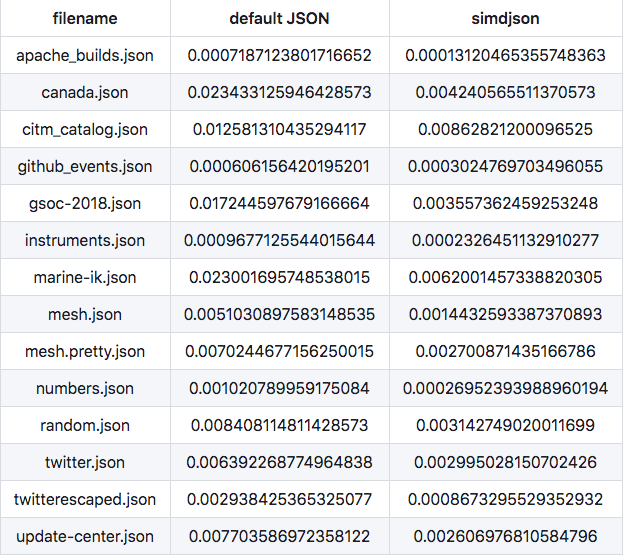
Meet simdjson
In the land of ambitious, these guys rule supreme. The goal of this lib is to be even faster than the native JSON implementation in V8. Not kidding. And they have numbers and everything:
What do we do with it?
Basically the same idea as with JSON-BigInt, simply swap the number parsing implementation with something that correctly parses/stringify-ies BigInts instead.
I wanted to show the relevant portion in their code as well, but uh, it's an entire file just for parsing numbers... And since they have multiple implementations depending on the SIMD instruction set available, it's hard to show any one snippet. Here's a taste:
// parse the number at buf + offset
// define JSON_TEST_NUMBERS for unit testing
//
// It is assumed that the number is followed by a structural ({,},],[) character
// or a white space character. If that is not the case (e.g., when the JSON document
// is made of a single number), then it is necessary to copy the content and append
// a space before calling this function.
//
static really_inline bool parse_number(const uint8_t *const buf,
ParsedJson &pj,
const uint32_t offset,
bool found_minus) {
#ifdef SIMDJSON_SKIPNUMBERPARSING // for performance analysis, it is sometimes useful to skip parsing
pj.write_tape_s64(0); // always write zero
return true; // always succeeds
#else
const char *p = reinterpret_cast<const char *>(buf + offset);
bool negative = false;
if (found_minus) {
++p;
negative = true;
if (!is_integer(*p)) { // a negative sign must be followed by an integer
#ifdef JSON_TEST_NUMBERS // for unit testing
foundInvalidNumber(buf + offset);
#endif
return false;
}
}
const char *const startdigits = p;
uint64_t i; // an unsigned int avoids signed overflows (which are bad)
if (*p == '0') { // 0 cannot be followed by an integer
++p;
if (is_not_structural_or_whitespace_or_exponent_or_decimal(*p)) {
#ifdef JSON_TEST_NUMBERS // for unit testing
foundInvalidNumber(buf + offset);
#endif
return false;
}
i = 0;
} else {
if (!(is_integer(*p))) { // must start with an integer
#ifdef JSON_TEST_NUMBERS // for unit testing
foundInvalidNumber(buf + offset);
#endif
return false;
}
unsigned char digit = *p - '0';
i = digit;
p++;
// the is_made_of_eight_digits_fast routine is unlikely to help here because
// we rarely see large integer parts like 123456789
while (is_integer(*p)) {
digit = *p - '0';
i = 10 * i + digit; // might overflow
++p;
}
}
int64_t exponent = 0;
bool is_float = false;
if ('.' == *p) {
is_float = true;
++p;
const char *const firstafterperiod = p;
if(is_integer(*p)) {
unsigned char digit = *p - '0';
++p;
i = i * 10 + digit;
} else {
#ifdef JSON_TEST_NUMBERS // for unit testing
foundInvalidNumber(buf + offset);
#endif
return false;
}
#ifdef SWAR_NUMBER_PARSING
// this helps if we have lots of decimals!
// this turns out to be frequent enough.
if (is_made_of_eight_digits_fast(p)) {
i = i * 100000000 + parse_eight_digits_unrolled(p);
p += 8;
}
#endif
while (is_integer(*p)) {
unsigned char digit = *p - '0';
++p;
i = i * 10 + digit; // in rare cases, this will overflow, but that's ok because we have parse_highprecision_float later.
}
exponent = firstafterperiod - p;
}
int digitcount = p - startdigits - 1;
int64_t expnumber = 0; // exponential part
if (('e' == *p) || ('E' == *p)) {
is_float = true;
++p;
bool negexp = false;
if ('-' == *p) {
negexp = true;
++p;
} else if ('+' == *p) {
++p;
}
if (!is_integer(*p)) {
#ifdef JSON_TEST_NUMBERS // for unit testing
foundInvalidNumber(buf + offset);
#endif
return false;
}
unsigned char digit = *p - '0';
expnumber = digit;
p++;
if (is_integer(*p)) {
digit = *p - '0';
expnumber = 10 * expnumber + digit;
++p;
}
if (is_integer(*p)) {
digit = *p - '0';
expnumber = 10 * expnumber + digit;
++p;
}
if (is_integer(*p)) {
// we refuse to parse this
#ifdef JSON_TEST_NUMBERS // for unit testing
foundInvalidNumber(buf + offset);
#endif
return false;
}
exponent += (negexp ? -expnumber : expnumber);
}
if (is_float) {
if (unlikely(digitcount >= 19)) { // this is uncommon!!!
// this is almost never going to get called!!!
// we start anew, going slowly!!!
return parse_float(buf, pj, offset,
found_minus);
}
///////////
// We want 0.1e1 to be a float.
//////////
if (i == 0) {
pj.write_tape_double(0.0);
#ifdef JSON_TEST_NUMBERS // for unit testing
foundFloat(0.0, buf + offset);
#endif
} else {
double d = i;
d = negative ? -d : d;
uint64_t powerindex = 308 + exponent;
if(likely(powerindex <= 2 * 308)) {
// common case
d *= power_of_ten[powerindex];
} else {
// this is uncommon so let us move this special case out
// of the main loop
return parse_float(buf, pj, offset,found_minus);
}
pj.write_tape_double(d);
#ifdef JSON_TEST_NUMBERS // for unit testing
foundFloat(d, buf + offset);
#endif
}
} else {
if (unlikely(digitcount >= 18)) { // this is uncommon!!!
return parse_large_integer(buf, pj, offset,
found_minus);
}
i = negative ? 0-i : i;
pj.write_tape_s64(i);
#ifdef JSON_TEST_NUMBERS // for unit testing
foundInteger(i, buf + offset);
#endif
}
return is_structural_or_whitespace(*p);
#endif // SIMDJSON_SKIPNUMBERPARSING
}So which method did I go with?
I totally chickened out and used JSON-BigInt while swapping out their bignumber.js for native BigInts.
I could quote you various benchmarks, time constraints, pragmatism, getting-shit-done sloggans and other nonsense, but the truth is that if you want the absolute best performance you can get, you're gonna have to get a little dirty. In this round, what I did above worked well enough for my purposes.

Redis and Postgres and APIs, Oh My
So now that we have our parsing and stringify and we can move BigInts around our application, we still have a couple problems remaining.
How do you push those values to external DBs, APIs and the like without confusing them with values they can't parse either?

Ah, but they do
Remember all those fetchAsString, supportBigNumbers, returnStrings flags we saw in the docs of popular libraries and services?
Somehow, this turned out to be the easiest part of the this whole journey.
As long as the lib knows what the service (pg, redis) expects, they have methods of converting or providing the correct information to the service.
In Postgres's case, a nice ::bigint cast is enough, and in Redis, well, node_redis has an option to return all strings as Buffers which bypasses the issues (this is a whole other talk).

Relieved

Questions?
Links

Tales From Prod: How I learnt to stop worrying and love the BigInt
By signupskm




