Affordances and alternatives
Martin Biehl

Background
- Given:
- Agent with complex action space
- Complex environment
- How to train / prepare an easy interface for making the agent achieve arbitrary tasks?
- Main problem:
- sparse rewards require finding long sequences of actions
Background
- Broad distinctions of approaches:
- Meta-learning
- Hierarchical RL
- Auxiliary tasks
- intrinsic motivations
- Model based RL
- Neuroevolution
Affordances
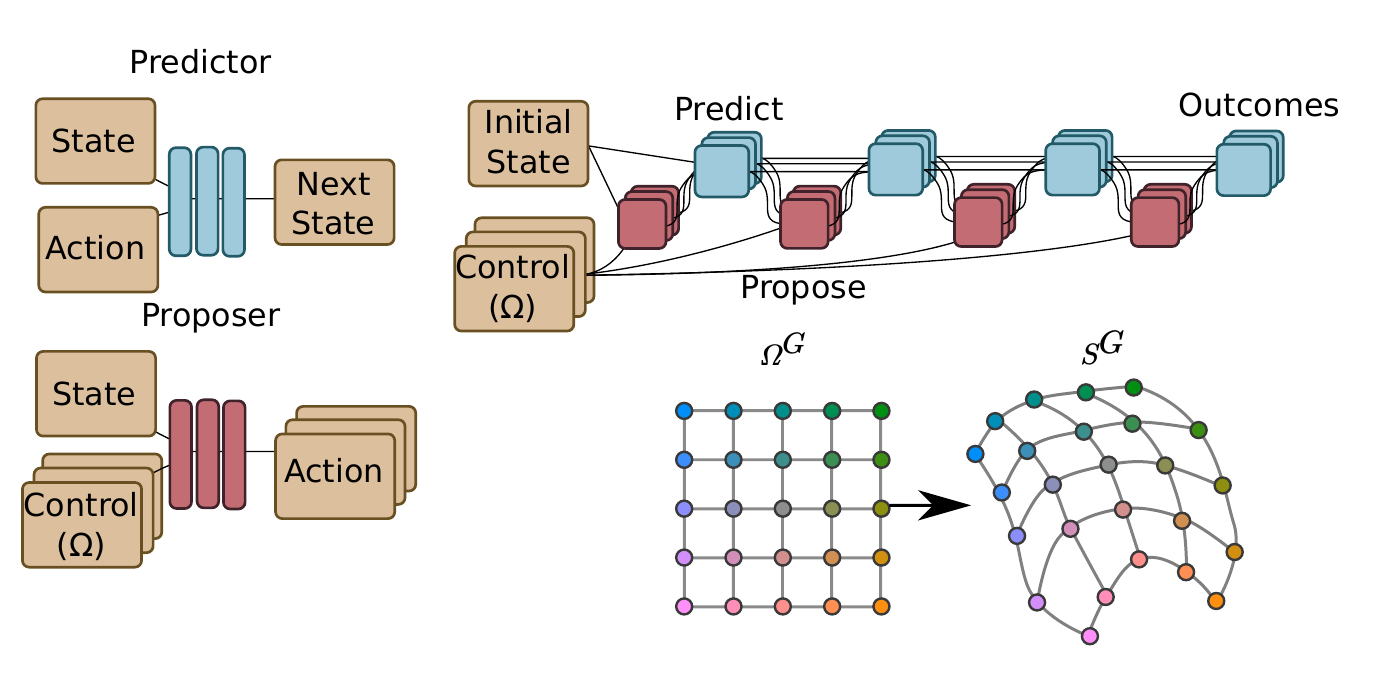
- Learn predictor (world model) \(p(s_{t+1}|a_t,s_t)\) from random samples \((s,a,s')\)
- fix affordance space \(\Omega\), sensor target space \(S_T \in S\) with distance \(d\) and affordance grid \(\Omega_G \subset \Omega\)
- learn proposer (policy) \(\pi_\theta(a|s,\omega)\) where \(\omega \in \Omega\)
- to each \(\omega_i \in \Omega_G\) associate an affordance (policy) \(\pi(a|s,\omega_i)\) and resulting sensor value \(s_f(\omega_i)\)
- learn \(\theta\) with objective \[J(\theta)=\min_{i,j} d(s_f(\omega_i),s_f(\omega_j))\]
Affordances
Affordances
- Can view different \(\omega_i\) as different goals, tasks, or skills
- learning the proposer then means to generate and learn to achieve a set of goals/tasks/skills that pervade the target sensor space
- Can also view an affordance target space as a kind of controllable feature, maybe building up one dimensional and independent target spaces is possible and we get independently controllable features in this way?
Affordances
- Resulting interface:
- Continuous, low dimensional affordance space as a space of "macro-actions" that can achieve outcomes in target sensor space (by interpolation of grid points)
- Disadvantages:
- need distance in target space
- not clear what to do if we want to control high dimensional \(S_T\) with low dimensional \(\Omega\) (\(S^G\) will have to fold)
- all affordances have identical number of time steps (seems inefficient)
MAML
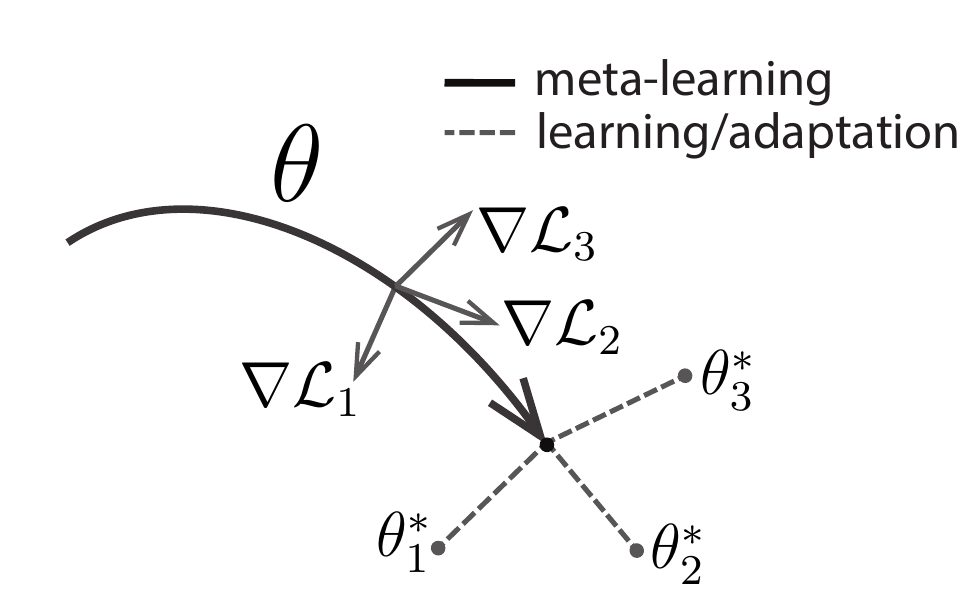
- Model Agnostic Meta Learning
- General idea: pretrain a network with a set of tasks/datasets such that the resulting network adapts the most when trained on one of them \[\theta:=\min_{\bar{\theta}} \sum_i \mathcal{L}_i(\theta_i'(\bar{\theta}))\] where \[\theta_i'(\bar{\theta}) = \bar{\theta} - \alpha \nabla_\theta \mathcal{L}_i(\bar{\theta})\]
MAML
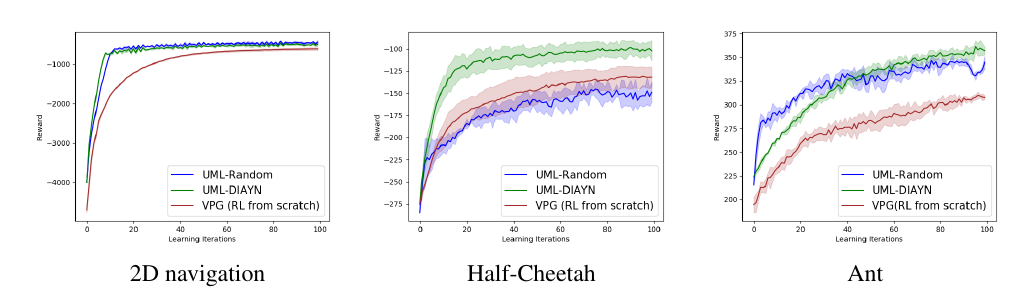
- For reinforcement learning, pretrain a policy network \(\pi(a|s,\theta)\) (https://arxiv.org/pdf/1806.04640.pdf)
- Generate goals/tasks/skills automatically
- pretrain policy for those tasks

MAML
- How to generate goals/tasks/skills (in the form of reward functions \(r_i(s)\)) automatically?
- E.g. via "diversity is all you need" i.e. generate a set of skills \(\pi(a|s,z)\) parameterised by \(z\) such that \(I(Z:S)+H(A|S,Z)\) is maximized. For this a discriminator \(D_\phi(z|s)\) that predicts the skill \(z\) from the state \(s\) is learned and the reward for the task z is then \(\log D_\phi(z|s)\).
- via affordances? Reward for task \(i\) could be distance to outcome \(s(\omega_i)\)
- Novelty search vie evolution?
MAML
- Resulting interface:
- pretrained policy network \(\pi_\theta(a|s)\) that speeds up adaptation:
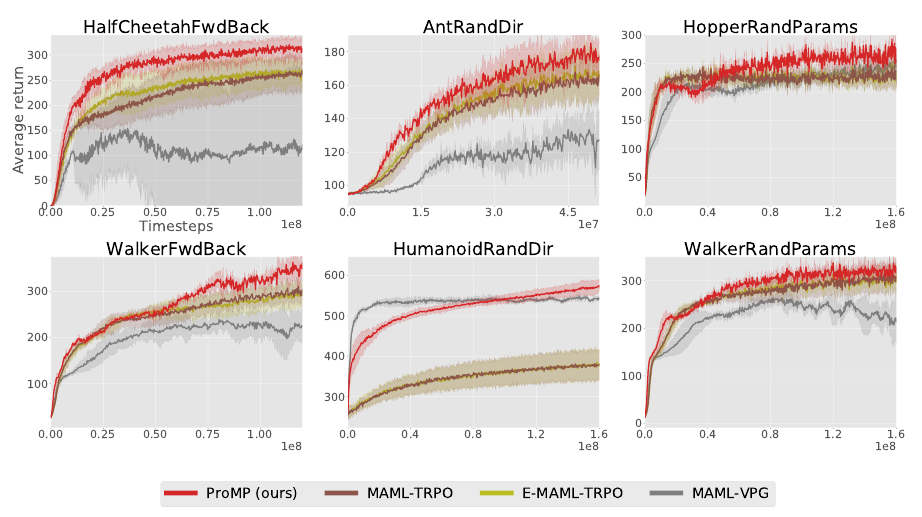
MAESN and ProMP
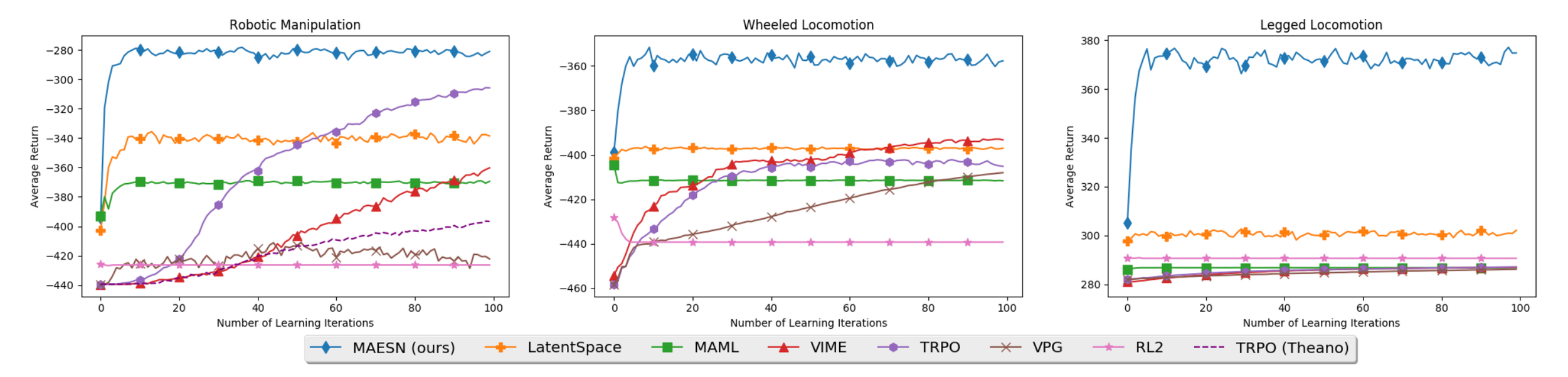
MAESN and ProMP
Modular meta learning
Hierarchical-DQN
- Hierarchical Deep Q-Network for RL
- Learn two \(Q\) functions
- \(Q_2(g,s;\theta_2)\) that evaluates goals/skills/tasks \(g\) as macro-actions in state \(s\)
- \(Q_1(a,s;g,\theta_1)\) that evaluates actions with respect to goal \(g\) in state \(s\)
- Agent picks goal according to \(Q_2(g,s;\theta_2)\) then picks actions according to \(Q_1(a,s;g,\theta_1)\) until goal reached
- Goals/skills/tasks must be predefined or generated separately e.g. DIAYN, affordances,...
Hierarchical-DQN
-
The Option-Critic Architecture
- Parameterize option policies and termination conditions
- Learn both via gradient descent using actor-critic like setup.
-
FeUdal Networks for Hierarchical Reinforcement Learning
- similar, but beats Option-Critic
- Deepmind approach exists.
Auxiliary tasks
- RL with unsupervised auxiliary tasks
- Add additional tasks that (parts of) the architecture have to solve in order to extract more structure from experience
- Auxiliary tasks can be
- control tasks (with own policy networks and Q-functions)
- sensor value control
- feature control (in deeper layers) as in independently controllable features
- value prediction tasks
- control tasks (with own policy networks and Q-functions)
- also use experience replay extensively
Auxiliary tasks
-
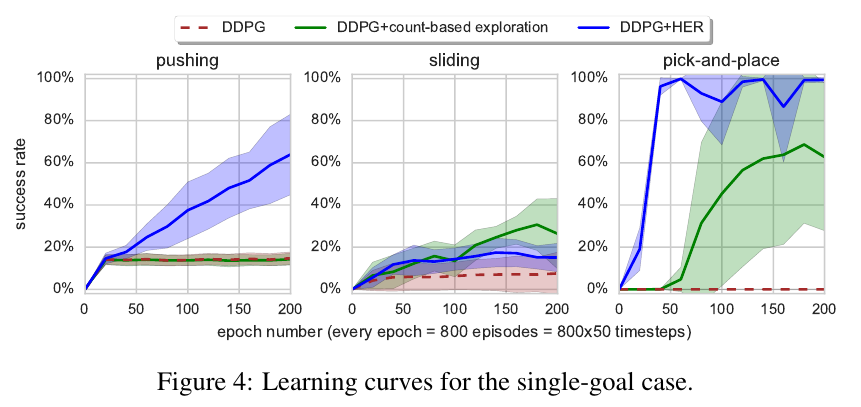
Hindsight experience replay (openAI)
- Create large set of arbitrary binary goals and learn a universal value function \(Q(a,s,g)\) using experience replay for subset of goals after each episode
- Can learn something from unsuccessful experiences
- Can solve bit-flipping up to 40 bits instead of 13
Auxiliary tasks
- Hindsight experience replay
Auxiliary tasks
Intrinsic motivations
- Often implemented as auxiliary tasks
- Prediction based auxiliary task used to be state of the art in Montezuma's revenge (Random network distillation)
- Before that it was a knowledge seeking additional reward (Count based exploration)
- Current state of the art exploits ability to go back to promising situations and explore again from there. When it finds a solution it reinforces it by imitation learning.
Model based meta-RL
- Model based approaches predict future states of the environment and not only future rewards (like Q-functions do)
- The advantage is high data-efficiency, problems are model misspecification and computational cost
Model based meta-RL
-
Meta Reinforcement Learning with Latent Variable Gaussian Processes (Saemundsson et al)
-
Introduce latent (meta-) variable \(h\) that identifies the environment (e.g. mass and length of pole in cart pole)
-
model environment dynamics \(p(x_{t+1}|a_t,x_t,h,\theta)\) with gaussian process
-
train the gaussian process on datasets from different environments
-
infer \(h\) on test environments and use it to predict future / select actions
-
-
Similar to FEP without intrinsic motivation
Model based meta-RL
-
Model-Based Reinforcement Learning via Meta-Policy Optimization (Clavera et al)
-
Based on MAML, but identical reward different dynamics
-
learn ensemble of DNN deterministic environment models on different subsets of data
-
use usual MAML to train policy that can adapt to each of them as fast as possible
-
Nice exploration side effects
-
Model based meta-RL
-
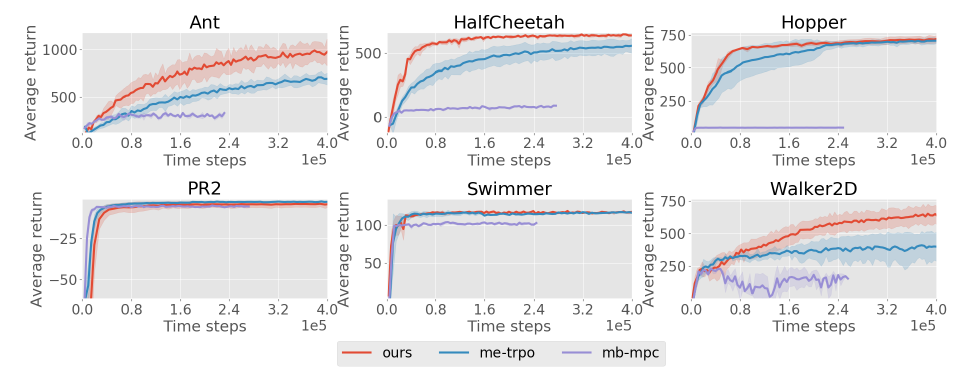
Model-Based Reinforcement Learning via Meta-Policy Optimization (Clavera et al)
- Better than (non-MAML) model free approaches
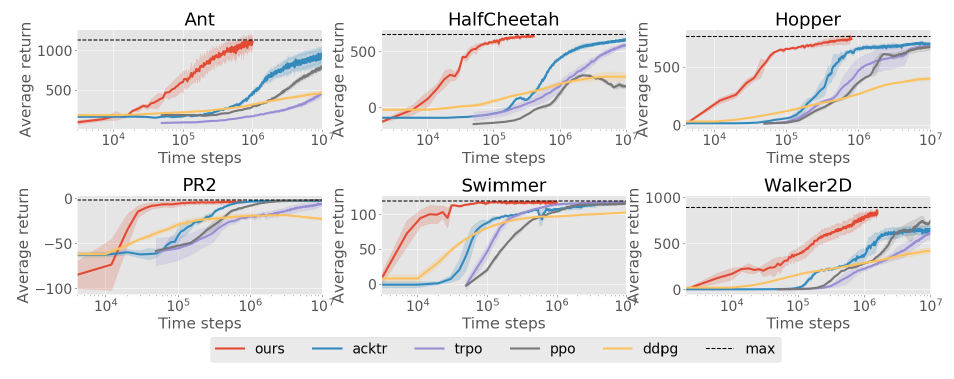
Model based meta-RL
-
Model-Based Reinforcement Learning via Meta-Policy Optimization (Clavera et al)
- Better than SOTA model based approaches
CF-GPS
-
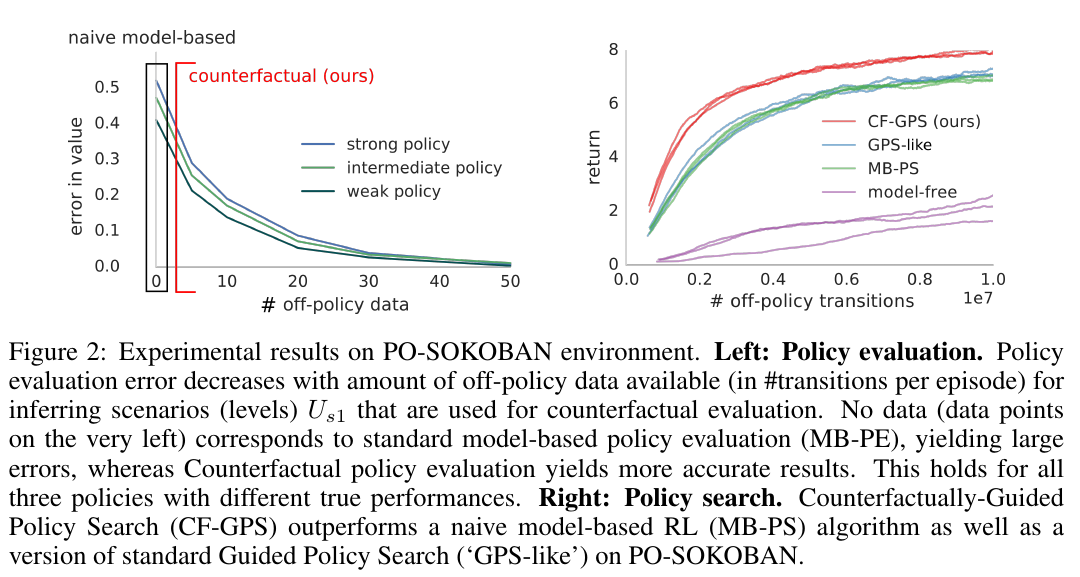
WOULDA, COULDA, SHOULDA :COUNTERFACTUALLY -GUIDED POLICY SEARCH (Buesing et al., deepmind)
-
Model baseed RL using structural causal models with interventional calculus
-
Show that interventional calculus allows improved counterfactual policy evaluation
-
CF-GPS
Neuroevolution
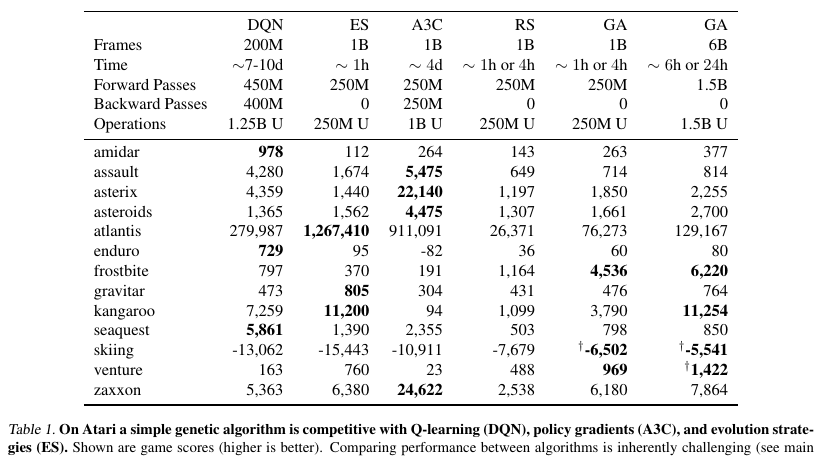
- Instead of gradient descent use genetic algorithm to generate deep Q-functions
- fitness is novelty i.e. distance to nearest neighbors in genome space
Neuroevolution
- Learns an environment model on latent space of autoencoder
- then learns to solve problems inside the model
Deep RL methods
Text
deck
By slides_martin



