Stephen Merity
@smerity
AI By The Bay

* I like deep learning but I spend a lot of time ranting against the hype ... ^_^


Deep learning is a
jackhammer

Deep learning is a
jackhammer
-
It can be difficult to use (hyperparameters)
Deep learning is a
jackhammer
-
It can be difficult to use (hyperparameters)
-
It can be expensive and slow (GPU++)
Deep learning is a
jackhammer
"As technology advances, the time to train a deep neural network remains constant." - Eric Jang
(playing on Blinn's law)
-
It can be difficult to use (hyperparameters)
-
It can be expensive and slow (GPU++)
Deep learning is a
jackhammer
-
It can be difficult to use (hyperparameters)
-
It can be expensive and slow (GPU++)
-
It's the wrong tool for many situations
Deep learning is a
jackhammer
Example: While it might be possible to make scrambled eggs with a jackhammer, I'm not going to give you extra points for doing that
-
It can be difficult to use (hyperparameters)
-
It can be expensive and slow (GPU++)
-
It's the wrong tool for many situations
Deep learning is a
jackhammer
Having said that, deep learning can be
an incredibly useful tool
in the situations it's best suited for
Key idea repeated today
Whenever you see a neural network architecture, ask yourself: how hard is it to pass information from one end to the other?
Specifically, we'll be thinking in terms of:
information bottlenecks
Memory in neural networks
Neural networks already have "memory"
by default - their hidden state (h1, h2, ...)

Memory in neural networks
When your network decreases in capacity,
the network has to discard information
This is not always a problem,
you just need to be aware of it

Memory in neural networks
If we're classifying digits in MNIST,
the earliest input is the (28 x 28) pixel values
We may set up a three layer network that learns:
Pixels (28 x 28 = 784 neurons),
Stroke types (~100 neurons),
Digit (10 neurons)

Memory in neural networks
If we're classifying digits in MNIST,
the earliest input is the (28 x 28) pixel values
We may set up a three layer network that learns:
Pixels (28 x 28 = 784 neurons),
Stroke types (~100 neurons),
Digit (10 neurons)
Memory in neural networks
If we're classifying digits in MNIST,
the earliest input is the (28 x 28) pixel values
We may set up a three layer network that learns:
Pixels (28 x 28 = 784 neurons),
Stroke types (~100 neurons),
Digit (10 neurons)
Memory in neural networks
If we're classifying digits in MNIST,
the earliest input is the (28 x 28) pixel values
Information is lost but the relevant information
for our question has been extracted
Memory in neural networks
For word vectors, compression can be desirable
By forcing a tiny hidden state, we force the NN to map similar words to similar representations

"New ____ city"
"York"
Memory in neural networks
For word vectors, compression can be desirable
Words with similar contexts (color/colour) or similar partial usage (queen/princess) are mapped to similar representations without loss
"New ____ city"
"York"
The limits of restricted memory
Imagine I gave you an article or an image,
asked you to memorize it,
took it away,
and then quizzed you on the contents
You'd likely fail
(even though you're very smart!)
The limits of restricted memory
Imagine I gave you an article or an image,
asked you to memorize it,
took it away,
and then quizzed you on the contents
-
You can't store everything in working memory
-
Without the question to direct your attention,
you waste memory on unimportant details

The limits of restricted memory
Hence our models can work well when there's a single question: what's the main object?

The limits of restricted memory
Example from the Visual Genome dataset
The limits of restricted memory

Example from the Visual Genome dataset
- An RNN consumes and generates a sequence
- Characters, words, ...
- The RNN updates an internal state h according to the:
-
existing hidden state h and the current input x
-
existing hidden state h and the current input x
If you're not aware of the GRU or LSTM, you can consider them as improved variants of the RNN
(do read up on the differences though!)
h_t = RNN(x_t, h_{t-1})
Recurrent Neural Networks
A simple recommendation may be:
why not increase the capacity of our hidden state?
Unfortunately the parameters increase
quadratically with h
Even if we do, increased hidden state is more prone to overfitting - especially for RNNs
Hidden state is expensive
Regularizing RNN
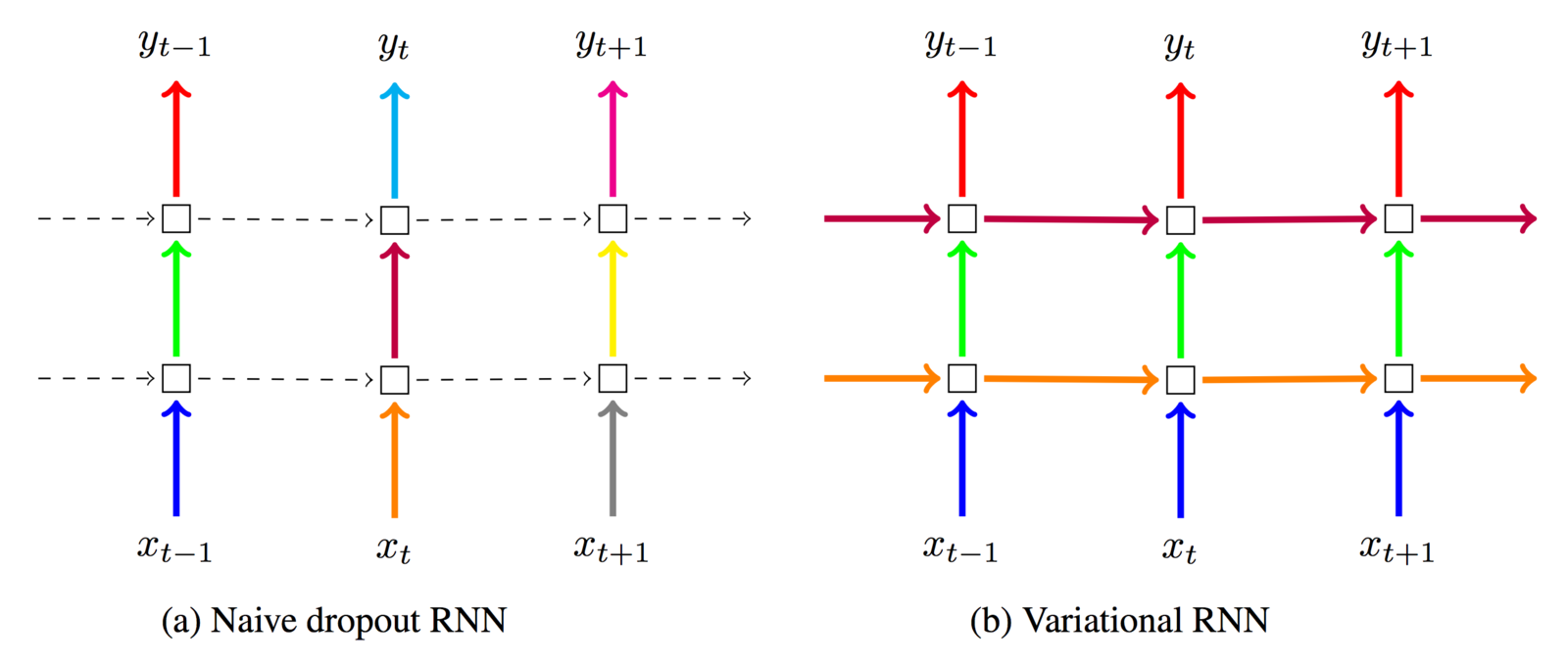
Dropout works well on most neural networks
but not for the memory of an RNN
Regularizing RNN
Variational dropout (Gal et al. 2015)
I informally refer to it as "locked dropout":
you lock the dropout mask once it's used
Regularizing RNN
Variational dropout (Gal et al. 2015)
Gives major improvement over a standard RNN, simplifies the prevention of overfitting immensely
Regularizing RNN
IMHO, though Gal et al. did it for LM, best for
recurrent connections on short sequences
(portions of the hidden state h are blacked out until the dropout mask is reset)
Regularizing RNN
Zoneout (Krueger et al. 2016)
Stochastically forces some of the recurrent units in h to maintain their previous values
Imagine a faulty update mechanism:
where delta is the update and m the dropout mask
h_t = h_{t-1} + m \odot \delta_t
Regularizing RNN
Zoneout (Krueger et al. 2016)
Offers two main advantages over "locked" dropout
+ "Locked" dropout means |h| x p of the hidden units are not usable (dropped out)
+ With zoneout, all of h remains usable
(important for lengthy stateful RNNs in LM)
+ Zoneout can be considered related to stochastic depth which might help train deep networks
Regularizing RNN
Both these recurrent dropout techniques are easy to implement and they're already a part of many frameworks
Example: one line change in Keras
for variational dropout
Stunningly, you can supply English as input, German as expected output, and the model learns to translate
After each step, the hidden state contains an encoding of the sentence up until that point, with S attempting to encode the entire sentence
Translation as an example

The encoder and decoder are the RNNs
Stunningly, you can supply English as input, German as expected output, and the model learns to translate
The key issue comes in the quality of translation for long sentences - the entire input sentence must be compressed to a single hidden state ...
Translation as an example
The encoder and decoder are the RNNs
Figure from Bahdanau et al's
Neural Machine Translation by Jointly Learning to Align and Translate

This kind of experience is part of Disney’s efforts to "extend the lifetime of its series and build new relationships with audiences via digital platforms that are becoming ever more important," he added.
38 words
Neural Machine Translation
Human beings translate a part at a time, referring back to the original source sentence when required
How can we simulate that using neural networks?
By providing an attention mechanism
Translation as an example
As we process each word on the decoder side, we query the source encoding for relevant information
For long sentences, this allows a "shortcut" for information - the path is shorter and we're not constrained to the information from a single hidden state
Translation as an example

For each hidden state we produce an attention score
We ensure that
(the attention scores sum up to one)
We can then produce a context vector, or a weighted summation of the hidden states:
Attention in detail
c = \sum a_i h_i
h_i
a_i
\sum a_i = 1
For each hidden state we produce an attention score
We can then produce a context vector, or a weighted summation of the hidden states:
Attention in detail
c = \sum a_i h_i
h_i
a_i
How do we ensure that our attention scores sum to 1?
(also known as being normalized)
We use our friendly neighborhood softmax function
on our unnormalized raw attention scores r
Attention in detail
\sum a_i = 1
a_i = \frac{e^{r^i}}{\sum_j e^{r^j}}
Finally, to produce the raw attention scores, we have a number of options, but the two most popular are:
Inner product between the query and the hidden state
Feed forward neural network using query and hidden state
(this may have one or many layers)
Attention in detail
r_i = \mathbf q \cdot \mathbf h_i = \sum_j q_j {h_i}_j
r_i = \text{tanh}(W[h_i;q] + b)
Context vector in green
Attention score calculations in red
Attention in detail
Visualizing the attention

European Economic Area <=> zone economique europeenne

Results from Bahdanau et al's
Neural Machine Translation by Jointly Learning to Align and Translate
European Economic Area <=> zone economique europeenne
Neural Machine Translation
When we know the question being asked
we only need to extract the relevant information
This means that we don't compute or store unnecessary information
More efficient and helps avoid the
information bottleneck
Attention in NMT
Neural Machine Translation


Our simple model
More depth and forward + backward
Residual connections
Neural Machine Translation
If you're interested in what production NMT looks like,
"Peeking into the architecture used for Google's NMT"
(Smerity.com)
Attention has been used successfully across many domains for many tasks
The simplest extension is allowing one or many passes over the data
As the question evolves, we can look at different sections of the input as the model realizes what's relevant
Examples of attention

QA for the DMN
From my colleagues Kumar et al. (2015) and Xiong, Merity, Socher (2016)

Rather than the hidden state being a word as in translation,
it's either a sentence for text or a section of an image
The DMN's input modules

Episodic Memory
Some tasks required multiple passes over memory for a solution
Episodic memory allows us to do this

Visualizing visual QA

Visualizing visual QA

Visualizing visual QA
What if you're in a foreign country and you're ordering dinner ....?
You see what you want on the menu but
can't pronounce it :'(
This is the motivating idea behind
Pointer Networks (Vinyals et al. 2015)
Pointer Networks
What if you're in a foreign country and you're ordering dinner ....?
You see what you want on the menu but
can't pronounce it :'(
Pointer Networks help tackle the
out of vocabulary problem
(most models are limited to a pre-built vocabulary)
Pointer Networks

Convex Hull
Delaunay Triangulation
The challenge: we don't have a "vocabulary" to refer to our points (i.e. P1 = [42.09, 19.5147])
We need to reproduce that exact point
Pointer Networks

Pointer Networks


Pointer Networks

Attention Sum (Kadlec et al. 2016)
Pointer networks avoid storing the identity of the word to be produced
Why is this important?
In many tasks, the name is a placeholder.
In many tasks, the documents are insanely long.
(you'll never have enough working memory!)
Pointer networks avoid storing that redundant data
Pointer Networks
Extending QA attention passes w/ Dynamic Coattention Network
DMN and other attention mechanisms show the potential for multiple passes to perform complex reasoning
Particularly useful for tasks where transitive reasoning is required or where answers can be progressively refined
Can this be extended to full documents?
Note: work from my amazing colleagues -
Caiming Xiong, Victor Zhong, and Richard Socher
Extending QA attention passes w/ Dynamic Coattention Network
Stanford Question Answering Dataset (SQuAD) uses Wikipedia articles for question answering over textual spans


Dynamic Coattention Network
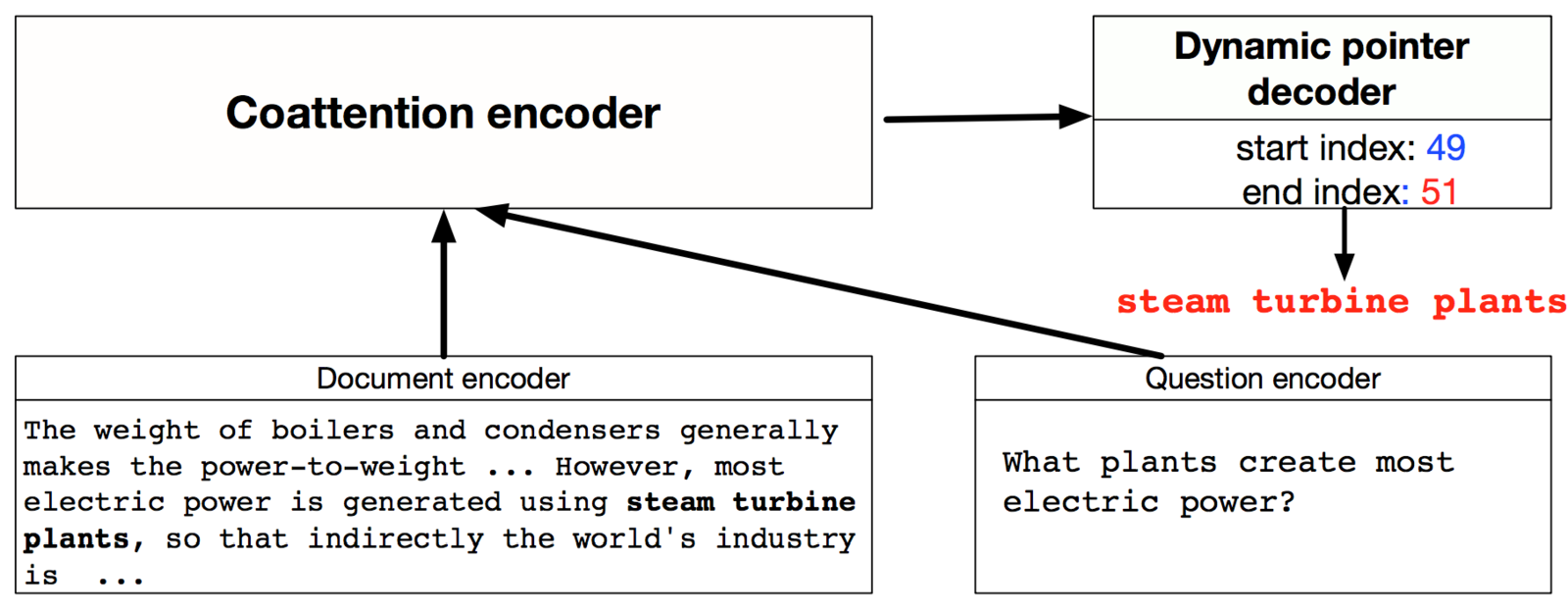
The overarching concept is relatively simple:
Dynamic Coattention Network
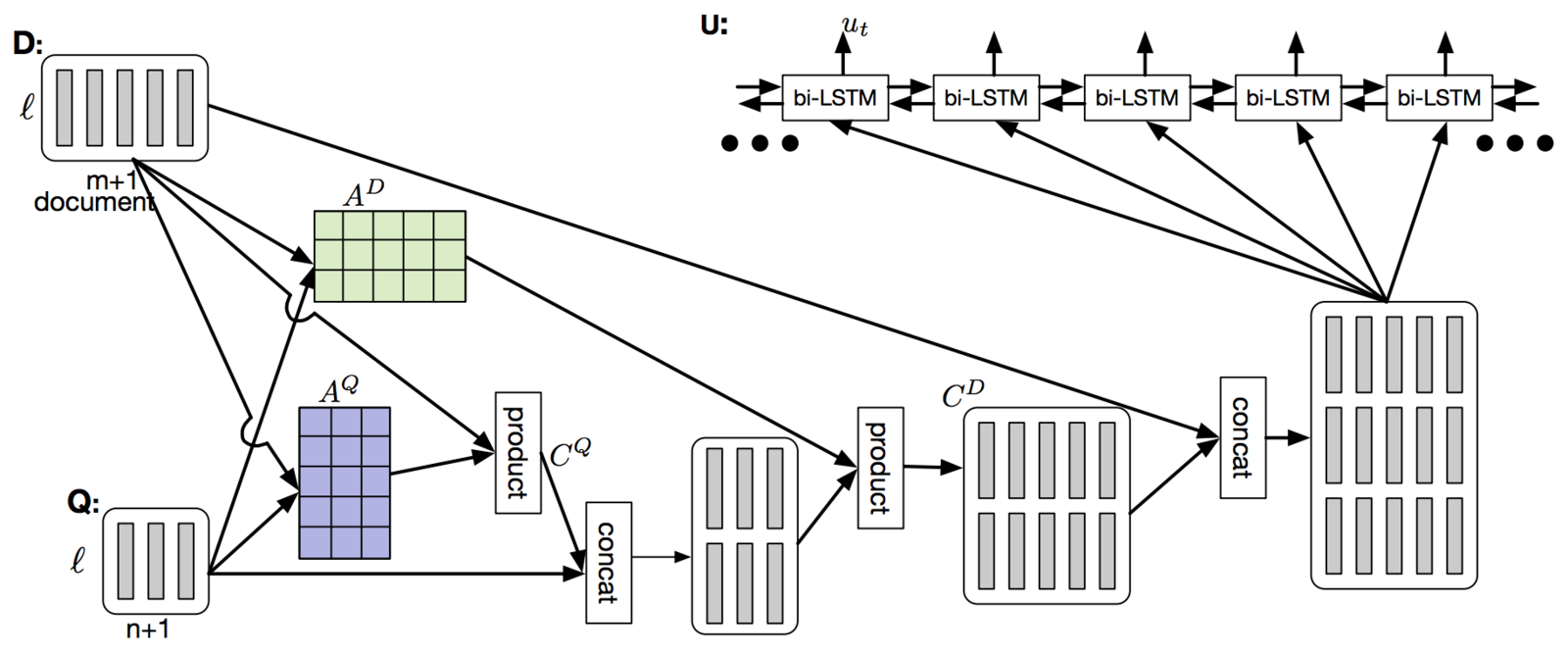
Encoder for the Dynamic Coattention Network
It's the specific implementation that kills you ;)
Dynamic Coattention Network

Explaining the architecture fully is complicated but intuitively:
Iteratively improve the start and end points of the answer
as we perform more passes over the data
Dynamic Coattention Network
Two strong advantages come out of the DCN model:
- SQuAD provides an underlying dataset that generalizes well
- Like the pointer network, OoV terms are not a major issue
Big issue:
What if the correct answer isn't in our input..?
... then pointer network can never be correct!
We could use an RNN - it has a vocabulary - but then we lose out on out of vocabulary words that the pointer network would get ...
Pointer Networks

The core idea: decide whether to use the RNN or the pointer network depending on how much attention a sentinel receives
Pointer Sentinel (Merity et al. 2016)

The core idea: decide whether to use the RNN or the pointer network depending on how much attention a sentinel receives
Pointer Sentinel (Merity et al. 2016)
The pointer decides when to back off to the vocab softmax
This is important as the RNN hidden state has limited capacity and can't accurately recall what's in the pointer
The longer the pointer's window becomes,
the more true this is
Why is the sentinel important?
The pointer will back off to the vocabulary if it's uncertain
(specifically, if nothing in the pointer window attracts interest)
"Degrades" to a straight up mixture model:
If g = 1, only vocabulary
If g = 0, only pointer
Why is the sentinel important?
the pricing will become more realistic which should help management said bruce rosenthal a new york investment banker
...
they assumed there would be major gains in both probability and sales mr. ???
Pointer Sentinel-LSTM Example

a merc spokesman said the plan has n't made much difference in liquidity in the pit <eos>
it 's too soon to tell but people do n't seem to be unhappy with it he ???

Pointer Sentinel-LSTM Example
the fha alone lost $ N billion in fiscal N the government 's equity in the agency essentially its reserve fund fell to minus $ N billion <eos>
the federal government has had to pump in $ N ???

Pointer Sentinel-LSTM Example
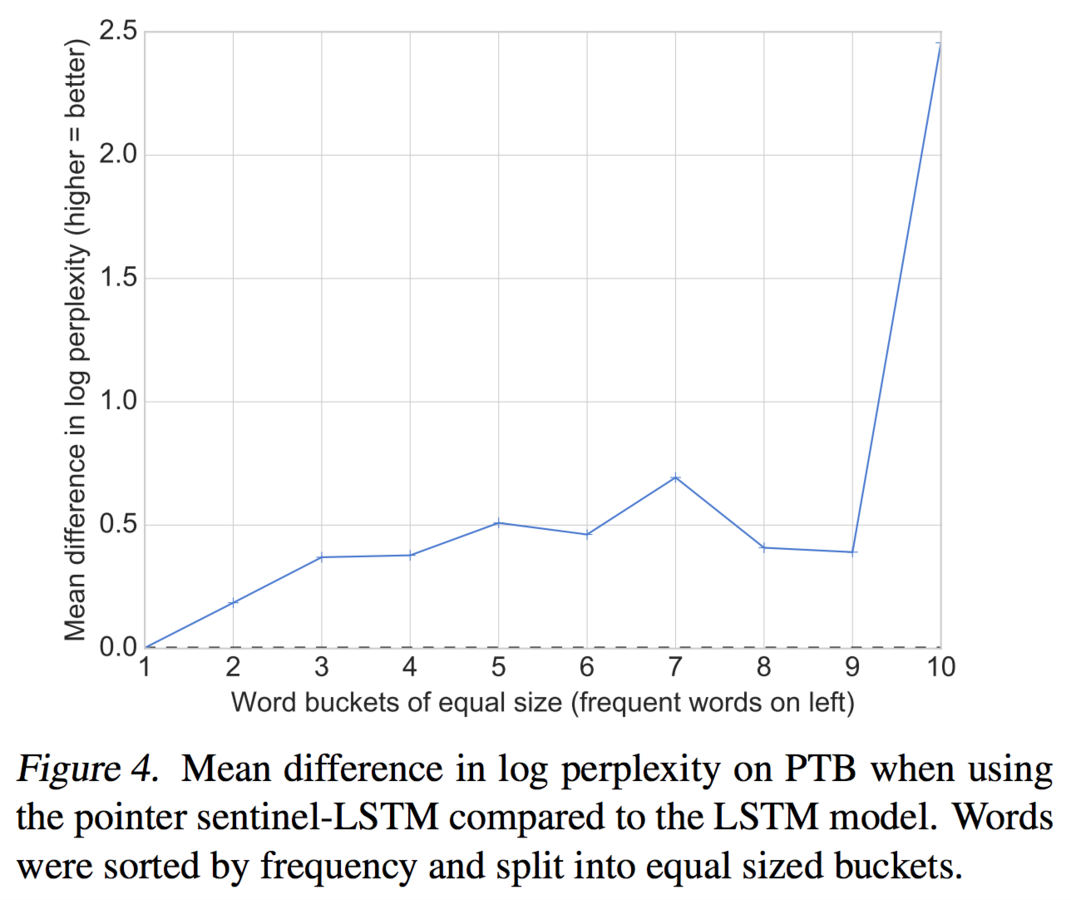
Frequent
Rare
Pointer sentinel really helps for rare words
Facebook independently tried a similar tactic:
take a pretrained RNN and train an attention mechanism that looks back up to 2000 words for context
Neural Cache Model (Grave et al. 2016)
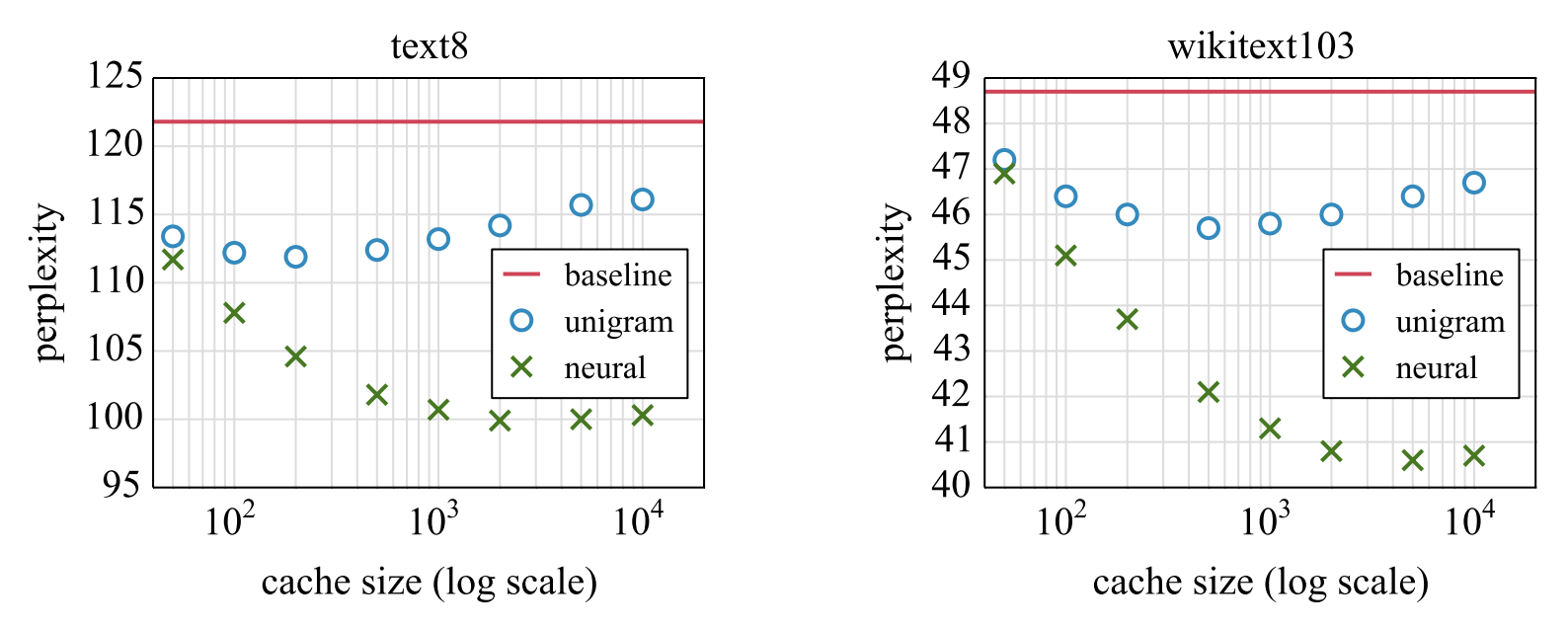
This indicates even trained RNN models aren't able to properly utilize their history, whether due to lack of capacity or issues with training ...
Neural Cache Model (Grave et al. 2016)
For image captioning tasks,
many words don't come from the image at all
How can we indicate
(a) what parts of the image are relevant
and
(b) note when the model doesn't need to look at the image
Can the model do better by not distracting itself with the image?
From colleagues Lu, Xiong, Parikh*, Socher
* Parikh from Georgia Institute of Technology
Image Captions (Lu et al. 2016)
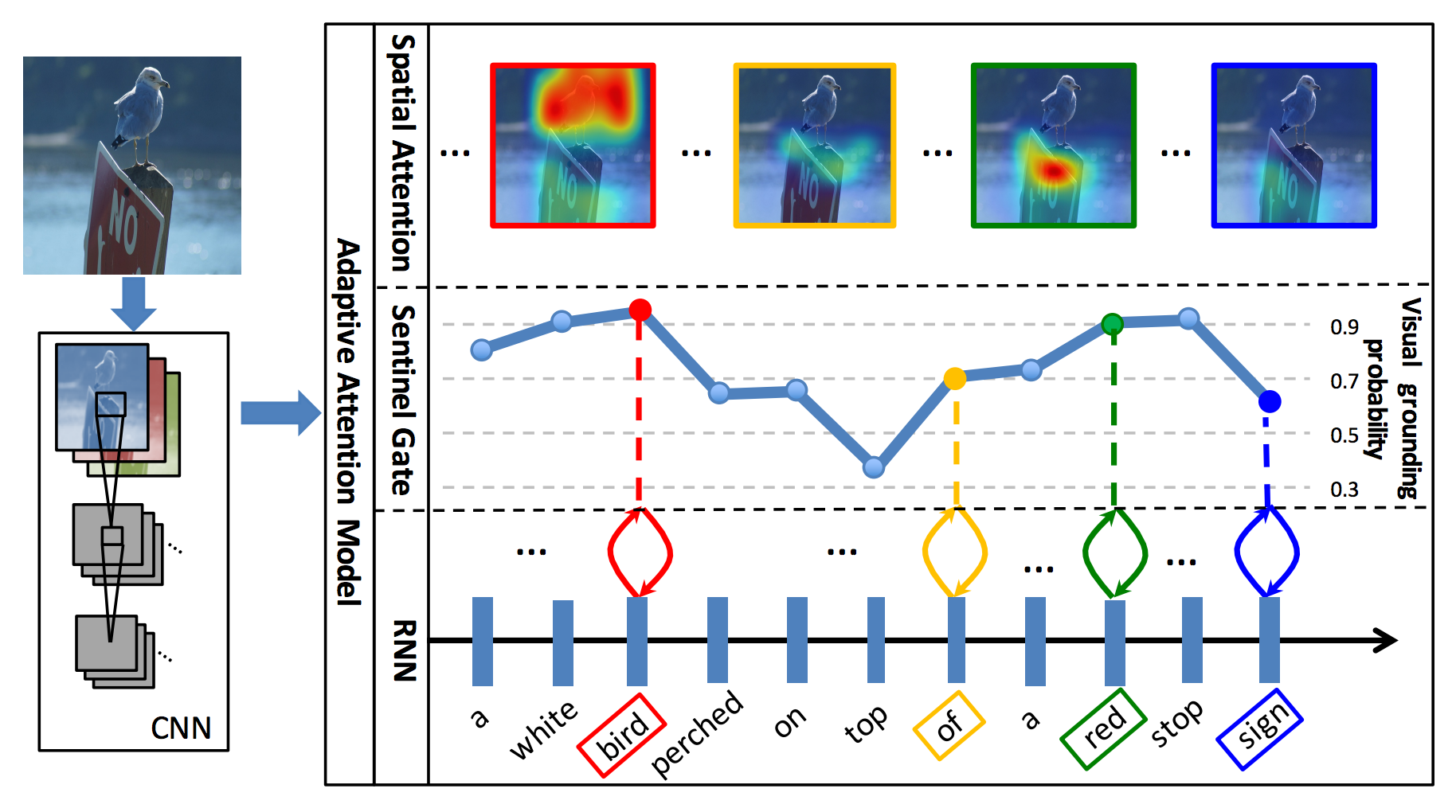
The visual QA work was extended to producing sentences and also utilized a sentinel for when it wasn't looking at the image to generate
Image Captions (Lu et al. 2016)
Image Captions (Lu et al. 2016)

Using the sentinel we can tell when and where the model looks
Image Captions (Lu et al. 2016)

Using the sentinel we can tell when and where the model looks
Image Captions (Lu et al. 2016)

Using the sentinel we can tell when and where the model looks
Back to our key idea
Whenever you see a neural network architecture, ask yourself: how hard is it to pass information from one end to the other?
Memory allows us to store far more than the standard RNN hidden state of size h
Attention gives us a way of accessing and extracting memory when it's relevant
Not only does it help with accuracy, the attention visualizations can look amazing too! ;)
(oh - and they're actually useful as debugging aids)
Best of all ...
Contact me online at @smerity
or read our research at Salesforce MetaMind
metamind.io
Review these slides at slides.com/smerity/
Frontiers of Memory and Attention in Deep Learning
By smerity




