The Frontiers of Memory and Attention in Deep Learning
Stephen Merity
@smerity
Classification

With good data, deep learning can give high accuracy in image and text classification
It's trivially easy to train your own classifier
with near zero ML knowledge
It's so easy that ...

6th and 7th grade high school students created a custom vision classifier for TrashCam
[Trash, Recycle, Compost] with 90% accuracy
Intracranial Hemorrhage

Work by MM colleagues: Caiming Xiong, Kai Sheng Tai, Ivo Mihov, ...
Deep learning and ImageNet

In 2012, AlexNet hit 16.4% error (top-5)
Second best model (non CNN) was 26.2%
Deep learning and ImageNet
Special note: single sample human error..?
5.1%
Advances leveraged via GPUs

AlexNet training throughput based on 20 iterations
Slide from Julie Bernauer's NVIDIA presentation
(but don't use DL for everything!)

* I rant against deep learning a lot ... ^_^

Beyond classification ...

VQA dataset: http://visualqa.org/
Beyond classification ...

* TIL Lassi = popular, traditional, yogurt based drink from the Indian Subcontinent
Question Answering

Visual Genome: http://visualgenome.org/
Question Answering

Visual Genome: http://visualgenome.org/
Question Answering
1 Mary moved to the bathroom. 2 John went to the hallway. 3 Where is Mary? bathroom 1 4 Daniel went back to the hallway. 5 Sandra moved to the garden. 6 Where is Daniel? hallway 4 7 John moved to the office. 8 Sandra journeyed to the bathroom. 9 Where is Daniel? hallway 4 10 Mary moved to the hallway. 11 Daniel travelled to the office. 12 Where is Daniel? office 11 13 John went back to the garden. 14 John moved to the bedroom. 15 Where is Sandra? bathroom 8 1 Sandra travelled to the office. 2 Sandra went to the bathroom. 3 Where is Sandra? bathroom 2
Extract from the Facebook bAbI Dataset
Human Question Answering
Imagine I gave you an article or an image, asked you to memorize it, took it away, then asked you various questions.
Even as intelligent as you are,
you're going to get a failing grade :(
Why?
- You can't store everything in working memory
- Without a question to direct your attention,
you waste focus on unimportant details
Optimal: give you the input data, give you the question, allow as many glances as possible
Think in terms of
Information Bottlenecks
Where is your model forced to use a compressed representation?
Most importantly,
is that a good thing?
Wait... wait wait wait...
Neural Networks
...
Compression
I've heard this before..?
I swear I'm not trolling you :'(

(...or asking for VC funding ;))
This is the real world

No-one is doing CNN compression
... except Magic Pony

... Magic Pony ...

Stills from streaming video
(same bitrate for left and right)
... now a bird / pony hybrid ^_^
Thinking of
Neural Networks
in terms of
Compression
Word Vectors
Convert "dog" into a
100 dimensional vector
dog
Word Vectors
Convert "dog" into a
100 dimensional vector

Word Vectors
Convert "dog" into a
100 dimensional vector

Word Vectors
Convert "dog" into a
100 dimensional vector
0.11008 -0.38781 -0.57615 -0.27714 0.70521 0.53994 -1.0786 -0.40146 1.1504 -0.5678 0.0038977 0.52878 0.64561 0.47262 0.48549 -0.18407 0.1801 0.91397 -1.1979 -0.5778 -0.37985 0.33606 0.772 0.75555 0.45506 -1.7671 -1.0503 0.42566 0.41893 -0.68327 1.5673 0.27685 -0.61708 0.64638 -0.076996 0.37118 0.1308 -0.45137 0.25398 -0.74392 -0.086199 0.24068 -0.64819 0.83549 1.2502 -0.51379 0.04224 -0.88118 0.7158 0.38519
Word Vectors via word2vec
... with the dog running behind ...
... the black dog barked at ...
... most dangerous dog breeds focuses ...
... when a dog licks your ...
... the massive dog scared the postman ...
Word Vectors via word2vec
... with the ___ running behind ...
... the black ___ barked at ...
... most dangerous ___ breeds focuses ...
... when a ___ licks your ...
... the massive ___ scared the postman ...
Continuous Bag of Words (CBOW):
given the context, guess the word
Word Vectors via word2vec
... with the dog running behind ...
... the black dog barked at ...
... most dangerous dog breeds focuses ...
... when a dog licks your ...
... the massive dog scared the postman ...
Skipgram:
given the word, guess the context
Word Vectors via word2vec
... with the dog running behind ...
... the black dog barked at ...
... most dangerous dog breeds focuses ...
... when a dog licks your ...
... the massive dog scared the postman ...
[..., 1.02, 0.42, -0.28, ...]
(our N dimensional vector)
Word Vectors via word2vec
... with the dog running behind ...
... the black dog barked at ...
... most dangerous dog breeds focuses ...
... when a dog licks your ...
... the massive dog scared the postman ...
[..., 1.02, 0.42, -0.28, ...]
(our N dimensional vector)

Word Vectors via word2vec
... with the dog running behind ...
... the black dog barked at ...
... most dangerous dog breeds focuses ...
... when a dog licks your ...
... the massive dog scared the postman ...
Compression makes sense here (generalization)
(British / Australian color vs American colour)
Word Vectors via word2vec
... with the dog running behind ...
... the black dog barked at ...
... most dangerous dog breeds focuses ...
... when a dog licks your ...
... the massive dog scared the postman ...
Compression makes sense here (generalization)
(verbs, singular/plural, ...)
Word Vectors via word2vec
... with the dog running behind ...
... the black dog barked at ...
... most dangerous dog breeds focuses ...
... when a dog licks your ...
... the massive dog scared the postman ...
"You shall know a word by the company it keeps"
(Firth)
Word Vectors via word2vec

king - man + woman
~= queen
(example image from GloVe - not word2vec but conceptually similar)
Word Vectors via word2vec
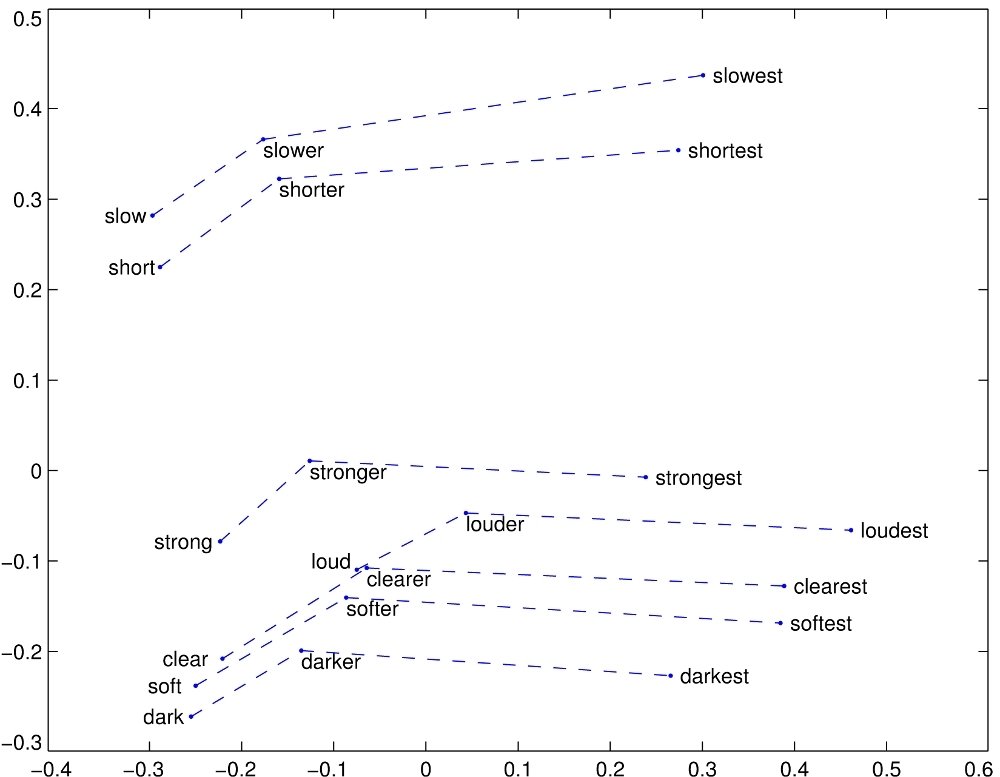
(example image from GloVe - not word2vec but conceptually similar)
Word Vectors via word2vec
... with the dog running behind ...
... the black dog barked at ...
... most dangerous dog breeds focuses ...
... when a dog licks your ...
... the massive dog scared the postman ...
[..., 1.02, 0.42, -0.28, ...]
(our N dimensional vector)
(Little) Memory, (No) Attention
[..., 1.02, 0.42, -0.28, ...]
Recurrent Neural Network (RNN)
- An RNN consumes and/or generates a sequence
- Characters, words, ...
- The RNN updates an internal state h according to the:
- existing hidden state h and the current input x
h_t = RNN(x_t, h_{t-1})
Figure from Chris Olah's Visualizing Representations
Recurrent Neural Network (RNN)
- An RNN consumes and/or generates a sequence
- Characters, words, ...
- The RNN updates an internal state h according to the:
- existing hidden state h and the current input x
h_t = RNN(x_t, h_{t-1})
Figure from Chris Olah's Visualizing Representations
Input
Hidden State
Recurrent Neural Network (RNN)
h_t = RNN(x_t, h_{t-1})
Figure from Chris Olah's Visualizing Representations
If you hear
Gated Recurrent Network (GRU)
or
Long Short Term Memory (LSTM)
just think RNN
Neural Machine Translation
Figure from Chris Olah's Visualizing Representations
Figure from Bahdanau et al's
Neural Machine Translation by Jointly Learning to Align and Translate

Neural Machine Translation
Figure from Bahdanau et al's
Neural Machine Translation by Jointly Learning to Align and Translate
"Quora requires users to register with their real names rather than an Internet pseudonym ( screen name ) , and visitors unwilling to log in or use cookies have had to resort to workarounds to use the site ."
39 words
Attention and Memory
Figure from Chris Olah's Visualizing Representations
We store the hidden state at each timestep
(i.e. after reading "I", "think", "...")
We can later query it with attention. Attention allows us to sum up a region of interest when we get up to the appropriate section!
h1 h2 h3 h4
Memory:
Attention and Memory
Figure from Chris Olah's Visualizing Representations
We store the hidden state at each timestep
(i.e. after reading "I", "think", "...")
We can later query it with attention. Attention allows us to sum up a region of interest when we get up to the appropriate section!
h1 h2 h3 h4
Memory:
a1 a2 a3 a4 s.t. sum(a) = 1
Attention:
Neural Machine Translation


Results from Bahdanau et al's
Neural Machine Translation by Jointly Learning to Align and Translate
European Economic Area <=> zone economique europeenne
QA for Dynamic Memory Networks
- A modular and flexible DL framework for QA
- Capable of tackling wide range of tasks and input formats
- Can even been used for general NLP tasks (i.e. non QA)
(PoS, NER, sentiment, translation, ...)
Ask Me Anything: Dynamic Memory Networks for Natural Language Processing (Kumar et al., 2015)
Dynamic Memory Networks for Visual and Textual Question Answering (Xiong et al., 2016)
For full details:
Related Attention/Memory Work
- Sequence to Sequence (Sutskever et al. 2014)
- Neural Turing Machines (Graves et al. 2014)
- Teaching Machines to Read and Comprehend
(Hermann et al. 2015) - Learning to Transduce with Unbounded Memory (Grefenstette 2015)
- Structured Memory for Neural Turing Machines
(Wei Zhang 2015)
- Memory Networks (Weston et al. 2015)
- End to end memory networks (Sukhbaatar et al. 2015)
QA for Dynamic Memory Networks
- A modular and flexible DL framework for QA
- Capable of tackling wide range of tasks and input formats
- Can even been used for general NLP tasks (i.e. non QA)
(PoS, NER, sentiment, translation, ...)

Input Modules

+ The module produces an ordered list of facts from the input
+ We can increase the number or dimensionality of these facts
+ Input fusion layer (bidirectional GRU) injects positional information and allows interactions between facts
Episodic Memory Module
Composed of three parts with potentially multiple passes:
- Computing attention gates
- Attention mechanism
- Memory update

Soft Attention Mechanism
c = \sum^N_{i=1} g_i f_i
If the gate values were passed through softmax,
the context vector is a weighted summation of the input facts
Given the attention gates, we now want to extract a context vector from the input facts
Issue: summation loses positional and ordering information
Computing Attention Gates
Each fact receives an attention gate value from [0, 1]
The value is produced by analyzing [fact, query, episode memory]
Optionally enforce sparsity by using softmax over attention values

Attention GRU Mechanism
If we modify the GRU, we can inject information from the attention gates.
Attention GRU Mechanism
If we modify the GRU, we can inject information from the attention gates.
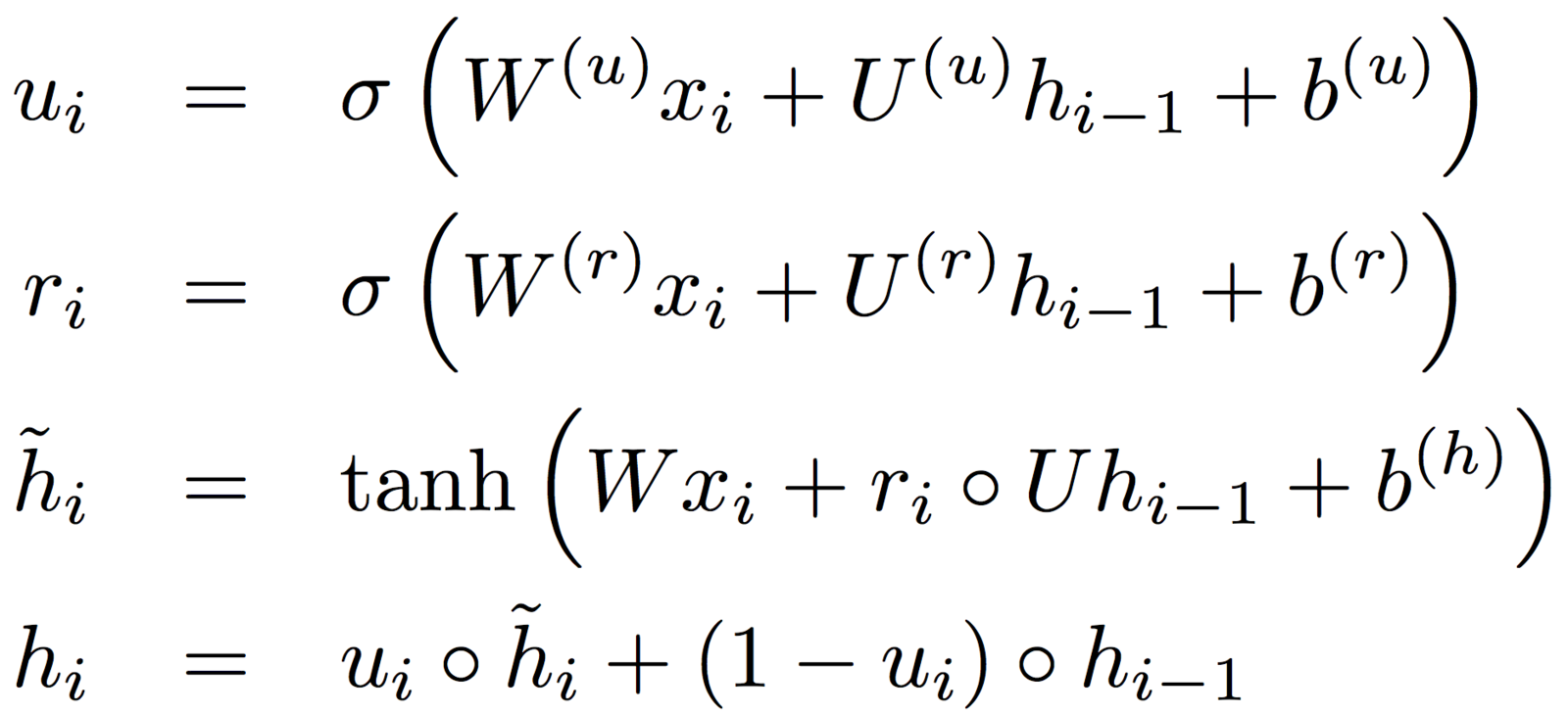
By replacing the update gate u with the activation gate g,
the update gate can make use of the question and memory

Results
Focus on three experiments:
Vision
Text
Attention visualization
DMN Overview

Accuracy: Text QA (bAbI 10k)

Accuracy: Visual Question Answering

Accuracy: Visual Question Answering

Accuracy: Visual Question Answering

Accuracy: Visual Question Answering

Attention and Memory in QA
When we know the question being asked
we can extract only the relevant information
This means that we don't compute or store unnecessary information
More efficient and helps avoid the
information bottleneck
Pointer Networks
What if you're in a foreign country and you're ordering dinner ....?
You see what you want on the menu but
can't pronounce it :'(
Pointer Networks!
(Vinyals et al. 2015)
Seriously ... I know ... This whole field is like following a toddler around and getting excited when they do something non-trivial.
Pointer Networks
What if you're in a foreign country and you're ordering dinner ....?
You see what you want on the menu but
can't pronounce it :'(
Pointer Networks help tackle the
out of vocabulary problem
(most models are limited to a pre-built vocabulary)
Pointer Networks

Convex Hull
Delaunay Triangulation
The challenge: we don't have a "vocabulary" to refer to our points (i.e. P1 = [42, 19.5])
We need to reproduce the exact point
Pointer Networks

Notice: pointing to input!
Pointer Networks


Attention Sum (Kadlec et al. 2016)

Pointer Networks
Pointer networks avoid storing the identity of the word to be produced.
Why is this important?
In many tasks, the name is a placeholder.
In many tasks, the documents are insanely long.
(you'll never have enough working memory!)
Pointer networks avoid storing redundant data :)
Pointer Networks
Big issue:
What if the correct answer isn't in our input..?
... then pointer network can never be correct!
We could use an RNN - it has a vocabulary - but then we lose out on out of vocabulary words that the pointer network would get ...
Pointer Sentinel(Merity et al. 2016)

tldr; We decide whether to use the RNN or the pointer network depending on what the pointer "memory" contains
Pointer Sentinel(Merity et al. 2016)

tldr; We decide whether to use the RNN or the pointer network depending on what the pointer "memory" contains
Pointer Sentinel-LSTM

State of the art results on language modeling
(generating language and/or autocompleting a sentence)

Hierarchical Attentive Memory
(Andrychowicz and Kurach, 2016)

Hierarchical Attentive Memory
Tree structured memory = O(log n) lookup
Hierarchical Attentive Memory
Tree structured memory = O(log n) lookup
HAM can learn to sort in O(n log n)
This is just the beginning..!
Notice almost all these papers are 2014-2016..?
(Deep learning) moves pretty fast.
If you don’t stop and look around once in awhile, you could miss it.

Interested in DL?
I highly recommend Keras

Premise:
A black race car starts up in front of
a crowd of people.
Hypothesis:
A man is driving down a lonely road.
Is it (a) Entailment, (b) Neutral, or (c) Contradiction?
Interested in DL?
I highly recommend Keras

Summary
- Attention and memory can avoid the information bottleneck
- Attention visualization can help in model interpretability
- This is still early days!
Quora - The Frontiers of Memory and Attention in Deep Learning
By smerity



