GraphDB
introduction
Agenda
-
Why GraphDB?
-
What is GraphDB?
-
What make Graph DB
faster than SQL? -
Why GraphDB not popular?
-
Demo
Goal
Become interested in GraphDB
&
Know a bit about it

Why GraphDB?
SQL and NoSQL
SQL: relational model
MySQL
NoSQL: Not Only SQL

MongoDB
MySQL
- Mature solution
- Stable, reliable and powerful
- Atomic transactions support
- Round the clock up time
- JOIN support
- Privilege and password security system
MongoDB
Poor performance scaling
- Mature solution
- Stable, reliable and powerful
- Atomic transactions support
- Round the clock up time
- JOIN support
- Privilege and password security system
- Offers auto-sharing
- High scalability
- Document validation
- Easy environment setup
- Easy schema change
Poor performance scaling
Poor support for transcation
High memory usage
MySQL
- Complex queries
- Transactional Applications
- Stable solution
MongoDB
- Data storage
- Scalability
- MVP
But what if relation is the leading role in your system?
MySQL? MongoDB?
- Planty of data
- Complex queries
Graph DB
What is GraphDB?
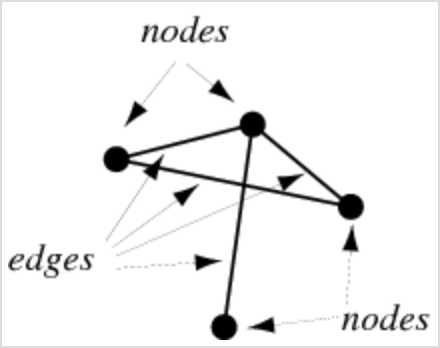
Graph
A graph is a collection of vertices and edges
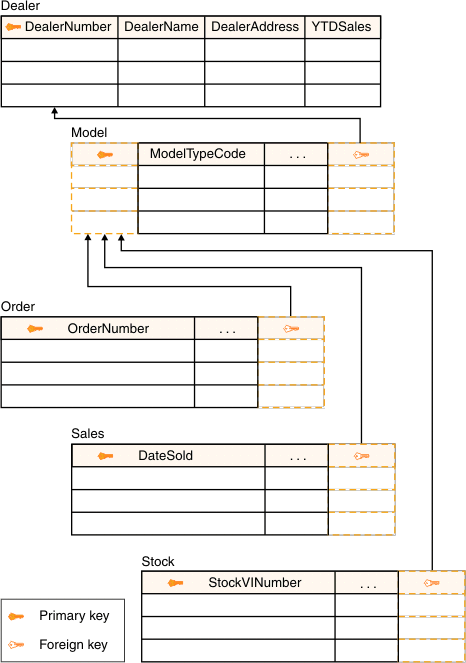
If SQL is
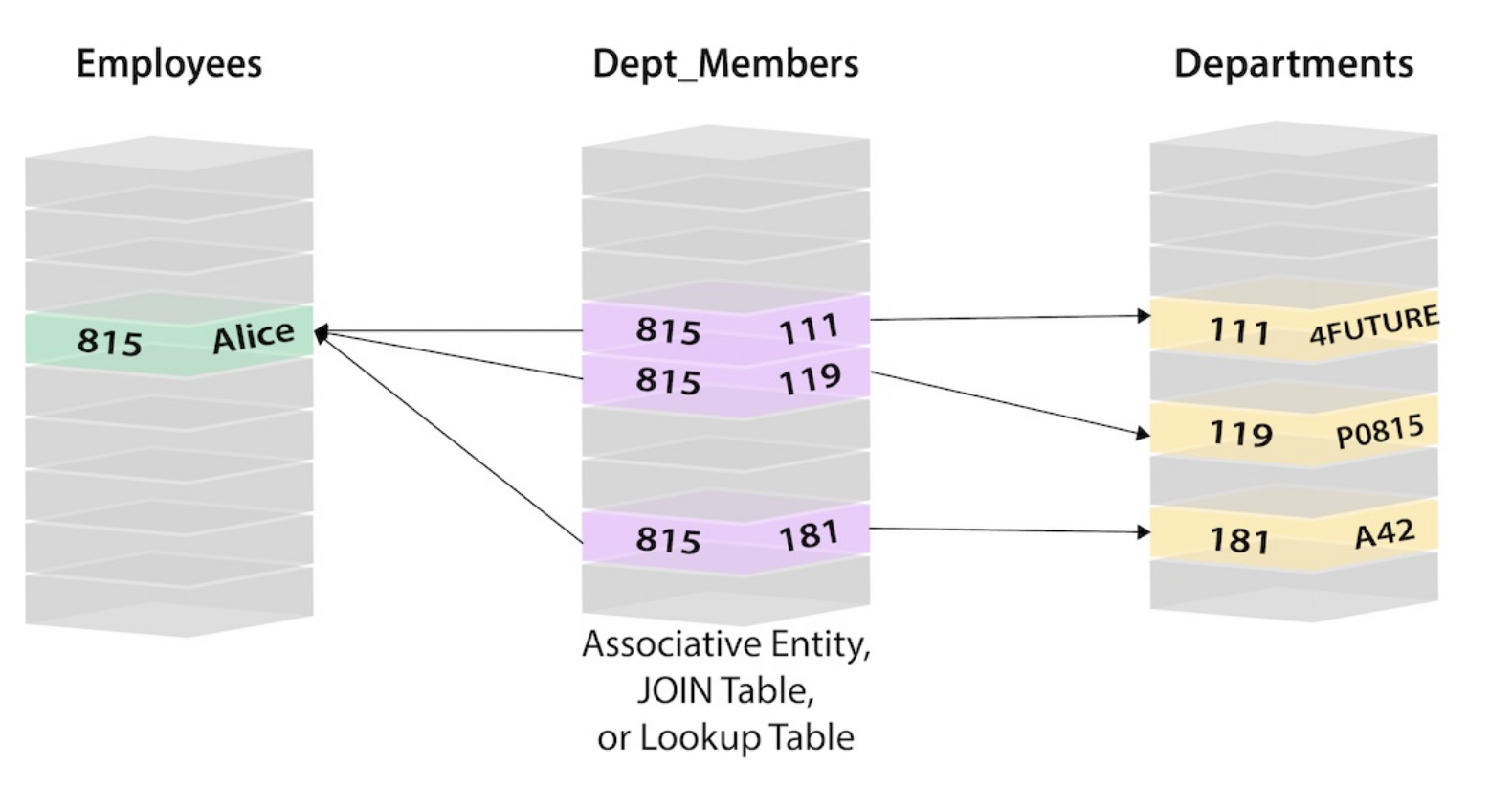
If SQL is
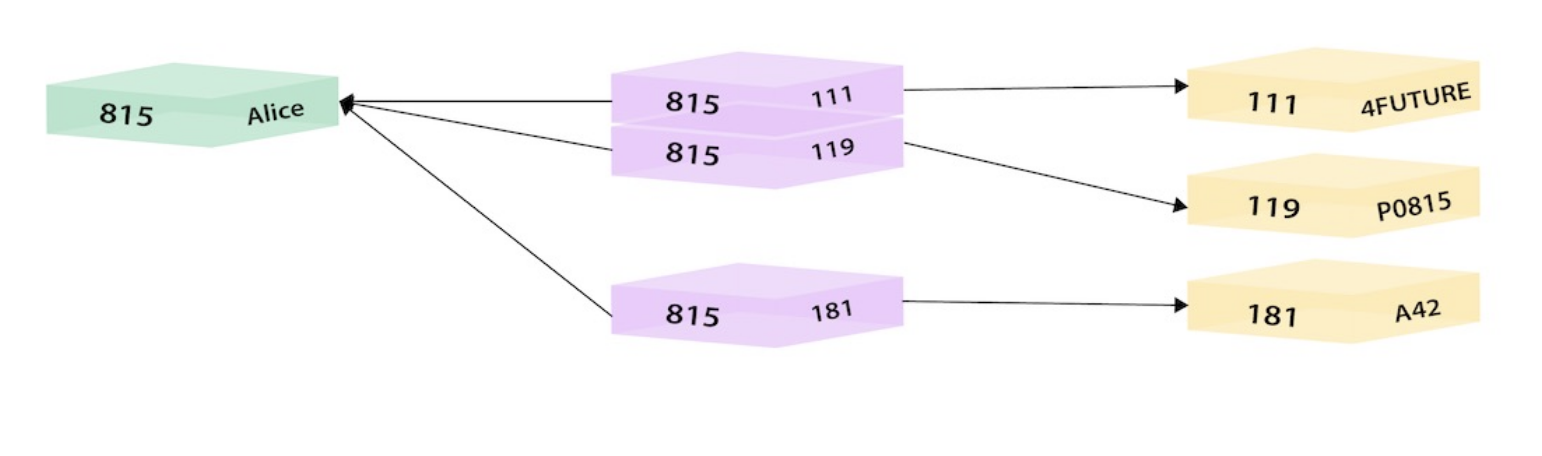
How it transform to GraphDB
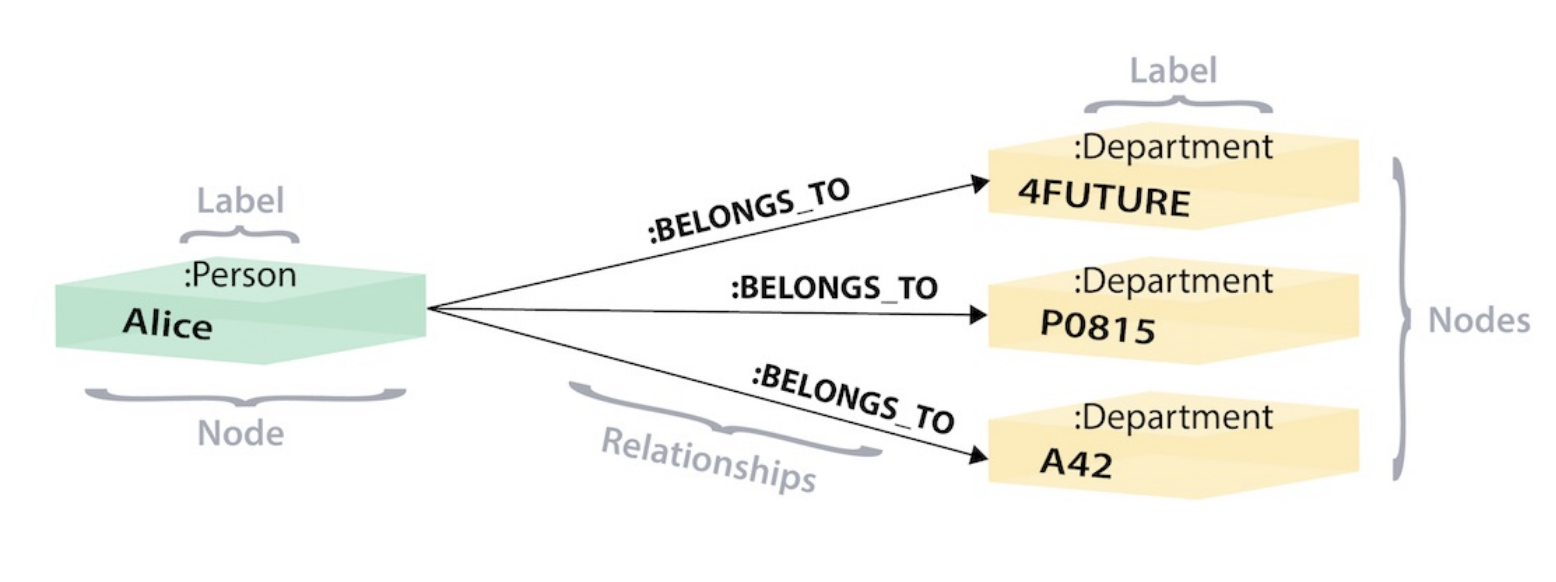
SQL Statement
Graph
Statement
SELECT name FROM Person
LEFT JOIN Person_Department
ON Person.Id = Person_Department.PersonId
LEFT JOIN Department
ON Department.Id = Person_Department.DepartmentId
WHERE Department.name = "IT Department"SQL Statement
Graph
Statement
SELECT name FROM Person
LEFT JOIN Person_Department
ON Person.Id = Person_Department.PersonId
LEFT JOIN Department
ON Department.Id = Person_Department.DepartmentId
WHERE Department.name = "IT Department"MATCH (p:Person)-[:WORKS_AT]->(d:Dept)
WHERE d.name = "IT Department"
RETURN p.nameLet's try a sample
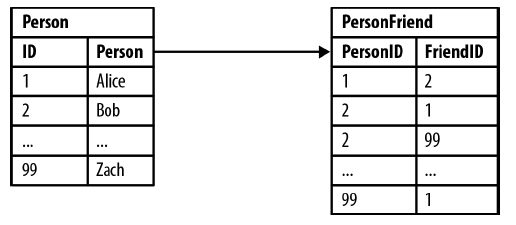
Who are Bob’s friends?
Who is friends with Bob?
Who are friends of my friends?
SELECT p1.Person
FROM Person p1 JOIN PersonFriend
ON PersonFriend.FriendID = p1.ID
JOIN Person p2
ON PersonFriend.PersonID = p2.ID
WHERE p2.Person = ‘Bob’SELECT p1.Person
FROM Person p1 JOIN PersonFriend
ON PersonFriend.FriendID = p1.ID
JOIN Person p2
ON PersonFriend.PersonID = p2.ID
WHERE p2.Person = ‘Bob’SELECT p1.Person AS PERSON, p2.Person AS FRIEND_OF_FRIEND
FROM PersonFriend pf1 JOIN Person p1
ON pf1.PersonID = p1.ID
JOIN PersonFriend pf2
ON pf2.PersonID = pf1.FriendID
JOIN Person p2
ON pf2.FriendID = p2.ID
WHERE p1.Person = ‘Alice’ AND pf2.FriendID <> p1.IDDB Graph
Performance
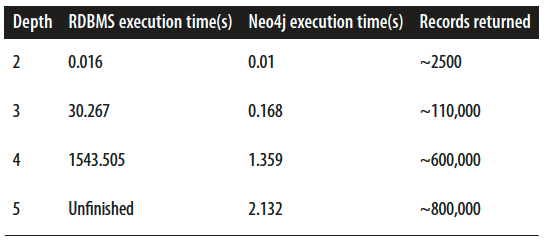
What make Graph DB
faster than SQL?
Two Join Approaches: Nested Loop and Hash Join
Nested Loop
FOR erow IN (select * from employees where X=Y) LOOP
FOR drow IN (select * from departments where erow is matched) LOOP
output values from erow and drow
END LOOP
END LOOPHash Join
FOR small_table_row IN (SELECT * FROM small_table)
LOOP
slot_number := HASH(small_table_row.join_key);
INSERT_HASH_TABLE(slot_number,small_table_row);
END LOOP
FOR large_table_row IN (SELECT * FROM large_table)
LOOP
slot_number := HASH(large_table_row.join_key);
small_table_row = LOOKUP_HASH_TABLE(slot_number,large_table_row.join_key);
IF small_table_row FOUND
THEN
output small_table_row + large_table_row;
END IF;
END LOOP;A simple example
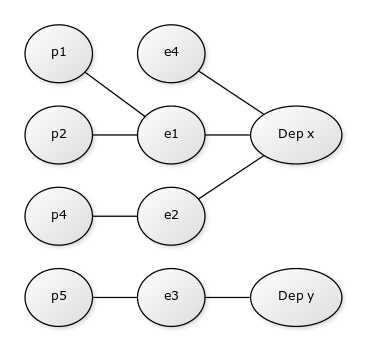
By joining E with D and then E with P, we can calculate for example sum payment for a given department.
Given departments d1 and d2, we want to find all the payments to its employees.
Nested Loop
FOR erow IN (select * from employees where X=Y) LOOP
FOR drow IN (select * from departments where erow is matched) LOOP
output values from erow and drow
END LOOP
END LOOPWorst Case:
2 * |E|*|F|
Hash Join
FOR small_table_row IN (SELECT * FROM small_table)
LOOP
slot_number := HASH(small_table_row.join_key);
INSERT_HASH_TABLE(slot_number,small_table_row);
END LOOP
FOR large_table_row IN (SELECT * FROM large_table)
LOOP
slot_number := HASH(large_table_row.join_key);
small_table_row = LOOKUP_HASH_TABLE(slot_number,large_table_row.join_key);
IF small_table_row FOUND
THEN
output small_table_row + large_table_row;
END IF;
END LOOP;Worst Case:
2 +|E|+2*|E|+|P|
Graph
Worst Case:
k
(k is payments result number)
Time complexity
-
Nested Loop:
-
Hash Join:
-
GraphDB:
O(|E| * |P|)
O(|E|+|P|)
O(k)
Why GraphDB
is not popular?
Why GraphDB
is not popular?
- New solution
- Hard to decentralized
- Join-depth problem
Join Depth Problem
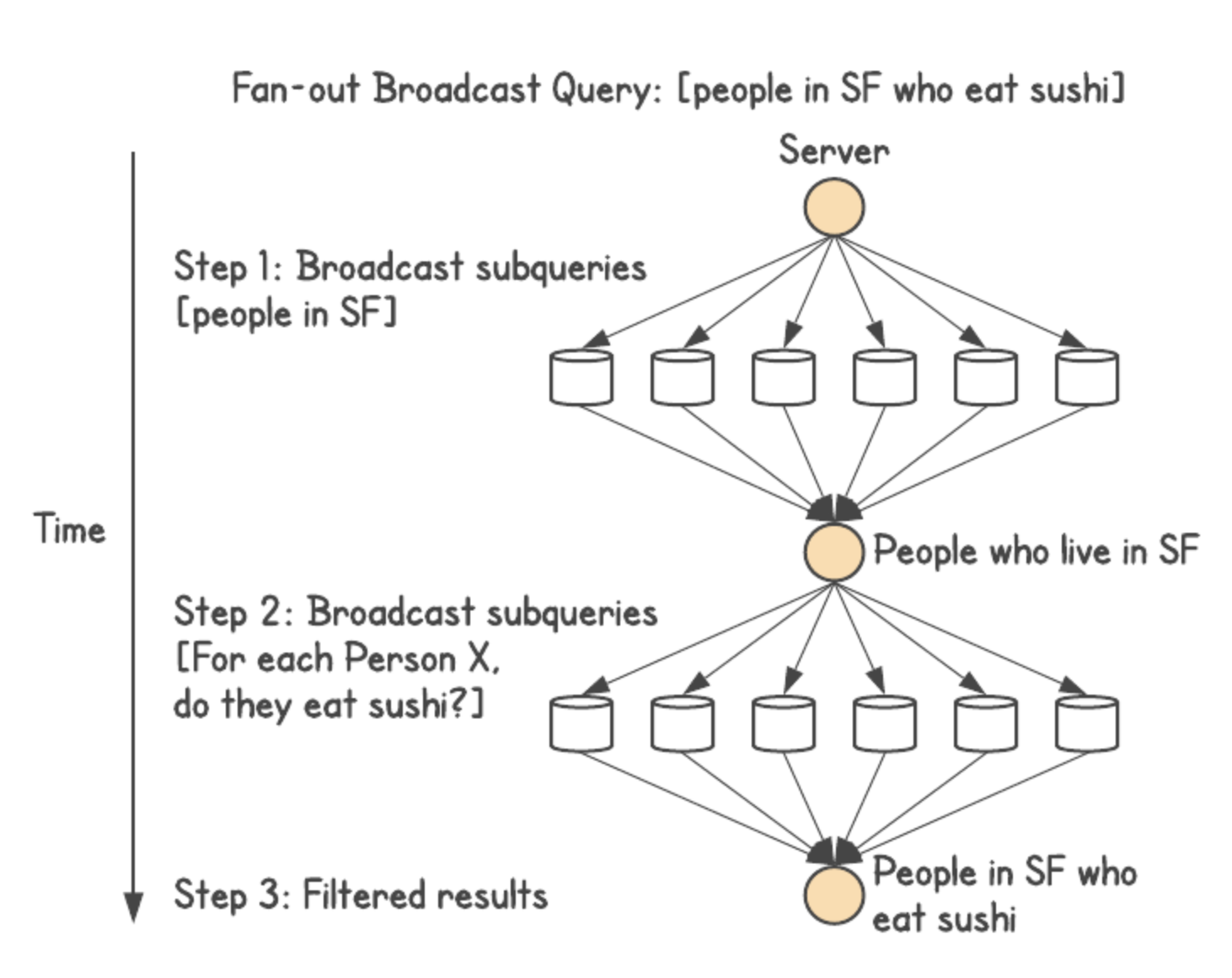
DGraph
- Write by Golang
- Native support GraphQL
- No dependency with 3th party library
type Task {
...
}
type User {
...
}
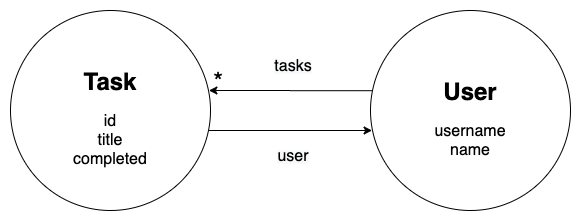
type Task {
id: ID!
title: String!
completed: Boolean!
user: User!
}
type User {
username: String! @id
name: String
tasks: [Task] @hasInverse(field: user)
}
Running
// Run Dgraph
docker run -it -p 8080:8080 dgraph/standalone:master
// Update schema
curl -X POST localhost:8080/admin/schema --data-binary '@schema.graphql'
Mutation Data
mutation {
addUser(input: [
{
username: "amber.yan@graphdb.com",
name: "Amber",
tasks: [
{
title: "Avoid touching your face",
completed: false,
},
{
title: "Stay safe",
completed: false
},
{
title: "Avoid crowd",
completed: true,
},
{
title: "Wash your hands often",
completed: true
}
]
}
]) {
user {
username
name
tasks {
id
title
}
}
}
}
COPY
Q & A
GraphDB
By Stanney Yen



