RankSEG: A Consistent Framework
for Segmentation
Ben Dai
The Chinese University of Hong Kong


Segmentation


Input
output
Input: \(\mathbf{X} \in \mathbb{R}^d\)
Outcome: \(\mathbf{Y} \in \{0,1\}^d\)
Segmentation function:
- \( \pmb{\delta}: \mathbb{R}^d \to \{0,1\}^d\)
- \( \pmb{\delta}(\mathbf{X}) = ( \delta_1(\mathbf{X}), \cdots, \delta_d(\mathbf{X}) )^\intercal \)
Predicted segmentation set:
- \( I(\pmb{\delta}(\mathbf{X})) = \{j: \delta_j(\mathbf{X}) = 1 \}\)
Segmentation
Input
output

Input: \(\mathbf{X} \in \mathbb{R}^d\)
Outcome: \(\mathbf{Y} \in \{0,1\}^d\)
Segmentation function:
- \( \pmb{\delta}: \mathbb{R}^d \to \{0,1\}^d\)
- \( \pmb{\delta}(\mathbf{X}) = ( \delta_1(\mathbf{X}), \cdots, \delta_d(\mathbf{X}) )^\intercal \)
Predicted segmentation set:
- \( I(\pmb{\delta}(\mathbf{X})) = \{j: \delta_j(\mathbf{X}) = 1 \}\)
Segmentation
Input
output
$$ Y_j | \mathbf{X}=\mathbf{x} \sim \text{Bern}\big(p_j(\mathbf{x})\big)$$
$$ p_j(\mathbf{x}) := \mathbb{P}(Y_j = 1 | \mathbf{X} = \mathbf{x})$$
Probabilistic model:
The Dice and IoU metrics are introduced and widely used in practice:


Evaluation
IoU
The Dice and IoU metrics are introduced and widely used in practice:
Evaluation
Goal: learn segmentation function \( \pmb{\delta} \) maximizing Dice / IoU
Dice
- Given training data \( \{\mathbf{x}_i, \mathbf{y}_i\} _{i=1, \cdots, n}\), most existing methods characterize segmentation as a classification problem:

Existing frameworks
- Given training data \( \{\mathbf{x}_i, \mathbf{y}_i\} _{i=1, \cdots, n}\), most existing methods characterize segmentation as a classification problem:
Existing frameworks
Loss functions


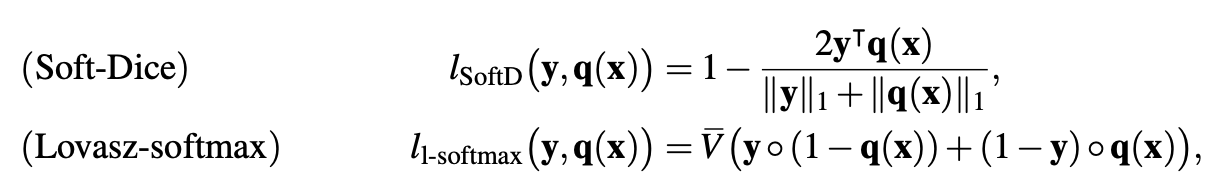
Can we directly maximize the Dice/IoU scores?
Direct Dice/IoU Optimization
Evaluation really matters!
Classification
- Data: \( \mathbf{X} \in \mathbb{R}^d \to Y \in \{0,1\} \)
- Decision function: \( \delta(\mathbf{X}): \mathbb{R}^d \to \{0,1\} \)
- Evaluation:
$$ Acc( \delta) = \mathbb{E}\big( \mathbf{1}( Y = \delta(\mathbf{X}) )\big) $$
- Optimal Rule:
$$ \delta^* = \argmax_{\delta} \ Acc(\delta) \ \ \to \ \delta^*(\mathbf{x}) = \mathbf{1}( p(\mathbf{x}) \geq 0.5 ) $$
Can we directly maximize the Dice/IoU score?
Classification
- Data: \( \mathbf{X} \in \mathbb{R}^d \to Y \in \{0,1\} \)
- Decision function: \( \delta(\mathbf{X}): \mathbb{R}^d \to \{0,1\} \)
- Evaluation:
$$ Acc( \delta) = \mathbb{E}\big( \mathbf{1}( Y = \delta(\mathbf{X}) )\big) $$
- Optimal Rule:
$$ \delta^* = \argmax_{\delta} \ F1(\delta) \ \ \to \ \delta^*(\mathbf{x}) = \mathbf{1}( p(\mathbf{x}) \geq p_0 ) $$
$$F1(\delta)$$
where \(p_0 = F1^* / 2 \leq 0.5 \), it is also truncation, but not at 0.5!
Direct Dice/IoU Optimization
Evaluation really matters!
$$ \pmb{\delta}^* = \text{argmax}_{\pmb{\delta}} \ \text{Dice}_\gamma ( \pmb{\delta})$$
Optimal segmentation rule
Direct Dice/IoU Optimization
What form would the Bayes segmentation rule take?
Bayes segmentation rule
Theorem 1 (Dai and Li, 2023). A segmentation rule \(\pmb{\delta}^*\) is a global maximizer of \(\text{Dice}_\gamma(\pmb{\delta})\) if and only if it satisfies that

\( \tau^*(\mathbf{x}) \) is called optimal segmentation volume, defined as

$$ \tau^* = \arg\max_{\tau \in \{0,1,\cdots,d\}} \Big( \sum_{j \in J_\tau(\mathbf{x})} \mathbb{E} \big( \frac{2p_j(\mathbf{x})}{\tau + \Gamma_{-j}(\mathbf{x}) + \gamma + 1 } \big) + \gamma \mathbb{E} \big( \frac{1}{\tau + \Gamma + \gamma} \big) \Big) $$
The Dice measure is separable w.r.t. \(j\)

Bayes segmentation rule


Bayes segmentation rule

Bayes segmentation rule
Bayes segmentation rule
Theorem 1 (Dai and Li, 2023). A segmentation rule \(\pmb{\delta}^*\) is a global maximizer of \(\text{Dice}_\gamma(\pmb{\delta})\) if and only if it satisfies that
\( \tau^*(\mathbf{x}) \) is called optimal segmentation volume, defined as
$$ \tau^* = \arg\max_{\tau \in \{0,1,\cdots,d\}} \Big( \sum_{j \in J_\tau(\mathbf{x})} \mathbb{E} \big( \frac{2p_j(\mathbf{x})}{\tau + \Gamma_{-j}(\mathbf{x}) + \gamma + 1 } \big) + \gamma \mathbb{E} \big( \frac{1}{\tau + \Gamma + \gamma} \big) \Big) $$
Theorem 1 (Dai and Li, 2023). A segmentation rule \(\pmb{\delta}^*\) is a global maximizer of \(\text{Dice}_\gamma(\pmb{\delta})\) if and only if it satisfies that
\( \tau^*(\mathbf{x}) \) is called optimal segmentation volume, defined as
Obs: both the Bayes segmentation rule \(\pmb{\delta}^*(\mathbf{x})\) and the optimal volume function \(\tau^*(\mathbf{x})\) are achievable when the conditional probability \(\mathbf{p}(\mathbf{x}) = ( p_1(\mathbf{x}), \cdots, p_d(\mathbf{x}) )^\intercal\) is well-estimated
Bayes segmentation rule
$$ \tau^* = \arg\max_{\tau \in \{0,1,\cdots,d\}} \Big( \sum_{j \in J_\tau(\mathbf{x})} \mathbb{E} \big( \frac{2p_j(\mathbf{x})}{\tau + \Gamma_{-j}(\mathbf{x}) + \gamma + 1 } \big) + \gamma \mathbb{E} \big( \frac{1}{\tau + \Gamma + \gamma} \big) \Big) $$
Theorem 1 (Dai and Li, 2023). A segmentation rule \(\pmb{\delta}^*\) is a global maximizer of \(\text{Dice}_\gamma(\pmb{\delta})\) if and only if it satisfies that
\( \tau^*(\mathbf{x}) \) is called optimal segmentation volume, defined as
where \(J_\tau(\mathbf{x})\) is the index set of the \(\tau\)-largest probabilities, \(\Gamma(\mathbf{x}) = \sum_{j=1}^d {B}_{j}(\mathbf{x})\), and \( {\Gamma}_{- j}(\mathbf{x}) = \sum_{j' \neq j} {B}_{j'}(\mathbf{x})\) are Poisson-binomial random variables.
RankDice inspired by Thm 1 (plug-in rule)
-
Ranking the conditional probability \(p_j(\mathbf{x})\)
Plug-in rule
Theorem 1 (Dai and Li, 2023+). A segmentation rule \(\pmb{\delta}^*\) is a global maximizer of \(\text{Dice}_\gamma(\pmb{\delta})\) if and only if it satisfies that
\( \tau^*(\mathbf{x}) \) is called optimal segmentation volume, defined as
RankDice inspired by Thm 1
-
Ranking the conditional probability \(p_j(\mathbf{x})\)
-
searching for the optimal volume of the segmented features \(\tau(\mathbf{x})\)
Plug-in rule
RankSEG
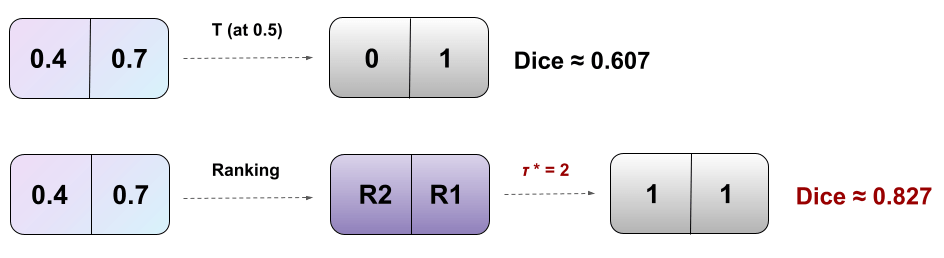
RankSEG


RankSEG
O( d log(d) )
RankSEG
O( d^2 )
RankSEG
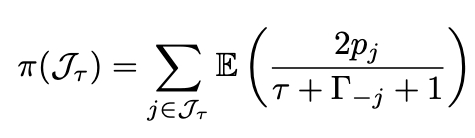
$$ \tau^* = \arg\max_{\tau \in \{0,1,\cdots,d\}} \Big( \sum_{j \in J_\tau(\mathbf{x})} \mathbb{E} \big( \frac{2p_j(\mathbf{x})}{\tau + \Gamma_{-j}(\mathbf{x}) + \gamma + 1 } \big) + \gamma \mathbb{E} \big( \frac{1}{\tau + \Gamma + \gamma} \big) \Big) $$
Blind approximation (BA; Dai and Li 2023). In high-D segmentation, the difference in distributions between \(\Gamma(\mathbf{x})\) and \(\Gamma_{-j}(\mathbf{x})\) is negligible.
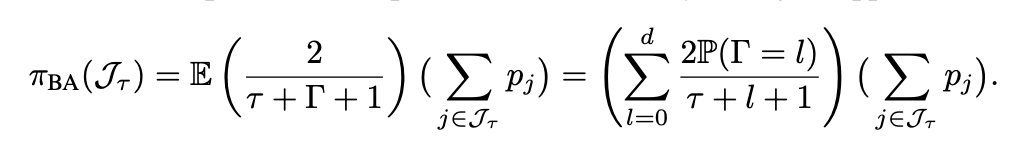
$$ \approx $$
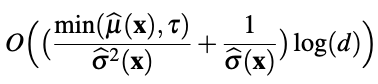
$$\to 0 (d \to \infty)$$
Lemma 5 in Dai and Li (2023)
RankSEG: BA Algo
Blind approximation (BA; Dai and Li 2023). In high-D segmentation, the difference in distributions between \(\Gamma(\mathbf{x})\) and \(\Gamma_{-j}(\mathbf{x})\) is negligible.
$$ \approx $$
$$\to 0 (d \to \infty)$$
Lemma 5 in Dai and Li (2023)
$$ \tau^* = \arg\max_{\tau \in \{0,1,\cdots,d\}} \Big( \sum_{j \in J_\tau(\mathbf{x})} \mathbb{E} \big( \frac{2p_j(\mathbf{x})}{\tau + \Gamma_{-j}(\mathbf{x}) + \gamma + 1 } \big) + \gamma \mathbb{E} \big( \frac{1}{\tau + \Gamma + \gamma} \big) \Big) $$
RankSEG: BA Algo


GPU via CUDA
O( d log(d) ) 😄
(approx 100 times slower than T (at 0.5) 🥲)
RankSEG: BA Algo
RankSEG: RMA
Chao, M. T., & Strawderman, W. E. (1972). JASA


Wooff, David A. (1985) JRSS-b
RankSEG: RMA

Theorem 2 (Wang and Dai, 2025). (Reciprocal moment approximation to RankSEG). Let \(\Gamma\) be a Poisson-binomial r.v., then for any \(\tau \geq 1\),
$$ (\mathbb{E}\Gamma + \tau)^{-1} \leq \mathbb{E}(\Gamma + \tau)^{-1} \leq \left(\frac{d+1}{d}\mathbb{E}\Gamma + \tau - 1\right)^{-1}. $$

Zixun Wang (CUHK)
$$ \approx $$
$$ \approx $$
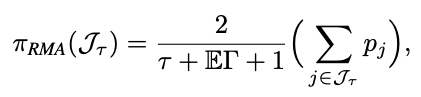
$$\to 0 (d \to \infty)$$
Theorem 2 in Wang and Dai (2025)
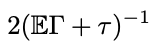
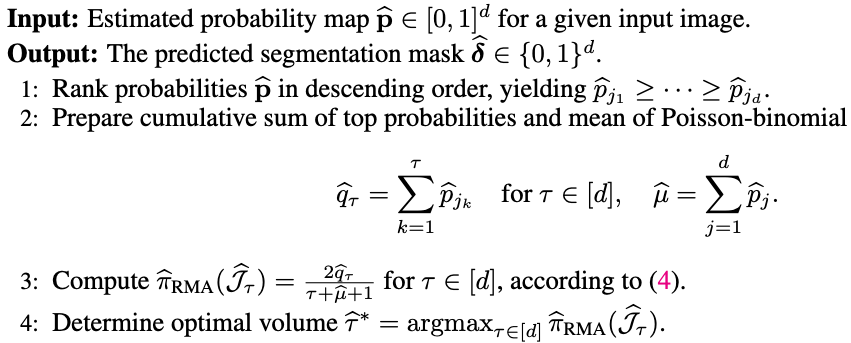
RankSEG: RMA
$$ \approx $$
$$ \approx $$
$$\to 0 (d \to \infty)$$
Theorem 2 in Wang and Dai (2025)
RankSEG: RMA
- Three segmentation benchmark: VOC, CityScapes, ADE20K
RankSEG: Experiments

Source: Visual Object Classes Challenge 2012 (VOC2012)
- Three segmentation benchmark: VOC, CityScapes, ADE20K
RankSEG: Experiments
Source: Visual Object Classes Challenge 2012 (VOC2012)

Source: The Cityscapes Dataset: Semantic Understanding of Urban Street Scenes
- Three segmentation benchmark: VOC, CityScapes, ADE20K
RankSEG: Experiments
Source: Visual Object Classes Challenge 2012 (VOC2012)
Source: The Cityscapes Dataset: Semantic Understanding of Urban Street Scenes
Zhou, Bolei, et al. "Semantic understanding of scenes through the ade20k dataset." IJCV
- Three segmentation benchmark: VOC, CityScapes, ADE20K

RankSEG: Experiments
- Three segmentation benchmarks: VOC, CityScapes, ADE20
- Commonly used models: DeepLab-V3+, PSPNet, SegFormer
- The proposed framework VS. the existing frameworks
- Based on the SAME trained neural networks
- Open-Source python module and codes for replication
- All trained neural networks available for download
RankSEG: Experiments
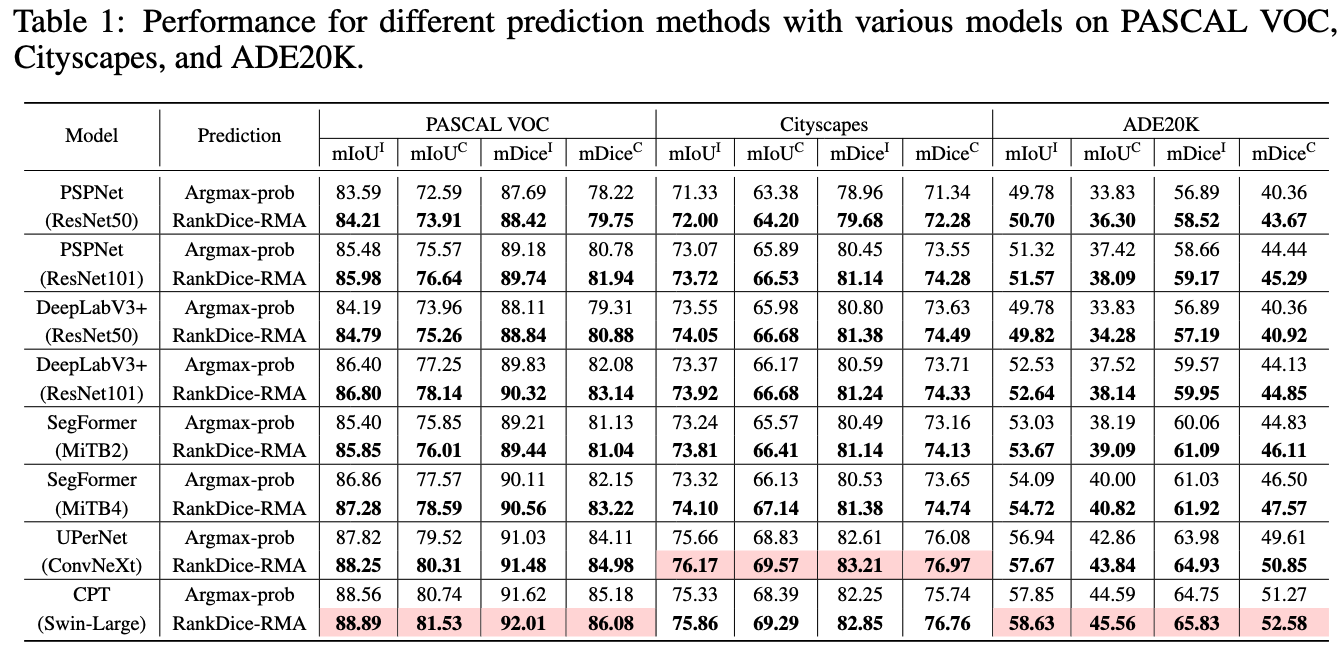
RankSEG: Experiments
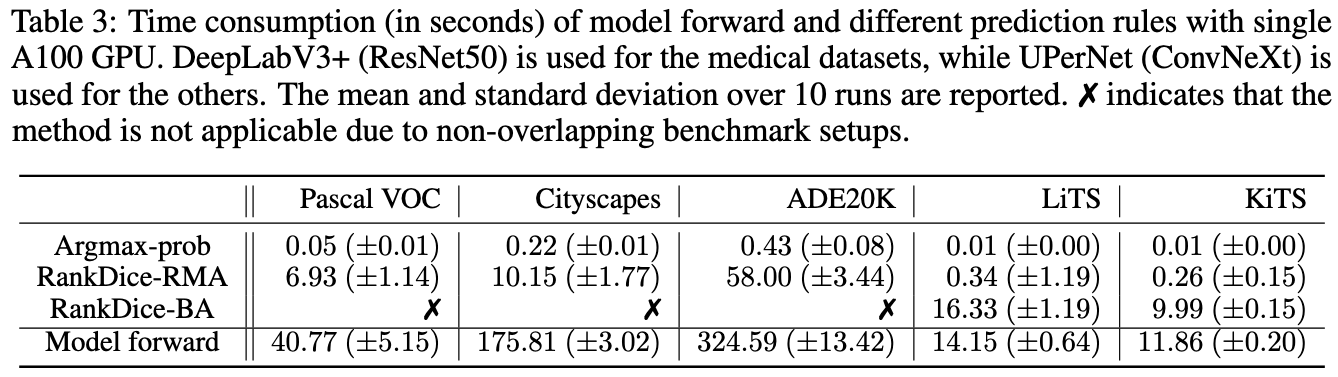
RankSEG: Experiments
RankSEG: Experiments


The optimal threshold is NOT 0.5, and it is adaptive over different images/inputs
RankSEG: Experiments
The optimal threshold is NOT fixed, and it is adaptive over different images/inputs


RankSEG: Experiments

RankSEG: Experiments
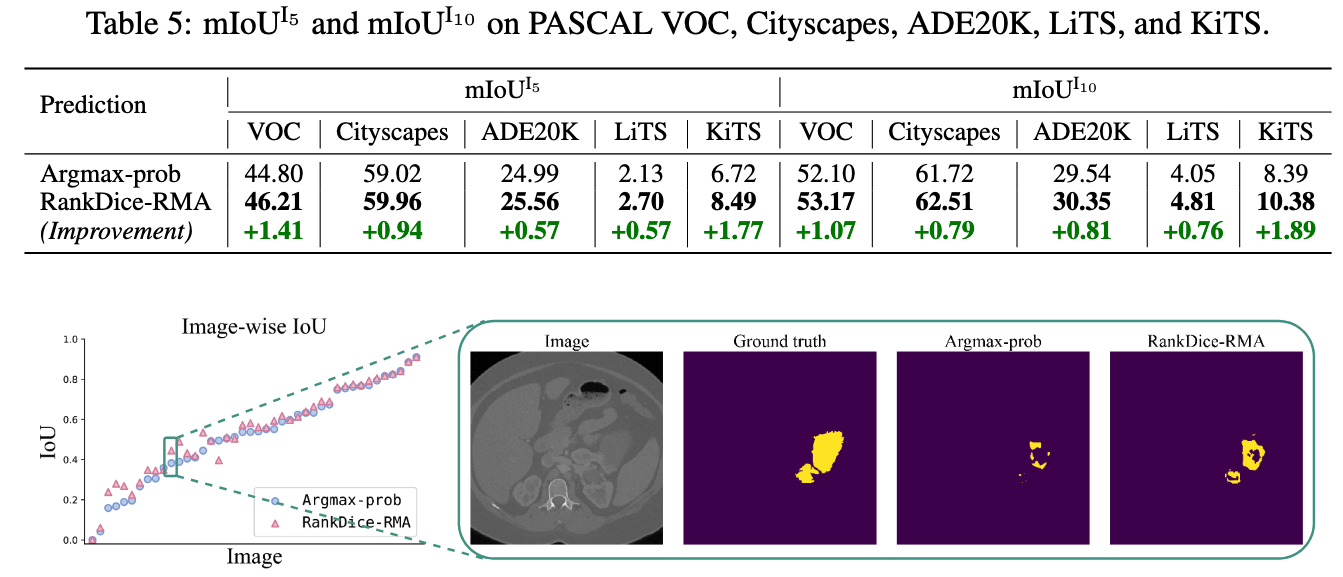
RankSEG: Experiments
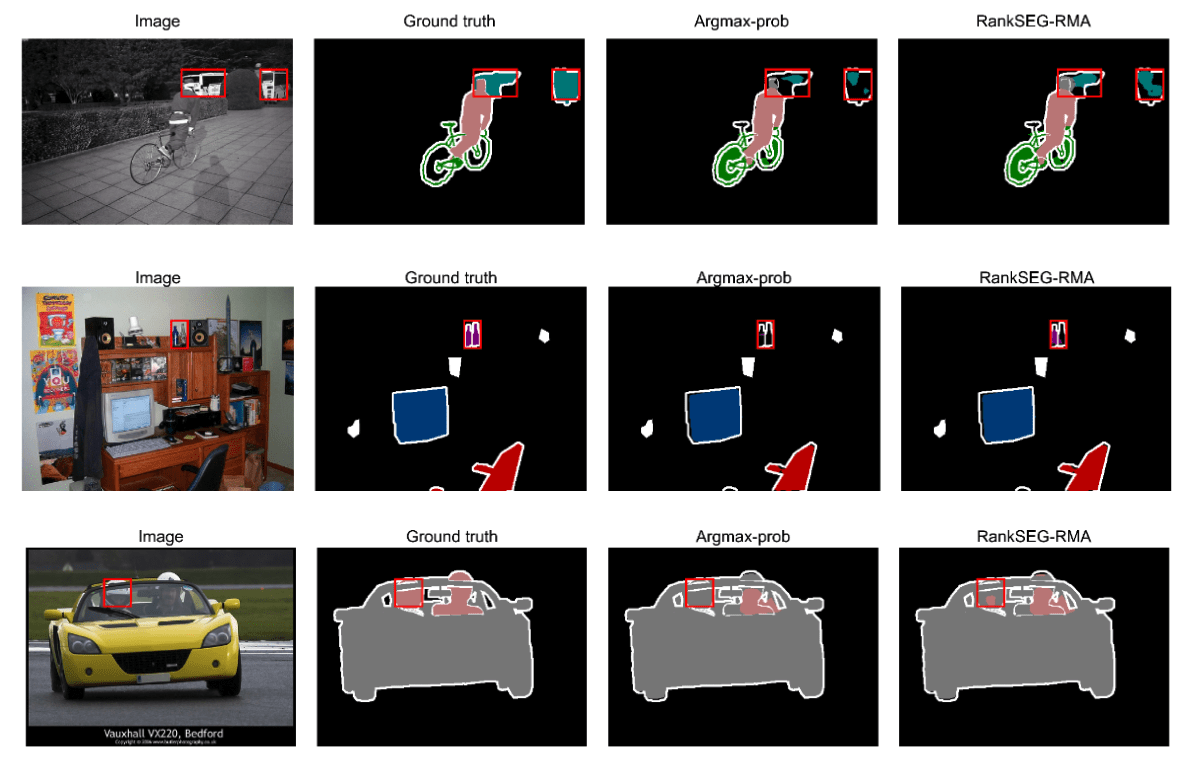
More experimental results in Dai and Li (2023) and Wang and Dai (2025)
RankSEG: Experiments

Fisher consistency or Classification-Calibration
(Lin, 2004, Zhang, 2004, Bartlett et al 2006)
Classification
Segmentation
RankSEG: Theory

RankSEG: Theory

RankSEG: Theory

RankSEG: Theory

RankSEG: Theory
- mRankDice: extension and challenge
- RankIoU
- Simulation
- Probability calibration
- ....
More results
-
To our best knowledge, the proposed ranking-based segmentation framework RankSEG, is a consistent segmentation framework with respect to the Dice/IoU metric.
-
BA and RMA algorithms with GPU parallel execution and are developed to implement the proposed framework in large-scale and high-dimensional segmentation.
-
We establish a theoretical foundation of segmentation with respect to the Dice metric, such as the Bayes rule, Dice-calibration, and a convergence rate of the excess risk for the proposed RankDice framework, and indicate inconsistent results for the existing methods.
-
Our experiments suggest that the improvement of RankDice over the existing frameworks is significant.
Contribution

Thank you!

If you like RankSEG please star 🌟 our Github repository, thank you for your support!

- Dai, B., & Li, C. (2023). RankSEG: A Consistent Ranking-based Framework for Segmentation. Journal of Machine Learning Research.
- Wang, Z., & Dai, B. (2025). RankSEG-RMA: An Efficient Segmentation Algorithm via Reciprocal Moment Approximation. NeurIPS.
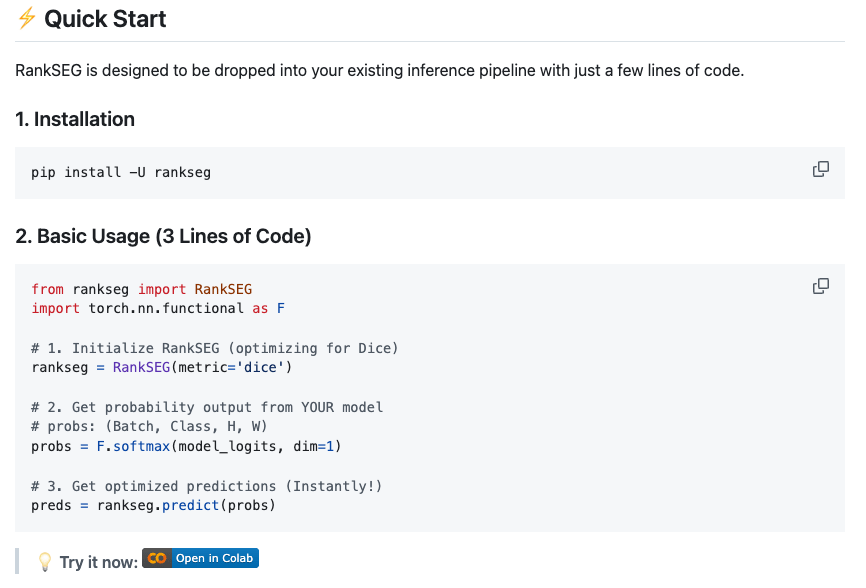
rankseg-pure
By statmlben
rankseg-pure
Boost segmentation model mIoU/Dice instantly WITHOUT retraining. A plug-and-play, training-free optimization module. Published in NeurIPS & JMLR. Compatible with SAM, DeepLab, SegFormer, and more. 🧩




