Interpretable by Design:
Learning Predictors by Composing Interpretable Queries
Aditya Chattopadhyay, Stewart Slocum, Benjamin Haeffele, Rene Vidal, and Donald Geman

Most Tools for Deep Network Interpretability are Broken
There is broad consensus on the fact that current interpretability tools are hard to draw accurate conclusions from.
There are countless new papers in the area but most have little value, in large part because there isn't a clear objective defining what the field should aim for.
This precludes building evaluation criteria like benchmarks, which have been key to progress in the field of ML.
Objectives for Interpretability Tools
We put forward 4 objectives for interpretability tools
- Trustworthy - Implied conclusions from explanations should be accurate (i.e. if a feature is highlighted as important to a prediction, then changing it should significantly impact the prediction)
- Intelligible - Target audience should be able to understand the basic units/structure of the explanation.
- Concise - Explanations should be short.
- Performant - Interpretability tools should not result in significantly reduced performance vs a black-box model.
Trustworthiness
The most popular interpretability methods, which are based on local measures of feature importance (e.g. the gradient for saliency maps) are notoriously misleading.
We propose a definition of trustworthiness in terms of approximate statistical sufficiency.
If a method satisfies this criteria, it then generates causal explanations of model predictions.
Intelligible
Interpretability tools should also generate explanations that are understandable by human user.
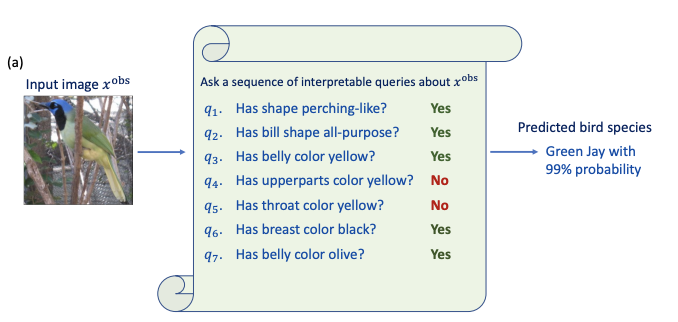
It is not clear that pixel and feature attribution maps are the most interpretable. Rather, we prefer to think of explanations in terms of high-level concepts.
We designed our explanations to be sets of queries about the input.
Concise
Short explanations are much easier to understand than long, complicated ones.
Even classically interpretable models like linear models or decision trees become uninterpretable when they contain large numbers of coefficients or branches.
Putting it All Together
We formalize the first three objectives into a mathematical formulation described by approximate Semantic Entropy:
H^\epsilon_Q(X; Y) = \min_{\pi} \mathbb{E}_x[|expl^\pi_Q (X)|] \\
\text{s.t. } d(p(Y|x), p(Y|expl^\pi_Q (x))) \leq \epsilon \: \forall x
The Semantic Entropy of a dataset is the average length of the minimal sufficient explanation policy \(\pi\).
The resulting explanations resemble a game of 20 questions, where queries belong to \(Q\) and the goal is to reach a high-level of confidence in the correct answer \(y\).
Implementation
Finding the minimal sufficient explanation for a point is an NP-hard problem.
We use an approximate greedy strategy called Information Pursuit.
This requires a mutual information calculation, which we implement with a VAE.
deck
By Stewy Slocum



