Lecture 1:
Introduction to Reinforcement Learning
Artyom Sorokin | 05 Feb
What is Reinforcement Learning?
Lets start from...
Supervised Learning Problem
Supervised Learning case:
Given Dataset
Learn a function that will predict y from X:
e. g. find parameters theta that will minimize: where is a loss function
D :=\{ (X_i, y_i)\}
L(f_{\theta}(X_i), y_i)
f_{\theta}: X \rightarrow y
L
Standart Assumptions:
- Samples in Dataset are I.I.D
- We have ground truth labels
y

No ground truth answers
You don't have answers at all


No ground truth answers
Your answers are not good enough

Choice matters
Assume that we have expert trajectories, i.e. sufficiently good answers:

- Treat trajectories as a dataset: \(D = \{(x_1, a_1), .. (x_N, a_N)\}\)
- Train with Supervised Learning
Will this work?
Choice matters
Assume that we have expert trajectories, i.e. sufficiently good answers:


Yes, but only if for any possible behavior there is a close example from the data
- Treat trajectories as a dataset: \(D = \{(x_1, a_1), .. (x_N, a_N)\}\)
- Train with Supervised Learning
Will this work?
Not always possible!
Choice matters
New Plan (DAGGER algorithm):
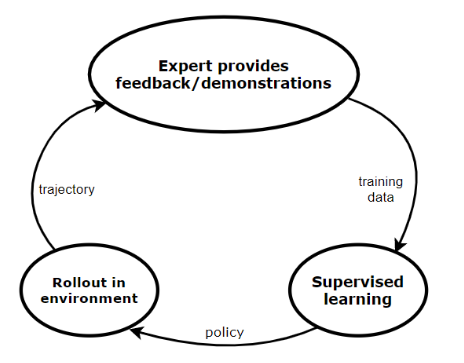
- Train a model from human trajectories : \(D_0 = \{(x_1, a_1), .. (x_N, a_N)\}\)
- Run the model to get new tajectories: \(D' = \{(x_1, ?), .. (x_N, ?)\}\)
- Ask humans to label \(D'\) with actions \(a_t\)
- Aggregate:
- Repeat
D_1 \leftarrow D_{0} \cup D'
Choice matters
But this is really hard to do: 3. Ask humans to label \(D'\) with actions \(a_t\)

Huge datasets and huge models
Do we still need Reinforcement Learning?

Impressive results in image and text generation with SL!

Huge datasets and huge models
Impressive because no person had thought of it!
Impressive because it looks like something a person might do!
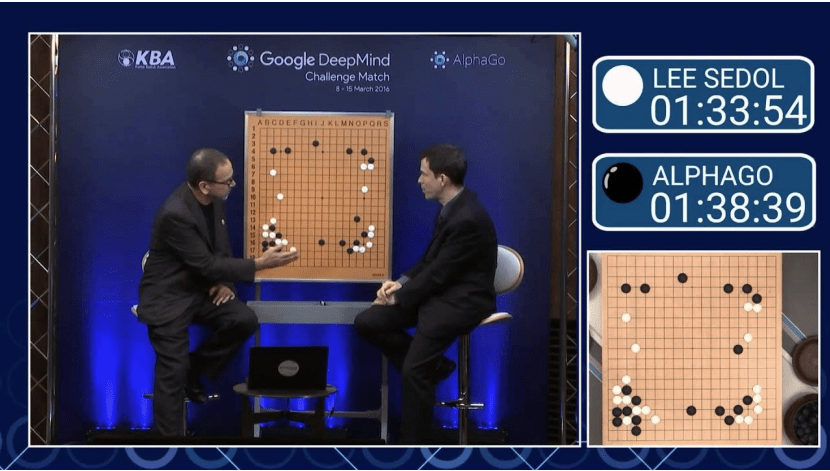
SL results
RL results
Reinforcement learning
If You know what you want, but don't know how to do it... USE REWARDS!

WIN: +1
LOSE: -1
Assumptions:
- It's easy to compute reward
- You can express your goals with rewards!
Reinforcement Learning Problem
You have Agent and Environment that interact with each other:
- Agent's actions change the state environment
- After each action agent receives new state and reward
Interaction with environment is typically divided into episodes.
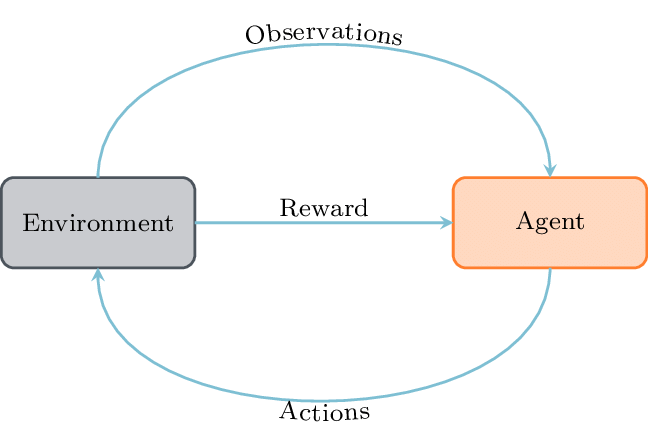
Reinforcement Learning Problem
Agent has a policy:
Agent learns its policy via Trial and Error!
The goal is to find a policy that maximizes total expected reward:
\text{maximize}_{\pi} \mathbb{E}_{\pi} [ \sum^{T}_{t=0} r_t ]
\pi (\text{action} | \text{observations from env})
\textcolor{red}{\mathbb{E}_{\pi}}
Why we need ?
A non-deterministic policy or environment lead to a distribution of total rewards!
Why not use or ?
\textcolor{red}{\mathbb{max}_{\pi}} [ \sum^{T}_{t=0} r_t ]
\textcolor{red}{\mathbb{min}_{\pi}} [ \sum^{T}_{t=0} r_t ]
Reinforcement Learning Problem
?
?
Environment and Observation
What should an agent observe?
:format(webp)/cdn.vox-cdn.com/uploads/chorus_image/image/55862505/Roomba7902.0.jpg)

- Wheel speed
- Acceleration
- LiDAR
- Battery
- Map of the apartment
- Location
Is this enough?
Does agent need past observations?
Markovian Propery
Task: Open the red door with the key
Details: Agent starts at random location
Actions:
- move up/left/right/down
- pick up an object
- apply an object to the door (when near the door)
Markovian Propery
Which observations are enough to learn the optimal policy?
- Agent's coordinates, and previous action
- Full image of the maze
- Agent's coordinates and does it has key
For 2 and 3 agent doesn't need to remember it's history:
Markovian property: "The future is independent of the past given the present."
P(o_{t+1}, r_{t+1}| o_t, a_t) = P(o_{t+1}, r_{t+1}| o_t, a_t, ..., o_1, a_1, o_0, a_0)
Markov Decision Process
MDP is a 5-tuple \(<S,A,R,T, \gamma >\):
- \(S\) is a set of states
- \(A\) is a set of actions
- \(R: S \times A \to \mathbb{R}\) is a reward function
- \(T: S \times A \times S \to [0,1]\) is a transition function \(T(s,a,s\prime) = P(S_{t+1}=s\prime|S_t=s, A_t=a)\)
- \(\gamma \in [0, 1] \) is a discount factor
Given Agent's policy \(\pi\), RL objective become:
\mathbb{E}_{\pi} [ \sum^{T}_{t=0} \textcolor{red}{\gamma^{t}} r_t ]
Discount factor \(\gamma\) determines how much we should care about the future!
Multi-Armed Bandits
MDP for Contextual Multi-Armed Bandits:
- Rewards are imediate (follows from 1.)
\small
\mathbb{P} ( S^{\prime}| S, A ) = \mathbb{P}(S)
MDP for Multi-Armed Bandits:
- Only one state
- Rewards are imediate (follows from 1.)
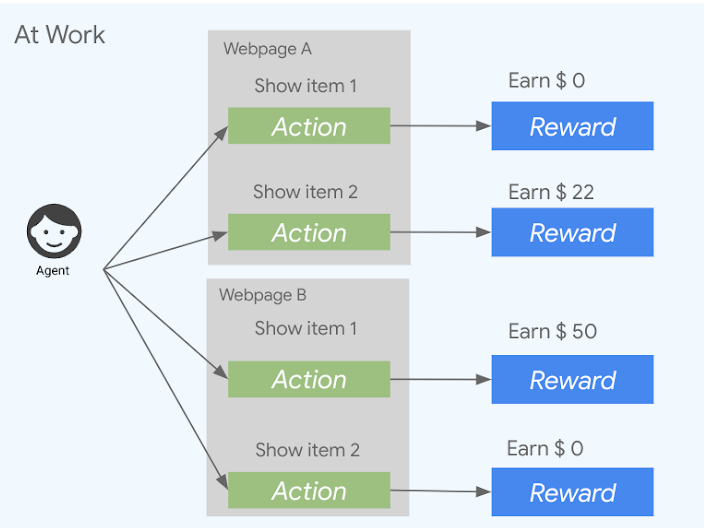

ChatGPT finetuned in this setting with PPO algorithm ( explained in lectures 6 & 7)
Reinforcement Learning: SL as RL
You can formulate SL problem as RL problem!
Given Dataset:
We consider X_i as states, and y_i as correct actions!
Then the reward function will be \(R(X_i, a_i) = 1\). if \(a_i = y_i\) else 0.
D :=\{ (X_i, y_i)\}
Because Reinforcement learning is a harder problem!
Why don't we use Reinforcement learning every where?


Exploration-Exploitation Dilemma
- Was that action optimal?
- Should you explore other actions?
- When you need to stop exploration?
Reward contains less information than a correct answer!
fox
bread
truck
dog
0.
0.
0.
1.
We have ground truth labels
fox
bread
truck
dog
-3
We have rewards
?
?
?
?
Reward Specification Problem
Reward is a proxy for you goal, but they are not the same!
Goal: Train a bot to win the game!
Rewards:
- +100 for the first place
- +5 for additional targets along the course
Credit Assignment Problem
Your data is not i.i.d. Previous actions affect future states and rewards.
Credit Assignment Problem:
How to determine which actions are responsible for the outcome?
- Agent makes a move at step 8
- At step 50 agent looses: R = -1
- Was it a good move?
Distributional shift: In case of Deep RL
The training dataset is changing with the policy.
This can lead to a catastrophic forgetting problem:
Agent unlearns it's policy in some parts of the State Space


Conclusion
- Reinforcement Learning uses less feedback information than Supervised Learning
- RL allows us to approach a wider set of tasks
- RL is a harder problem with it's own additional challenges
Course Team:
-
Artem Sorokin
- Research Scientist at AIRI
- PhD
- publications: NeurIPS'22, ICLR'20
- Category Prize at NeurIPS AAIO Challange'19
- 2nd place at DeepHack.RL'17
-
Pavel Temirchev
- Software Developer at Yandex
- admin at https://t.me/theoreticalrl
-
Dmitry Sorokin
- Research Scientist at AIRI
- PhD
- publications: NeurIPS'20, CoRL'21
- 1st place at NeurIPS NetHack Challange'21
As a team, we have conducted several RL courses:
- Lomonosov MSU course at CMC department
- YSDA course: "Advanced topics in RL"
- HSE course: "Reinforcement Learing"
Course Schedule:
RL Basis:
- Introduction in RL
- Dynamic Programming
- Tabular RL
Deep Reinforcement Learning:
- Deep Q Networks
- Policy Gradient
- Advanced Policy Gradient
- Continual Control
- Distributional RL
Advanced Topics:
- Model Based RL
- Memory in RL
- Exploration-Exploitation trade-off
- Transfer and Meta RL


Code this
Code this
Learn about this
Final Grades
Оценка выставляется по десятибальной шкале.
Планируется 6 заданий. Задания приносят 2 или 1 балла в зависимости от сложности.
Если задание сдается в течение двух недель после дедлайна, то ценность задания составляет 80% изначальной, если позже то только 60%.
В конце курса будет необязательный тест общей стоимостью в 2 балла.
Детали:
- Все домашки во время: отлично / 10 баллов
- Все домашки в последний момент + идеальный тест: отлично / 8 баллов
- Только тест: неуд / 2 балла
Resources
Courses:
- Practical Reinforcement Learning: https://github.com/yandexdataschool/Practical_RL
- CS 285 at UC Berkeley: http://rail.eecs.berkeley.edu/deeprlcourse/
- David Silver's Course on RL: https://www.davidsilver.uk/teaching/
Books:
- Sutton and Barto, Reinforcement Learning: An Introduction: http://incompleteideas.net/book/the-book-2nd.html
- Szepesvári, Algorithms of Reinforcement Learning: http://www.ualberta.ca/~szepesva/RLBook.html
Thank you for your attention!
01 - RL Intro
By supergriver




