Lecture 11:
Reinforcement Learning
on Multiple Tasks
Artyom Sorokin |22 Apr
Monstezuma's Revenge, again

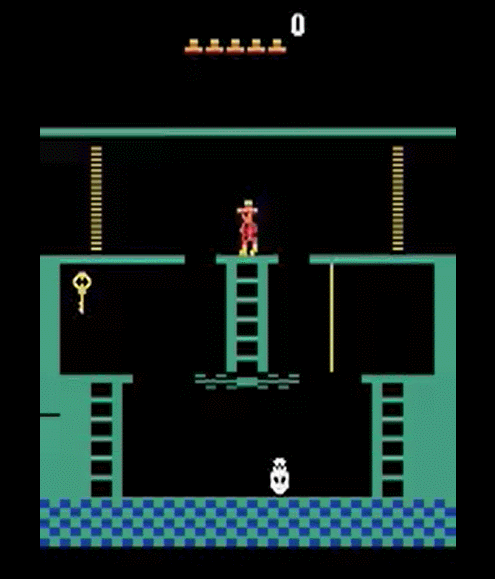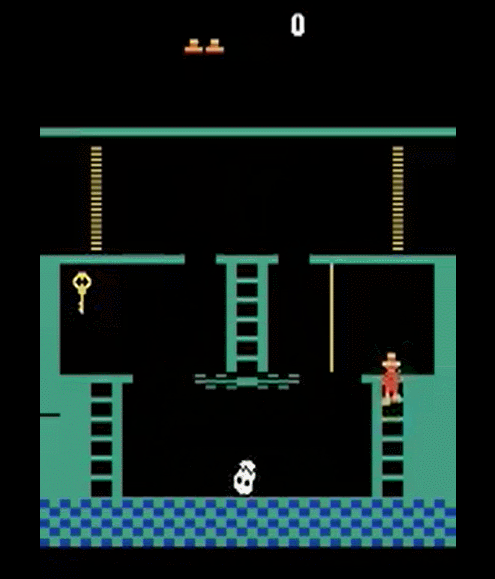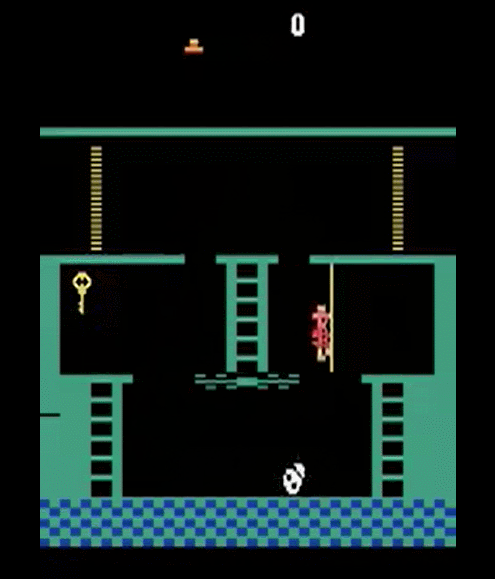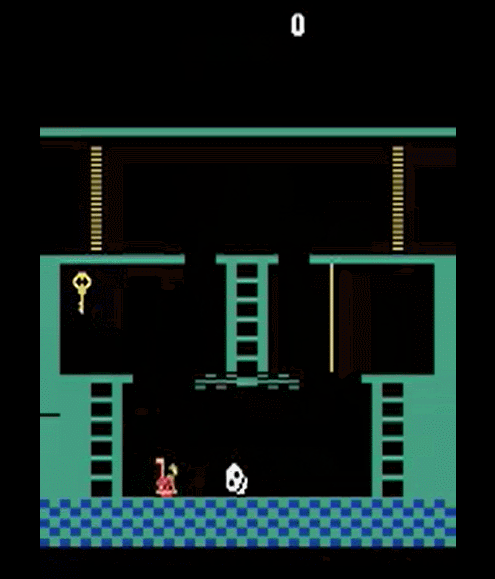
Let's look again at montezuma's Revenge, everybody loves it!
It is pretty obvious what to do in this game...

Monstezuma's Revenge, again
Let's look again at montezuma's Revenge, everybody loves it!
It is pretty obvious what to do in this game...
for humans
but not for RL Agents
Monstezuma's Revenge, again
- We know what to do because we understand what these sprites mean!
- Key: we know it opens doors!
- Ladders: we know we can climb them!
- Skull: we don’t know what it does, but we know it can’t be good!
- Prior understanding of problem structure can help us solve complex tasks quickly!
Patformers without Priors



Can RL use the same prior knowledge?
- If we’ve solved prior tasks, we might acquire useful knowledge for solving a new task
- How is the knowledge stored?
- Q-function: tells us which actions or states are good
- Policy: tells us which actions are potentially useful
- some actions are never useful!
- Models: what are the laws of physics that govern the world?
- Features/hidden states: provide us with a good representation
- Don’t underestimate this!

Representation bottleneck

Paper: Loss is its own Reward
Transfering knoledge between tasks in RL
Main Idea:
Use experience from one set of tasks for faster learning and/or better performance on new tasks!
In RL, task = MDP!

Source Task
Target Task
Transfering knoledge between tasks in RL
Transfer Learning:
- Learning: First train on Source Tasks then learn Target Tasks faster/better!
- Goal: Learn the Target Task faster or better
Train here
then train here
evaluate on this
Source Task
Target Task
Transfering knoledge between tasks in RL
Multi-Task Learning:
- Learning: Train on multiple Tasks
- Goal: One Agent that can solve all these tasks
Train here
and here
evaluate on here

and here
Source/Target Domains
Transfering knoledge between tasks in RL
Meta Learning:
- Training: Learn to learn on multiple tasks
- Goal: Agent that adapts quickly to new tasks
Train on these tasks
Source Tasks
Typically agent don't know which task it learns!
Try to learn as fast as possible:
- 1-shot
- 2-shot
- few shot
Evaluate here
Sample
new tasks
Transfering knoledge between tasks in RL
Lifelong/Continual Learning:
- Training: Learn first task --> then second task --> then third --> ....
- Goal: Perform well on all tasks! Learn new tasks faster!
Train here
retraining on old tasks is cheating!
Evaluate an all these tasks

then here
then here
then here
then here
then here
Transfering knoledge between tasks in RL
Main Idea:
Use experience from one set of tasks for faster learning and/or better performance on new tasks!
Transfer Learning:
- Learning: First train on Source Tasks then learn Target Tasks faster/better!
- Goal: Best Perofrmance at the Target Task
Multi-Task Learning:
- Learning: Train on several Tasks simultaneously
- Goal: One Agent that can solve all tasks
Meta-Learning:
- Learning: Train on set of tasks without knowing which task is it
- Achieve performance on new tasks
Transfer in Supervised Learning
Pretraining + Finetuning:
The most popular transfer learning method in (supervised) deep learning!

Finetuning: Problems in RL Setting
- Domain shift: representations learned in the source domain might not work well in the target domain
- Difference in the MDP: some things that are possible to do in the source domain are not possible to do in the target domain
- Finetuning issues: The finetuning process may still need to explore, but optimal policy during pretraining may be deterministic!


Fighting Domain shift in CV
Invariance assumption: everything that is different between domains is irrelevant


train here
do well here
Task Loss
\(D_{\phi}(z)\)
CE-Loss
for Domain Classification
(same network)
Multiply grads from \(D_{\phi}(z)\) by \(-\lambda\)
i.e. train \(z\) to maximize CE-Loss
&
Domain Adaptation in RL
Invariance assumption: everything that is different between domains is irrelevant

Transfer when Dynamic is Different
Why is invariance not enough when the dynamics don’t match?

Off-Dynamics RL: Results

Finetuning issues
- RL tasks are generally much less diverse
- Features are less general
- Policies & value functions become overly specialized
- Optimal policies in fully observed MDPs are deterministic
- Loss of exploration at convergence
- Low-entropy policies adapt very slowly to new settings

Pretraining with Maximum Entropy RL


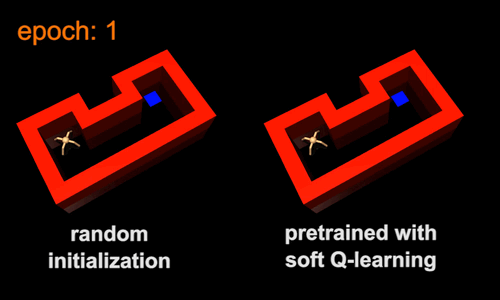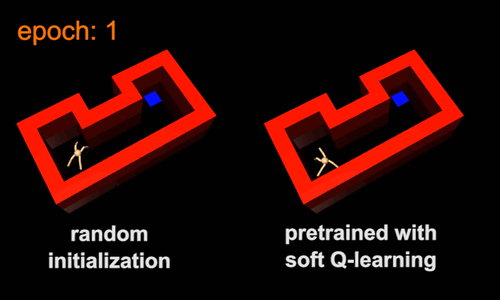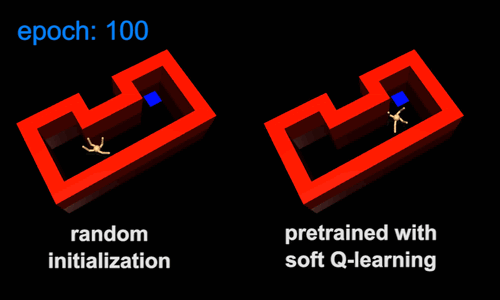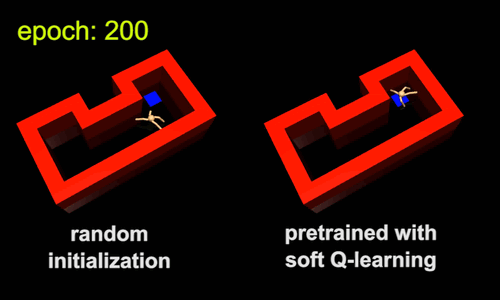
Forward Transfer with Randomization
What if we can manipulate the source domain?
- So far: source domain (e.g., empty room) and target domain (e.g., corridor) are fixed
- What if we can design the source domain, and we have a difficult target domain?
- Often the case for simulation to real world transfer
Randomizing Physical Parameters

Preparing for the unknown: Parameter Identification

Looks like Meta-Learning to me...

Another Example: CAD2RL

Transfer for different goals:
Assumption:
The dynamics \(p(s_{t+1}|s_t, a_t)\) is the same in both domains but reward function is different
Common examples:
- Autonomous car learns how to drive to a few destinations, and then has to navigate to a new one
- A kitchen robot learns to cook many different recipes, and then has to cook a new one in the same kitchen
Model Transfer

Model: very simple to transfer, since the model is already (in principle) independent of the reward
You can also transfer contextual policies, i.e. \(p(a|s, g_i)\)!
Adding Multi-Tasking for Better Learning
Sparse Reward setting:
- Reward only for reaching the goal state

Problem: RL learns nothing from failed attempts!

Adding Multi-Tasking for Better Learning
But humans can learn in the similar setting:

Adding Multi-Tasking for Better Learning
We can interpret all outcomes of agents' actions as goals:
Adding virtual goals creates a multi-task setting and enriches the learning signal!

Hintsight Experience Replay
Paper: Hindsight Experience Replay
Main Idea: substitute achieved results as desired goals
HER main components:
- Goal Conditioned Policies and Value Functions
- Any off-policy RL Algorithms: DDPG, DQN, etc..
- A method for virtual target selection
- A special replay buffer with goal substitution

Hintsight Experience Replay

Paper: Hindsight Experience Replay
Hintsight Experience Replay


Paper: Hindsight Experience Replay
Value Transfer: Successor Representations
Multi-Task Reinforcement Learning
Can we learn faster by learning multiple tasks?
Multi-task learning can:
- Accelerate learning of all tasks that are learned together
- Provide better pre-training for down-stream tasks

Sounds familiar... Domain Randomization?
Can we solve multiple tasks at once?
Multi-task RL corresponds to single-task RL in a joint MDP:

Can we solve multiple tasks at once?
- Gradient interference: becoming better on one task can make you worse on another
- Winner-take-all problem: imagine one task starts getting good – algorithm is likely to prioritize that task (to increase average expected reward) at the expensive of others
- In practice, this kind of multi-task is very challenging unless you have a lot of data and computation (see. GATO)
Policy Distilation

This solution doesn't speed up learning as it doesn't transfer anything...
Idea: Learn with RL, transfer with SL
Papers: Actor-Mimic, Policy Distillation
Policy Transfer in MT:
Divide And Conquer
Divide and Conquer Reinforcement Learning Algorithm sketch:

Policy Transfer in MT:
Divide And Conquer

Policy Distilation on Steroids: GATO
Paper: A Generalist Agent

Policy Distilation on Steroids: GATO
Paper: A Generalist Agent

Secrets to success:
- Generate a lot of Data
- Use huge Transformer model
- a lot of computing resources
Policy Distilation on Steroids: GATO
Paper: A Generalist Agent
Secrets to success:
- Generate a lot of Data
- Use huge Transformer model
- a lot of computing resources
Policy Distilation on Steroids: GATO
Paper: A Generalist Agent

Policy Transfer in MT:
Reusing Policy Snippets


Representation Transfer in MT:
Progressive Networks
Paper: Progressive Neural Networks

Finetuning allows to transfer representations from task 1 to task 2
But what if you want to learn task3 next, and then task4...
This is actually a LifeLong Learning!
Progressive Networks: Results

Paper: Progressive Neural Networks
Progressive Networks: Representation Transfer
Paper: Progressive Neural Networks

Representation Transfer in MT: PathNet
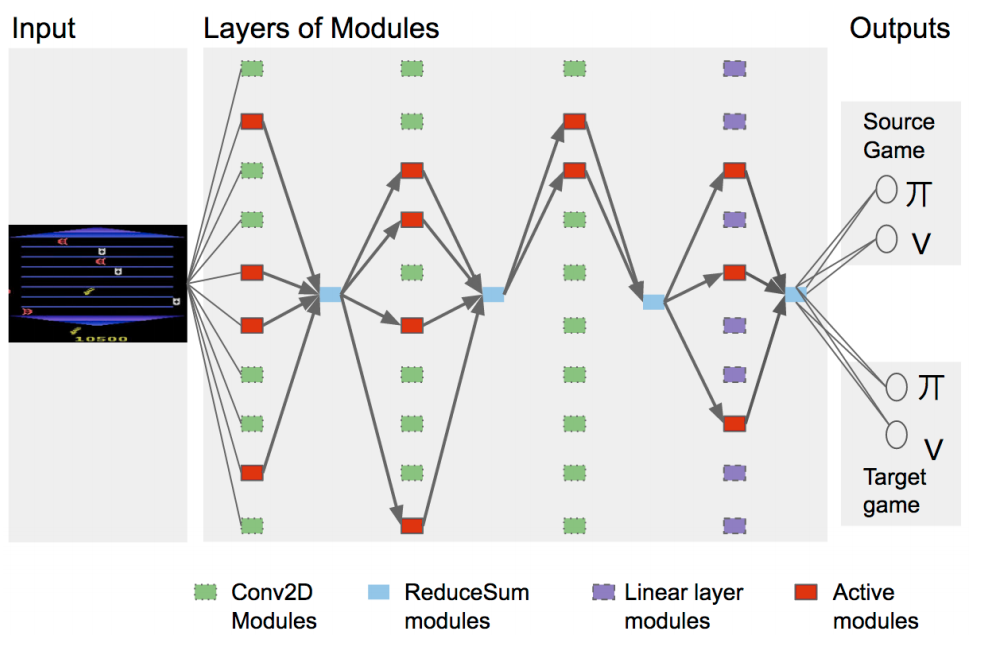
Representation Transfer in MT: PathNet
PathNet key details:
- Each layer has K independent modules
- A pathway uses only 4 modules from each layer
- Sum outputs of all selected modules from one layer
PathNet: Single Task Learning
Train PathNet on a single Task:
- Generate a population of pathways
- Train a population of pathways for T episodes with SGD
- Compare B pathways: ovewrite the loosers and mutate the winners
- GoTo step 2
Train PathNet on a single Task:
- Generate a population of pathways
- Train a population of pathways for T episodes with SGD
- Compare B pathways: ovewrite the loosers and mutate the winners
- GoTo step 2
Train PathNet on a single Task:
- Generate a population of pathways
- Train a population of pathways for T episodes with SGD
- Compare B pathways: ovewrite the loosers and mutate the winners
- GoTo step 2
Train PathNet on a single Task:
- Generate a population of pathways
- Train a population of pathways for T episodes with SGD
- Compare B pathways: ovewrite the loosers and mutate the winners
- GoTo step 2
Train PathNet on a single Task:
- Generate a population of pathways
- Train a population of pathways for T episodes with SGD
- Compare B pathways: ovewrite the loosers and mutate the winners
- GoTo step 2
PathNet: Multi-Task and Lifelong Learing
Training on multiple Tasks:
- Train on Task 1
- Freeze the best performing pathway (Task 1)
- Train on Task 2
- Frozen modules still conduct gradients
- Repeat
PathNet: Multi-Task and Lifelong Learing
PathNet: Multi-Task and Lifelong Learing

Resources:
Thank you for your attention!
11 - Learning on Multiple Tasks
By supergriver




