How to read a paper*
Suriyadeepan Ramamoorthy
*How to read a "Deep Learning" research paper
Keshav's 3 Pass Method

3 Pass Method
- Pass 1 [ 5 - 10 mins ]
- Pass 2 [ 1 hour ]
- Pass 3 [ few hours? ]
3 Pass Method
- Get the gist of it ( bird's eye view )
- Grasp Contents ( but not the details )
- Understand in depth ( put it all together )
3 Pass Method
- Each pass has a specific goal
- Builds on top of the previous
Pass 1
- Quick Scan
- Bird's Eye view ( the gist of it )
- Decide if you should keep going
- Enough for papers
- not in your research area
Pass 1
- Read Carefully
- Title
- Abstract
- Introduction
- Conclusion
- Section, Subsection Titles
- Glance through
- equations
- references
Pass 1
- References
- Tick off the papers that you are familiar with
Pass 1
- References
- Tick off the papers that you are familiar with
Pass 1
- Objectives : 5 C's
- Category
- Context
- related papers
- Correctness
- Contributions
- Clarity
Pass "dos"
- Read with greater care
- Takes about an hour for experienced reader
- Enough for papers that are interesting
- but not your research speciality
- Computer Vision?
- but not your research speciality
Pass 2
- Objective
- Summarise the paper to someone
- with supporting evidence
- Summarise the paper to someone
Pass 2
- Highlight key points
- Make comments
- Terms you don't understand
- Questions for the author
- Use comments to write a review
Pass 2
- Figures, Graphs and such
- Tick relevant unread references
Hold on!
What if I still don't get it?
Like, at all?
Bulk of it is just incomprehensible
Why?
- New Subject Matter
- Unfamiliar Terminology/acronyms
- Weird unfamiliar techniques?
- Is it badly written?
- Or you are just tired man!
What to do about it?
- F**k it! Let's go bowling
- Or.. may be
- Read background and get back to it
- Power through pass 3
Pass 3
- 2 to many hours
- Great attention to detail
- Challenge every assumption
- How would you present the same idea?
Pass 3
- Make the same assumptions
- Recreate the work
- Compare with the actual paper
- Identify
- Innovations
- Hidden Failings
- Assumptions
Pass 3
- Goal
- Reconstruct the entire structure of the paper from memory
- Identify Weak and Strong points
Bonus Round
How to do a Literature Survey?
Literature Survey
- Google Scholar / Semantic Scholar
- bunch of carefully-chosen keywords
- 3-5 highly cited papers
Literature Survey
- One pass on each paper
- Find shared citations, repeated author names
- Key papers
- Download them
- Key researchers
- Key papers
- Find top conferences
Literature Survey
If you are lucky enough to find a survey paper,
You are done.
Literature Survey
- Papers from
- Recent Proceedings
- Key Papers from Key Researchers
- Shared Citations
- Combine them
- And it becomes the first version of the survey
ULMFiT
Universal Language Model Fine-Tuning for Text Classification
Universal Language Model Fine-Tuning for Text Classification
Abstract
Inductive transfer learning has greatly impacted computer vision, but existing approaches in NLP still require task-specific modifications and training from scratch. We propose Universal Language Model Fine-tuning (ULMFiT), an effective transfer learning method that can be applied to any task in NLP, and introduce techniques that are key for fine-tuning a language model. Our method significantly outperforms the state-of-the-art on six text classification tasks, reducing the error by 18-24% on the majority of datasets. Furthermore, with only 100 labeled examples, it matches the performance of training from scratch on 100x more data. We open-source our pretrained models and code.
Ideas
Inductive vs Transductive Transfer
Ideas
Language Modeling is the ideal source task.
Imagenet for NLP
Language Modeling
- Common / General Linguistic Features
- Long-term dependencies
- Hierarchical Relations
- Sentiment
- Key component of every other NLP task
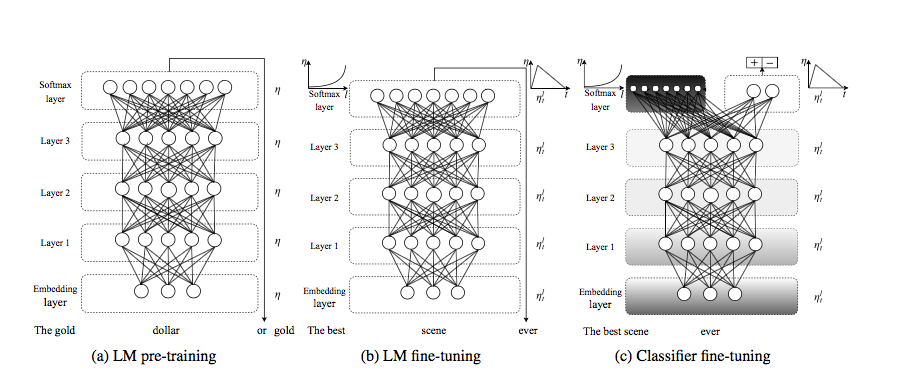
Steps
- General Domain LM Pretraining
- Target-task LM Fine Tuning
- Target-task Classifier Fine Tuning
Dataset
- Pre-training on Wikitext-103
- ~28K Wiki Articles
- 103 Million words
Discriminative Fine-tuning
- Key Idea
- Different layers capture different types of information
- Fine-tune to different extents
- Tune layers with different learning rate
- A variant of SGD to exploit this insight
Discriminative Fine-tuning
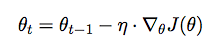
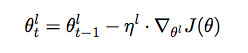
Slanted Triangular LR (STLR)
- Ideally
- Quickly converge to suitable region of parameter space
- Variant of Triangular LR*
- Short Increase
- Long Decay Period
Slanted Triangular LR (STLR)
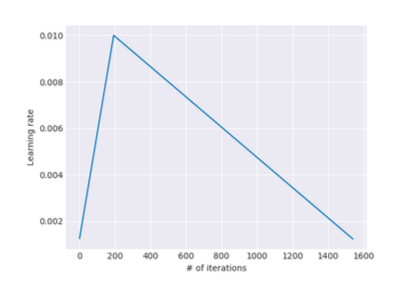
STLR
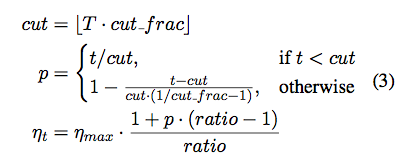
Target Task Classifier Fine Tuning
- Aggressive Fine Tuning leads to
- Catastrophic Forgetting
Gradual Unfreezing
- To overcome Catastrophic Forgetting
- "chain-thaw"?
- that sounds interesting
- Unfreeze the model in iterations
- Start with the Last Layer
- Last Layer
- Least General Knowledge
Gradual Unfreezing
- Start with the Last Layer
- Fine-tune for 1 Epoch
- Unfreeze next lower layer
- Fine-tune for 1 Epoch
- ...
Classifier Fine Tuning
- Add two Linear Layers
- Only parameters learned from scratch
- Batch Normalization
- Drop out
- ReLU Activation for the first linear layer
- Softmax at the end
Classifier Fine Tuning
- "concat-pooling"?
- that sounds interesting
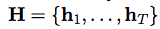
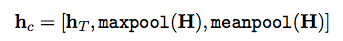
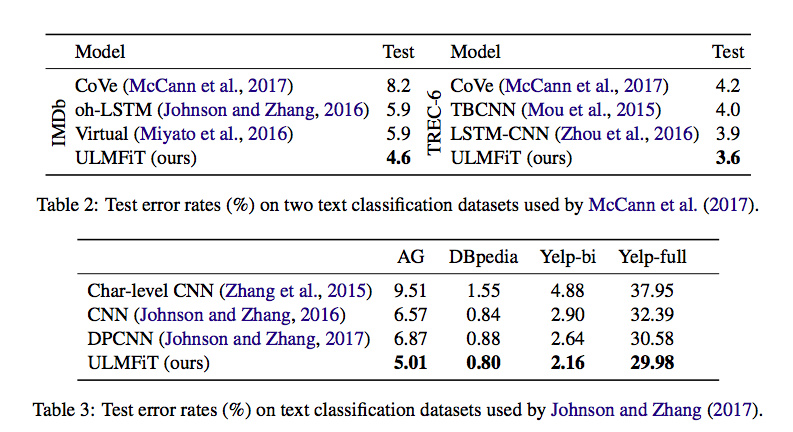
Results
Adios!
How to read a paper*
By Suriyadeepan R




