Data warehouse frameworks
DOs and DON'Ts
and maybe a few words about DBT framework
What is a DWH Framework?
- Encapsulates transformation
- Provides logging
- Composability
- Teamwork, collaboration
- Version and change management (different targets, environments, git integration, etc)
- Documentation
- Testing pipelines (CI/CD)
- Deployment
- Job execution, dependency management (DAGs)
- Execution handling
Yes, we need all of these.
ETL Tools
Point and click adventure
$$$
- Alteryx
- Talend
- Informatica
- Matillion
ETL Frameworks
Code (SQL and/or Python)
$
- dbt
- airflow
- metaflow
- beam
- home grown shit
Good framework generates SQLs and keeps transformation inside the database
And now some rants.
Why you *must* not build frameworks in UDFs/Stored Procedures
Team Work with UDF/SP
Expectation
- Multiple teams can work on different features in the same database
- Isolation, people can work on the same loads
Reality
- Two people cannot work on the same function
- No easy way to merge code from different branches
Issues
- Manually identify what things have changed by a new feature?
- How to tie table changes with code changes as one package
Object Persistence with SPs
Expectation
- Code is isolated from the data. You can take a production source data dump and easily re-build the data warehouse (One-click deployment in a new db)
- Seed management (like static lookups)
Reality
- When you copy prod data to stage you are fucked
- build a new environment takes forever
- no clear definition in object dependency
- shitton of manual metadata
Issues
- a lot.
Version and change control with SPs
Expectation
- Tight git integration (read only master branch, feature branching)
- Easy way to change source and target DBs, schemas, tables
- Jobs ALWAYS coming from the versioned entities
Reality
- You CANNOT enforce to run things directly from git
- no automated way to deploy the DB objects with code (migration support)
Issues
- you will be always inconsistent with your version manager tool as UDFs cannot be executed from git for instance
- Implementing your own change management will take an infinite amount of time. Rollback will suck, always.
Logging and Metadata stored in Database
Expectation
- Logs are easy to read, easy to search
- No impact on database performance or transactions
- In case of a database issue, jobs still can log what went wrong
Reality
- Logging will fuck up performance and transaction contexts
- If the database dies, your logging dies
Issues
- When refreshing data from prod to dev, you override your past logs and metadata
- Versioning metadata and seed along with the code is impossible if it is stored in database
IN SHORT
DO NOT, I REPEAT, NEVER USE STORED PROCEDURES OR UDFs TO IMPLEMENT ETL JOBS OR FRAMEWORKS
THANK YOU, THE HUMANITY
OKAY, THEN WHAT?
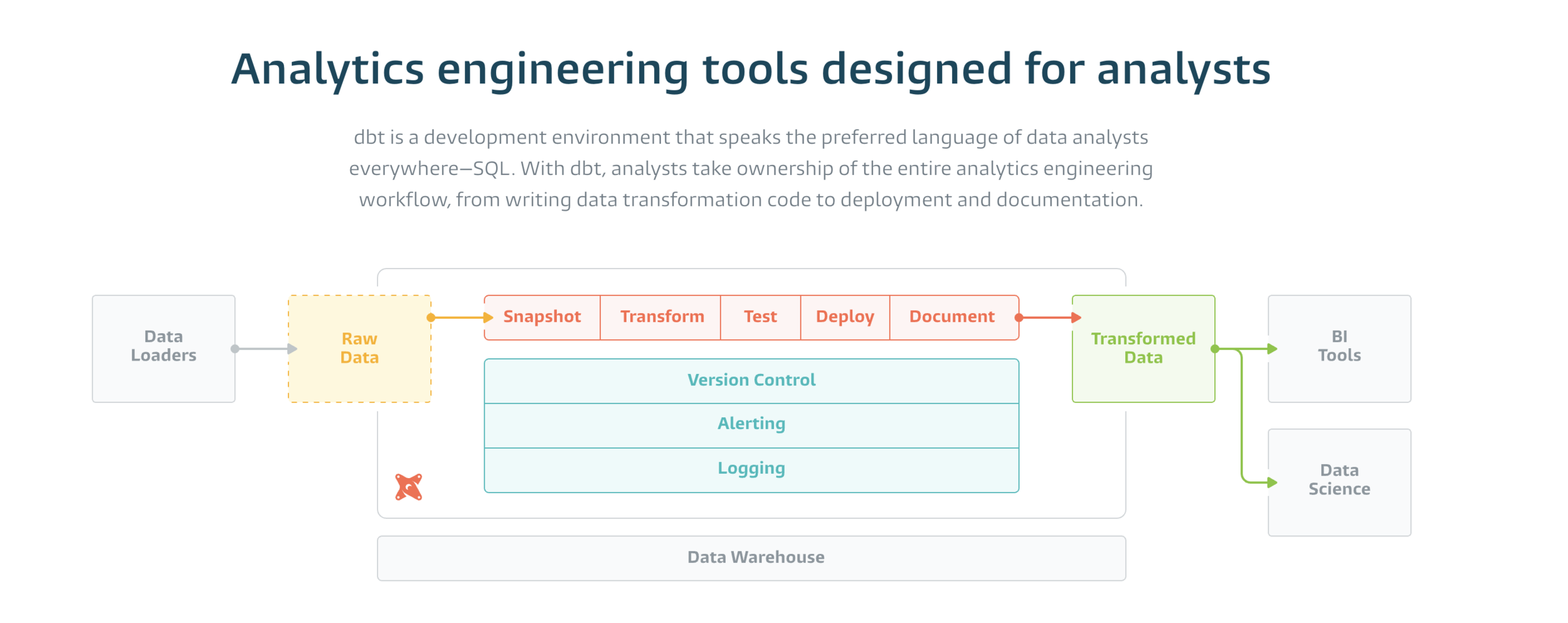
Use DBT!
WTF is dbt?
DBT is data pipeline framework, using SQL, generated from python.

What's inside?
- All transformations (models) are SQL with jinja templating
- Utils (SCD, snapshot)
- GIT, CI/CD and everything you're using when you dev sw
- Dependency management
- Deployment (dev, test, prod)
- Job execution
Few Concepts
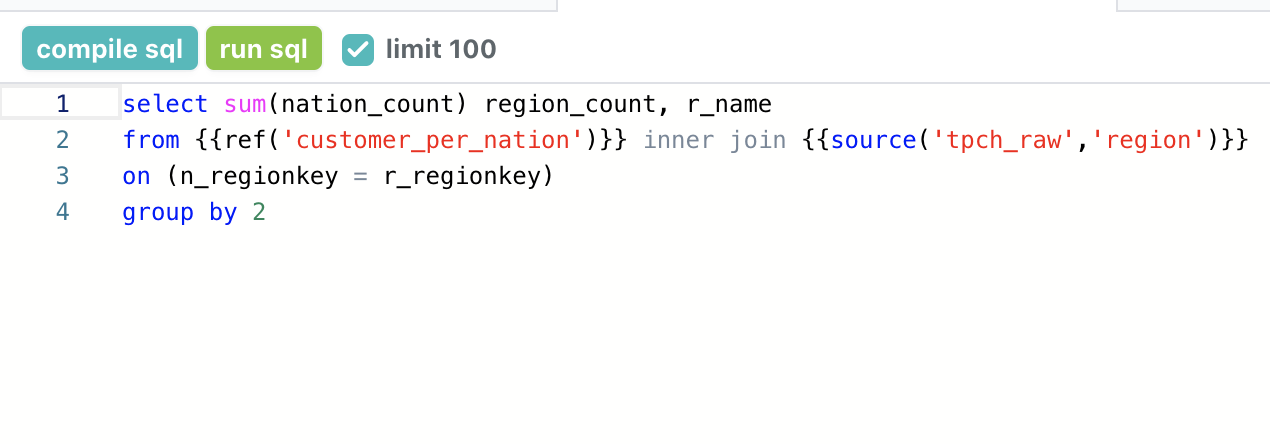
Models = Transformation = SQL
Models = Transformation
1 Model = 1 SQL statement
Materialization can be a view, table, temp table, or custom
Handles schema changes
BTW, refreshing models
Truncate Insert is dead.
Long Live The
CREATE OR REPLACE TABLE
Other DBT things
- Source - define source systems, tables
- Snapshots - SCD Type2/6 tables
- Incremental Models
- Macros - inline, reusable functions
- Exposures - external dependencies
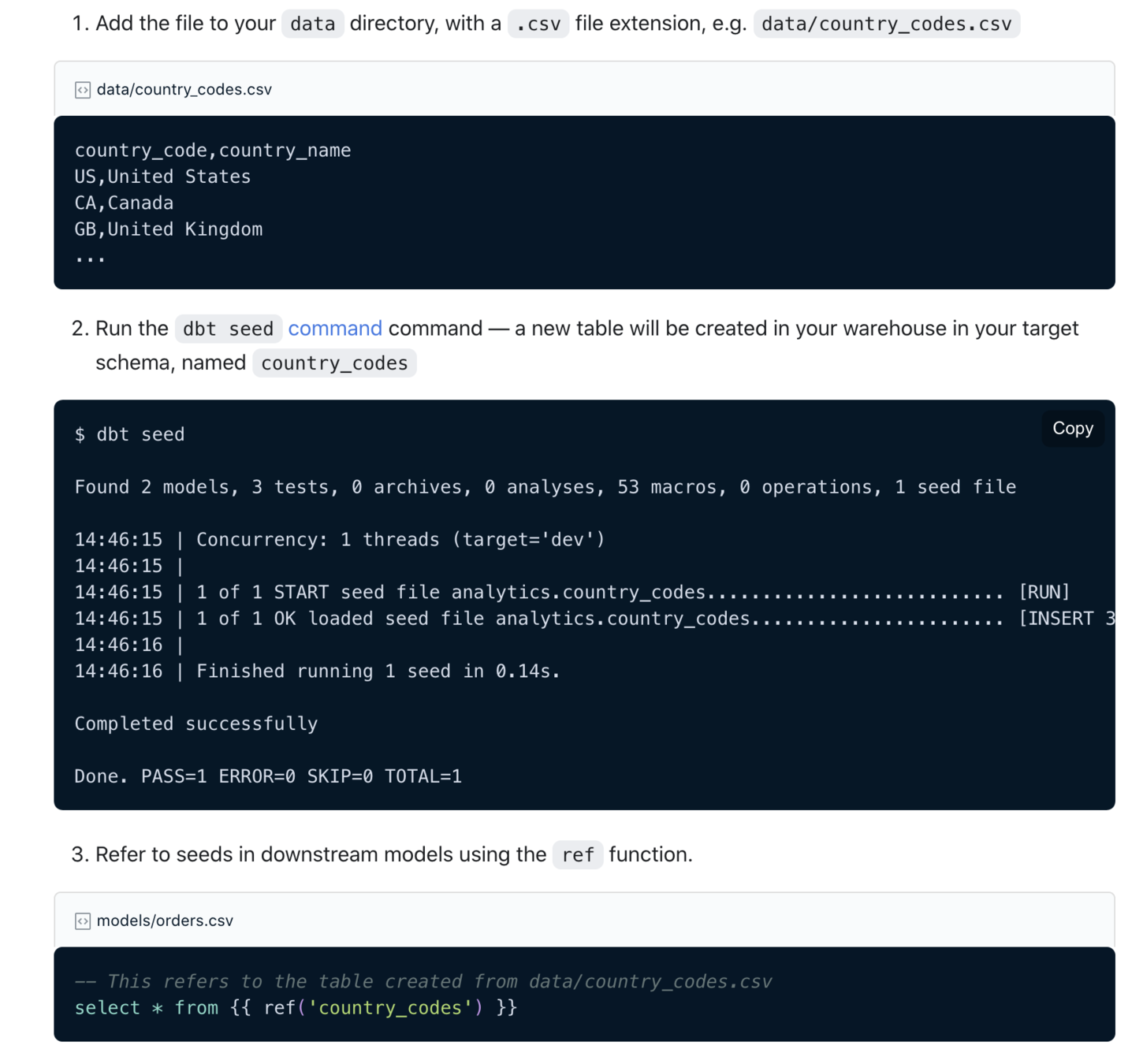
- Seeds
- Tests
Seed.
DEMO
QUESTIONS
Data warehouse frameworks
By Tamas Foldi



