Machine Learning in Databases
Hash Tables, B-Trees, and Learned Indexes
Tyler Elliot Bettilyon

Teb for short.
I used to work at some startups that don't matter.
I teach programming and computer science.
I write about technology and its impact on the world.
Tyler Elliot Bettilyon

Website: www.tebslab.com
Medium: @tebbaVonMathenstien
Twitter: @TebbaVonMaths
What Is This Talk About?
Database Indexing
- You have a lot of data to store.
- You need to look up specific items quickly.
- We use an index for this.
What Is This Talk About?
Well Known Indexing Strategies
- Hash tables
- B-Trees
What Is This Talk About?
New Research Into "Learned Indexes"
- Google + MIT Collaboration
- https://www.arxiv.com/papers/1712.01208/
What Is This Talk About?
How Do Learned Indexes Stack Up?
- When do the old-school algorithms have an advantage?
- When do learned indexes have an advantage?
- What are the trade-offs at play?
What Is Indexing?
Indexing helps us quickly find specific items within a large collection of data.
Especially helpful when that data is not sorted by the field you're querying against.
What Is Indexing?
id: 0
name: Teb
age: 79
...
This is a single row in a database table
These are all rows in the same table
What Is Indexing?
Where is Tim?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
What Is Indexing?
Finding Tim Without an Index...
X
√
?
?
?
?
?
?
?
?
?
?
Are you Tim?
X
X
X
X
What Is Indexing?
Finding Tim With an Index
Tim
The Index
Where is Tim?
Offset 7
What Is Indexing?
Indexing is a trade off between memory usage and computation speed.
The index occupies memory, but it makes queries faster.
Performance of Indexes
5 major performance considerations:
- Type of query (individual vs range)
- Lookup speed
- Cost of inserting a new record
- Cost of deleting a record
- Total size & utilization rate
Performance of Indexes
Type of Query
Where is Tim?
Fetch everyone age 5-12.
Performance of Indexes
Lookup Speed
The Index
Where is Tim?
Offset 7
How long does this take?
Performance of Indexes
Cost to insert
id: 99
name: Yannet
age: 30
...
The Index
How long does it take to update the index?
Performance of Indexes
Cost to delete
The Index
How long does it take to update the index?
Performance of Indexes
Size & utilization
The Index
How much additional data is this index?
What is the information density of this index?
Performance of Indexes
A Caveat
Indexing is primarily a tool used when there is a lot of data.
Optimizing for the number of hard drive accesses is more common than optimizing for total operations
Hash Tables
Hash Function
Arbitrary Data
Integer
Hash functions map arbitrary data to an integer, deterministically.
Hash Tables
Hash Table
Hash Function
Arbitrary Data
Integer
Hash table indexes map those integers to memory locations of database records
Memory Address
Hash Tables
Hash Function
"Tim"
15
The Hash Table:
The Database Table:
Hash Tables
- Great for individual lookups, poor for range queries.
- Query time is O(1) — access the index once then access memory once.
- Insertion and deletion are O(1) — access the index once.
- Size & Utilization varies based on the choice of hash function and collision handling strategy — it's common for hash tables to have ~50% utilization.
Performance
Hash Tables
- Collision handling strategy can make a huge difference (Linear probing vs chaining vs cuckoo hashing).
- Inserts might require the whole index to be rebuilt if there are too many collisions, or the table runs out of space, which also impacts utilization.
- Hash function choice can impact rate of collisions and speed to compute, which can impact speed and utilization.
Gotchas
B-Trees
The structure of a B-Tree represents sorted data, similar to a Binary Search Tree.
...
First
Last
...
B-Trees
The root node and each internal node are lists of pointers to sorted sections of the overall data.
| a | b-d | e-g |
|---|---|---|
| h-l | j-p | q-t |
| u-v | w-x | y-z |
| aa-ab | ac-ad | ae-ag |
|---|---|---|
| ah-al | aj-ap | aq-at |
| au-av | aw-ax | ay-az |
| aeon | afar |
|---|---|
| afraid | agriculture |
Root
Internal
Leaf
B-Trees
Leaf nodes contain the items themselves and a pointer to their values location in the database
| a | b-d | e-g |
|---|---|---|
| h-l | j-p | q-t |
| u-v | w-x | y-z |
| aa-ab | ab-ad | ae-ag |
|---|---|---|
| ah-al | aj-ap | aq-at |
| au-av | aw-ax | ay-az |
| aeon | afar |
|---|---|
| afraid | agriculture |
Root
Internal
Leaf
B-Trees
Because indexes are optimized for hard drive access, the size of each node is often based on hard drive block size.
...
First
Last
...
Root
2. Iterate over block
Hard Drive/Secondary Storage
3. Indicates which block to read next
1. Read block to RAM
B-Trees
- Great for range queries, and still pretty good for individual queries.
- Query time is O(log n) — leaf nodes contain the actual data we need and the tree depth is log n.
- Insertion and deletion are O(log n) — same as querying.
- Size & Utilization varies based on the size of each node, overall balance of the tree, and how full each node is.
Performance
B-Trees
- B-Trees must be relatively balanced or performance won't be O(log n).
- Inserting into an already full node can result in that node being "split" into two — Costs extra computation plus both nodes will be at low (~50%) utilization.
- Deleting a node might require an expensive rebalancing operation.
Gotchas
Learned Indexes
A Google + MIT Collaboration explored the idea of applying machine learning to indexing
https://arxiv.org/abs/1712.01208
Learned Indexes
"Hash Tables and B-Trees are just models"
Index
Item of Interest
Location in Memory
This is essentially regression!
Learned Indexes
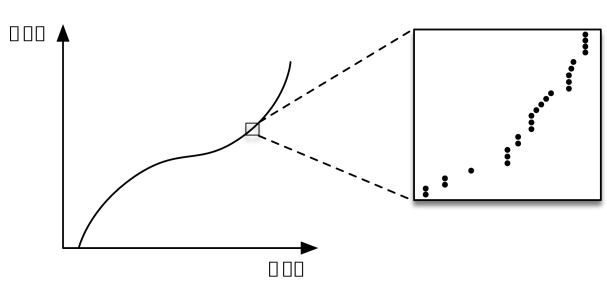
"Range indexes are just CDFs"
estimatedPosition = Model(key) ∗ numberOfElements
Learned Indexes
One important caveat...
ML Model
Item of Interest
Approximate Location in Memory
Indexes must return the exact location in memory — there is no room for any error.
Learned Indexes
This is addressed by storing the min and max error over the dataset.
ML Model
Item of Interest
Approximate Location in Memory
Lookups don't have as strong theoretical guarantees, but are bounded by magnitude of maxError - minError
Min Error
Max Error
Learned Indexes
ML Model
Item of Interest
Approximate Location in Memory
Min Error
Max Error
Min Error + Guess
Max Error + Guess
Guess
Learned Indexes
Models could also replace hash functions.
Hash Function
Arbitrary Data
Integer
ML
Model
Arbitrary Data
Integer
Hash Table
Learned Indexes
The researchers used a collection of simpler models, not a single large model.
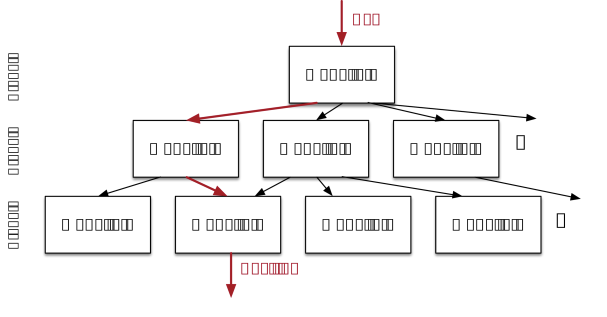
This helped with last mile accuracy.
Lessons Learned
The researchers focused on simple models. The paper is a proof of concept.
- Researchers focused on small fully connected neural nets.
- Focused on create once, read only, in memory, data structures.
- Write heavy workloads are a huge problem for these models, and this paper doesn't even try to address that.
Lessons Learned
Promising size and speed savings!
B-trees compared to learned indexes
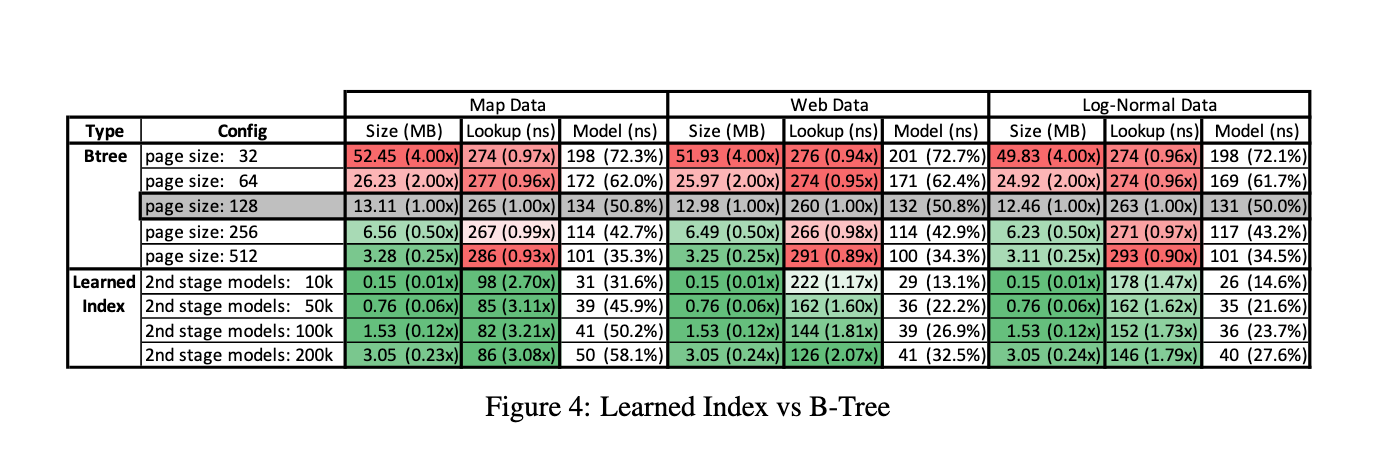
Lessons Learned
Promising utilization improvements, slower speeds
Learned hash functions compared to standard hash function

Models are better at taking the distribution into account
- B-Trees and Hash Tables are agnostic of the data's distribution, which negatively impacts utilization.
- ML Models inherently take the distribution of the data into account, which can help with utilization rates.
Lessons Learned
Lessons Learned
Overfitting is kind of the goal.
- Indexes never have to predict the location of data that hasn't yet been indexed.
- Accurate 'predictions' for data in the index is much more important than generalizing to held out data.
Average Error is less important than error bounds
Min Error + Guess
Max Error + Guess
Guess
Lessons Learned
Interesting properties at scale
- Standard indexes grow as the input data grows.
- An ML Model's size may not have to scale up as data grows, it only needs sufficient complexity to produce N values as output.
Lessons Learned
Takes advantage of new hardware
- Moore's Law is dead or dying and classical index structures are not well suited to parallelization.
- ML workloads are a main driver of current hardware advancements — meaning learned indexes are better positioned to take advantage of new hardware
Lessons Learned
Multidimensional indexing
- Classical index structures only take into account one feature of some data.
- Learned index structures could index across multiple dimensions, allowing a wide variety of queries and filters to be applied at once.
- This is because of ML's strength in identifying high dimensional relationships
Lessons Learned
Thanks For Coming
My name is still Tyler Elliot Bettilyon
Website: www.tebslab.com
Medium: @tebbaVonMathenstien
Twitter: @TebbaVonMaths
Thanks For Coming
My name is still Tyler Elliot Bettilyon
I'm teaching a deep learning course focused on computer vision starting Tuesday the 28th.
Learned Indexes
By tebba-von-mathenstein
