Herramientas para la gestión de datos sobre internet
7ma JoInEA - Septiembre de 2015
Equipo de trabajo: H. Kuna, E. Martini, A. Canteros, A. Cantero, A. Rambo, C. Biale, N. Corrales, E. Zamudio, M. Rey
Programa de Investigación en Computación
FCEQyN - UNaM
Situación actual [2015]
Además se definieron los componentes principales para su funcionamiento:
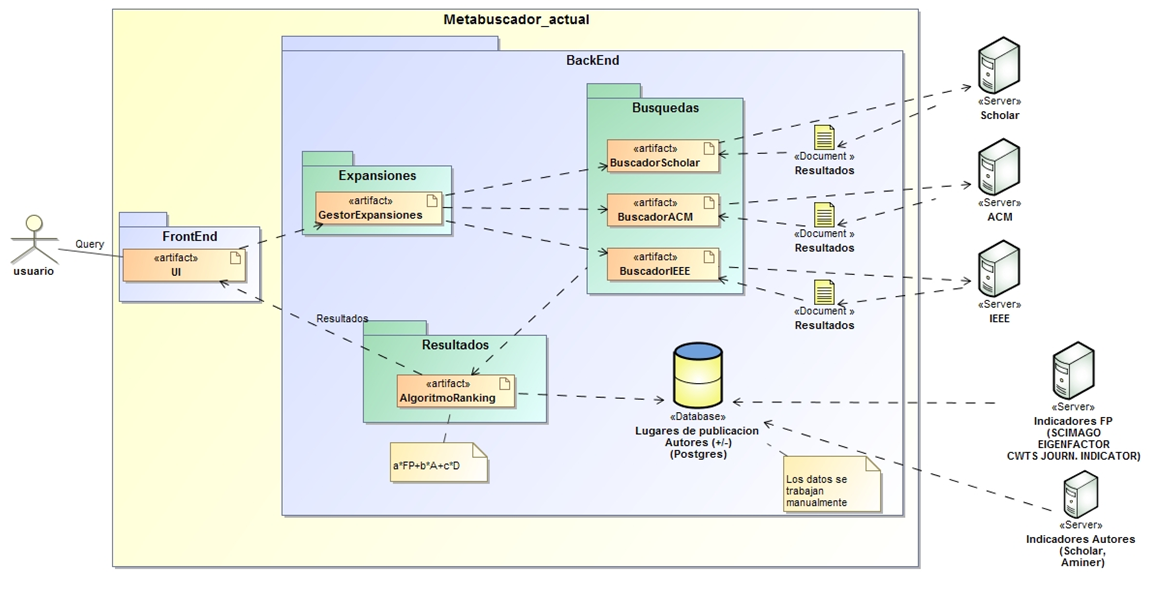
Se generó un meta-buscador para la búsqueda de documentos científicos en el área de Ciencias de la Computación.
- Módulo de gestión de consultas > Expansión de consultas a través de ontologías de dominio específico
- Módulo de gestión de búsquedas > Búsqueda de resultados en Google Scholar, IEEE, ACM (...)
- Módulo de gestión de resultados > Algoritmo de ranking para evaluación de documentos científicos
Arquitecura del meta-buscador
Inconvenientes del desarrollo
- Dificultad para acceder a datos para el algoritmo de ranking
- Constante actualización de las páginas (HTML) de los motores de búsqueda para artículos científicos
- Enfoque centrado en documentos, limitando el alcance de las búsquedas y la información presentada
- Falta de métodos de actualización constante para los valores de las métricas del algoritmo de ranking
- Imposibilidad de contar con cálculos propios de métricas
Un problema común a todos los inconvenientes > acceso a datos ad-hoc y por fuerza bruta
Solución (?)
[re]evolucionar el meta-buscador
Alternativas:
- Dejar de buscar sólo documentos, tener un enfoque más general. Resolver la consulta con datos de TODAS las dimensiones = [documentoss + autores + fuentes de publicaciones]
- Relacionar todos estos datos, para que el algoritmo de ranking sea más global y que los resultados sean más relevantes
Cómo llegar a la solución?
- Acceder, recuperar y guardar más datos, tanto en las búsquedas como para el cálculo del algoritmo de ranking.
- Generar perfiles para cada elemento de información a analizar >> documentos + autores + fuentes de publicación + métricas
- Documentos: citas - estadísticas de uso/impacto
- Autores: publicaciones históricas - relaciones de co-autoría - áreas de trabajo - índices H / G [+]
- Fuentes de Publicación: publicaciones históricas - autores históricos - categorías - áreas temáticas
- Métricas: valores - fuentes [+] - variantes
Dónde están los datos?






[Big Data]

Cómo empezar a generar a la solución?
Optimizar la recuperación de datos
ad-hoc >> un proceso unificado, componentes generalizables trabajando en conjunto
fuerza bruta >> acceso indirecto, automatizado, prolijo, adaptable
Una herramienta, una posible solución:

import.io
Características:
- Extracción de datos de sitios web sin plugins, sin programar, entrenando un conjunto de componentes desde una UI simple
- Capacidad para obtener datos desde listados de resultados (conector) y resúmenes de datos (extractor)
- Capacidad para agregar contenido semántico a los datos extraídos, dar un significado
- Generación de APIs para el uso de los componentes desarrollados desde otras soluciones [como nuestro meta-buscador]
Ejemplos en vivo
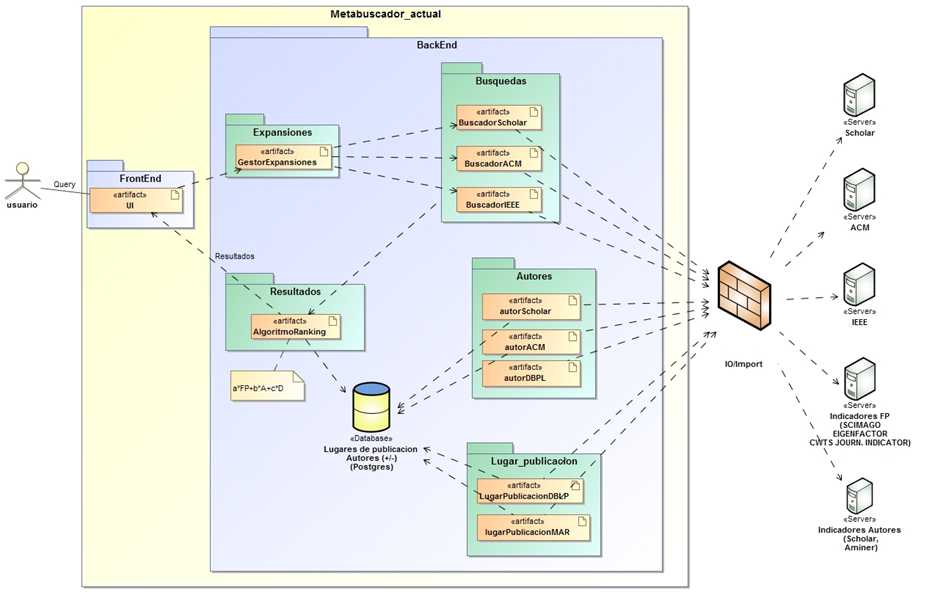
Arquitectura posible:
Trabajos futuros:
- Definir formalmente la nueva arquitectura del meta-buscador
- Definir desde dónde y qué datos se van a extraer y cómo se van a almacenar y relacionar
- Generar los elementos desde import.io para hacer las extracciones + evaluar los límites
- Refactorizar / Desarrollar los componentes que sean necesarios en el meta-buscador
- Resolver los nuevos problemas que se van a generar, por ejemplo: desambiguación en todo sentido, nuevos métodos para evaluación de impacto / relevancia, nuevos métodos para expandir consultas, etc...
Muchas gracias!
Preguntas?
Programa de Investigación en Computación
FCEQyN - UNaM
presentacion-JoInEA2015
By Martin Rey
presentacion-JoInEA2015
Herramientas para la gestión de datos sobre internet JoInEA 2015 PIC-FCEQyN-UNaM



