Meta-Buscador para Ciencias de la Computación
Estado a septiembre/2016
Objetivo
El proyecto fue pensado para generar un SRI (un meta-buscador) para la recuperación de documentos científicos del área de Ciencias de la Computación. Incorporando técnicas o soluciones que permitan optimizar la recuperación y obtener resultados de mayor relevancia.
Componentes desarrollados
[2013 - 2014]
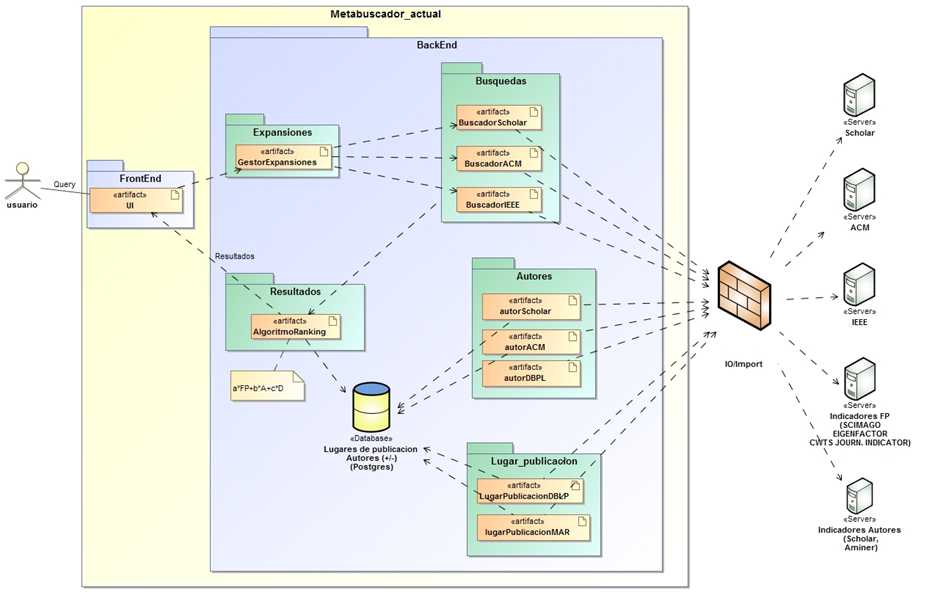
- Recuperación de datos de diversas fuentes (Artículos - Google Scholar, ACM DL, IEEE Xplore DL)
- Módulo para expansión de consultas (Ontología de IA)
- Evaluación de resultados en base a métricas del ambiente (Algoritmo de ranking)
Arquitectura del SRI
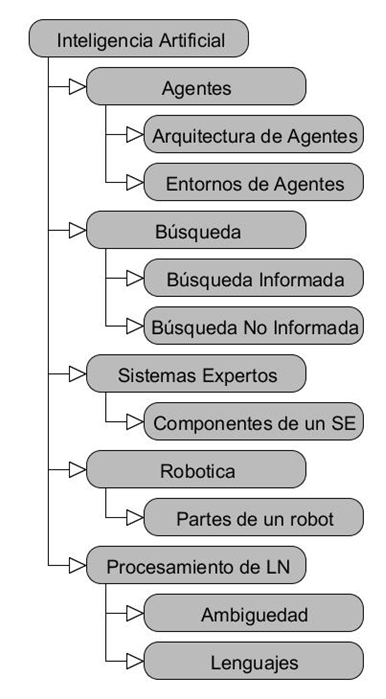
Expansión de Consultas
- Objetivo: integrar términos relacionados con la consulta generando expansiones de la misma que permitan focalizar la búsqueda para obtener mejores resultados.
- Resultados:
- Se generó una onología de dominio para el área de Inteligencia Artificial [spa]
- Se generó un método que usa la ontología para generar las expansiones de la consulta del usuario
- Se integró el método al SRI
Trabajo pendiente
- Integrar reconocimiento de idioma para búsquedas en inglés + castellano. Cambiando según la fuente a consultar.
- Incorporar métodos de procesamiento del lenguaje para mejorar la precisión del método.
- Evaluar el desarrollo de otras ontologías u otros métodos de expansión de consultas.
Recuperación de Documentos
- Objetivo: recuperar datos de artículos [+autores + fuentes de publicación] desde diferentes fuentes.
- Resultados:
- Fuentes actuales: Google Scholar, ACM DL, Microsoft Academic Search
- Se dispone de un middleware (no propio) para la recuperación.
- Se unificó la estructura de los datos a recuperar.


Trabajo pendiente
- Desarrollar procesos de ETL para los datos correspondientes a autores y fuentes de publicación [en proceso]
- Integrar otras fuentes de datos [ej: dblp, aminer, IEEE, etc.]
- Definir el método de persistencia a emplear [NoSQL "puro" - MongoDB / PostgreSQL + JSON]
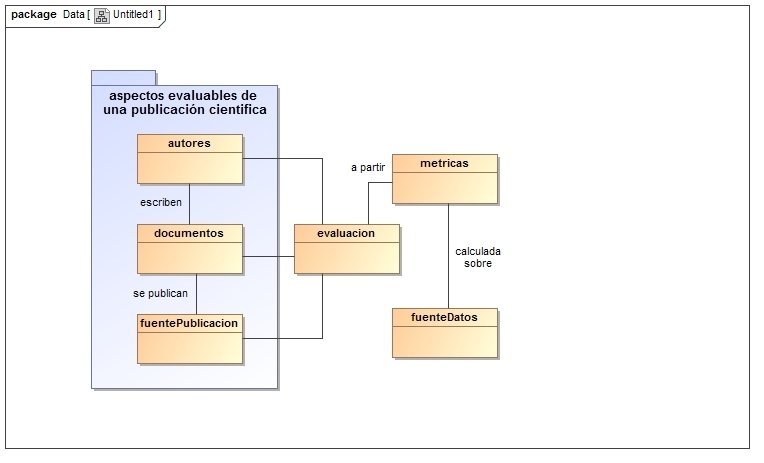
Algoritmo de Ranking
- Objetivo: disponer de un método para ordenar los resultados obtenidos en base a la relevancia que puedan tener para el usuario. En este caso, utilizando métricas de impacto de cada publicación científica.
- Resultados:
- Modelo conceptual desarrollado.
- Implementación parcial del método de aplicación del algoritmo.
- Relevamiento [inicial] de métricas a emplear.
- Versiones 1 y 2.
Trabajo pendiente
- Completar la definición de cómo se integrarían las métricas en los objetos almacenados en la BD para su utilización en el algoritmo [ej: junto con el autor / particular a una fuente]
- Definir métodos que se puedan integrar al algoritmo para mejorar los resultados a presentar al usuario [*]
- Definir nuevamente al algoritmo, interpretando de otras maneras los datos [ej: agregando campos de especialidad de un autor / fuente de publicación y relacionarlo con la consulta]
Ideas para seguir
- Perfiles de usuario para orientar búsquedas [~historial]
- [*] Adaptación del listado de resultados en base a la selección del área temática que hace el usuario, filtrando los que más relación tengan con la misma usando técnicas de topic modeling.
- Generar soluciones para aprovechar los datos almacenados:
- Vista previa de resultados
- Expansión de consultas
Programa de Investigación en Computación
2016
Avances Meta-buscador - Septiembre 2016
By Martin Rey
Avances Meta-buscador - Septiembre 2016
Avances Meta-buscador - Septiembre 2016



