Tomas Delvechio
Student, PHP and Python Developer. Newbie on Hadoop env.

Las presentes slides son una integración y traducción libre y personal de muchas otros trabajos (webs, blogs, artículos, diapositivas, libros, imágenes, etc...) que circulan por la web.
La intención es utilizarlos para fines estrictamente educativos, y se intento citar la fuente debidamente en cada caso. Cualquier error al respecto, será reconocido y modificado ante el correspondiente aviso.
"The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models."
A scalable fault-tolerant distributed system for
data storage and processing (open source
under the Apache license).
Hadoop provides a distributed file system and a framework for the analysis and transformation of very large data sets using the MapReduce paradigm.
Un sistema distribuido que propone una
metodología de desarrollo y procesamiento
que facilita la escalabilidad de aplicaciones.
Provee un Filesystem para el almacenamiento de datos y un modelo de programación para el procesamiento de los mismos.
Capacidad de crecer sin la necesidad de reimplementar la arquitectura o algoritmos de la aplicación. [CLO,2011]
Hadoop es un producto que escala.
Especificamente, provee escalabilidad horizontal.
¿Para que escalar?
[CLO,2011]
El proyecto Apache Nutch (Web Crawler) necesitaba estructuras y capacidad de procesamiento masivas.
En 2003 y 2004 se publican los artículos de MapReduce y GoogleFS, que serán los fundamentos de HADOOP.
En 2006 es fundado el proyecto Hadoop.
Yahoo! es uno de los actores que mas aportes realizo a que Hadoop sea lo que es hoy. En 2010, el 80% del código fuente del core de Hadoop era aportado por Yahoo! [SHV,2010]
Grep distribuido
Sort distribuido
Recorrido de grafos
Análisis de logs
Indexación invertida
Otros mencionados:
Doc clustering
Machine learning
Machine Translation
[DRO,2008]
Data Science - Big Data - IA
Hadoop 1 (Old-Stable)
MapReduce - HDFS
Hadoop 2 (Actual)
YARN - HDFS


http://drcos.boudnik.org
3 componentes principales del Framework
(Para cada uno de los servicios que ofrece)
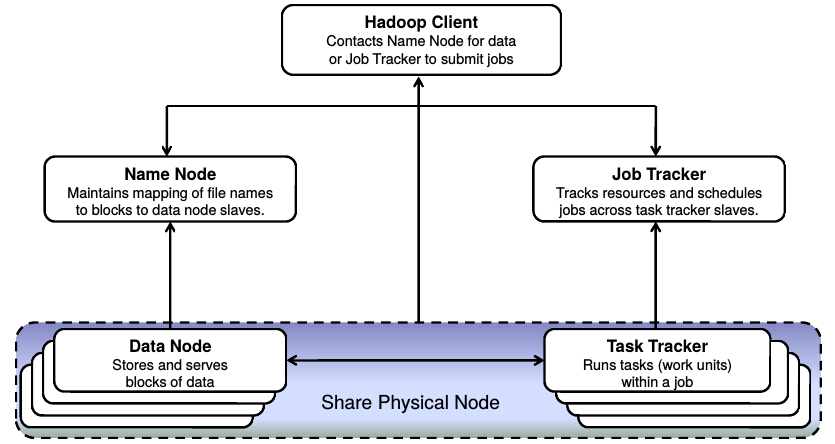

Por defecto solo hay un nodo Master,
que contiene los Masters de YARN
(ResourceManager) y de HDFS (NameNode).
Los Esclavos Incluyen los servicios esclavos de YARN (NodeManager) y de HDFS (DataNode)
Sistemas de archivos distribuido
Decenas de miles de nodos (al 2011)
Petabytes de almacenamiento
Redundancia mediante replicación
Manejo de fallas y recuperación
Low-cost Hardware
Modelo "Write once, read many"
Solo soporta "append" para archivos existentes


Conceptos y elementos básicos del DFS [SHV,2010]


Proceso de creación de CKP periódico
Nodo dedicado.
Creado a demanda (Por el administrador del cluster)
Propósito de backup previo a migración de versión.
Persiste TODO el FS (no solo los metadatos)
Como trabaja HDFS [GAR,2013]




Framework de procesamiento masivamente paralelo
Mas que un cambio de nombre. Scheduling de tareas en paralelo generalizado. MapReduce es un caso particular.


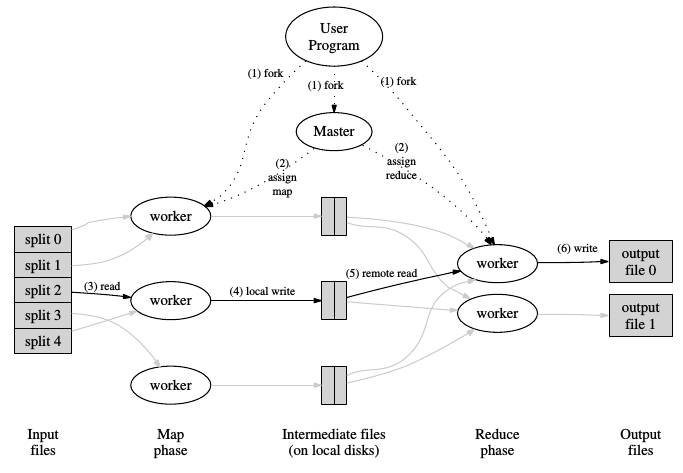
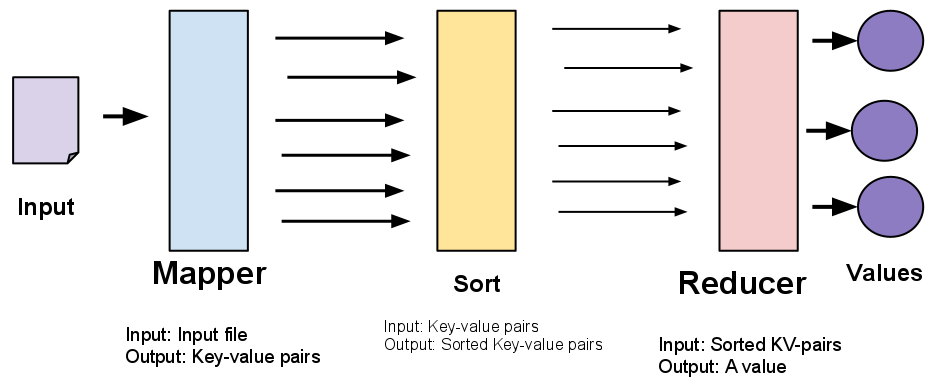
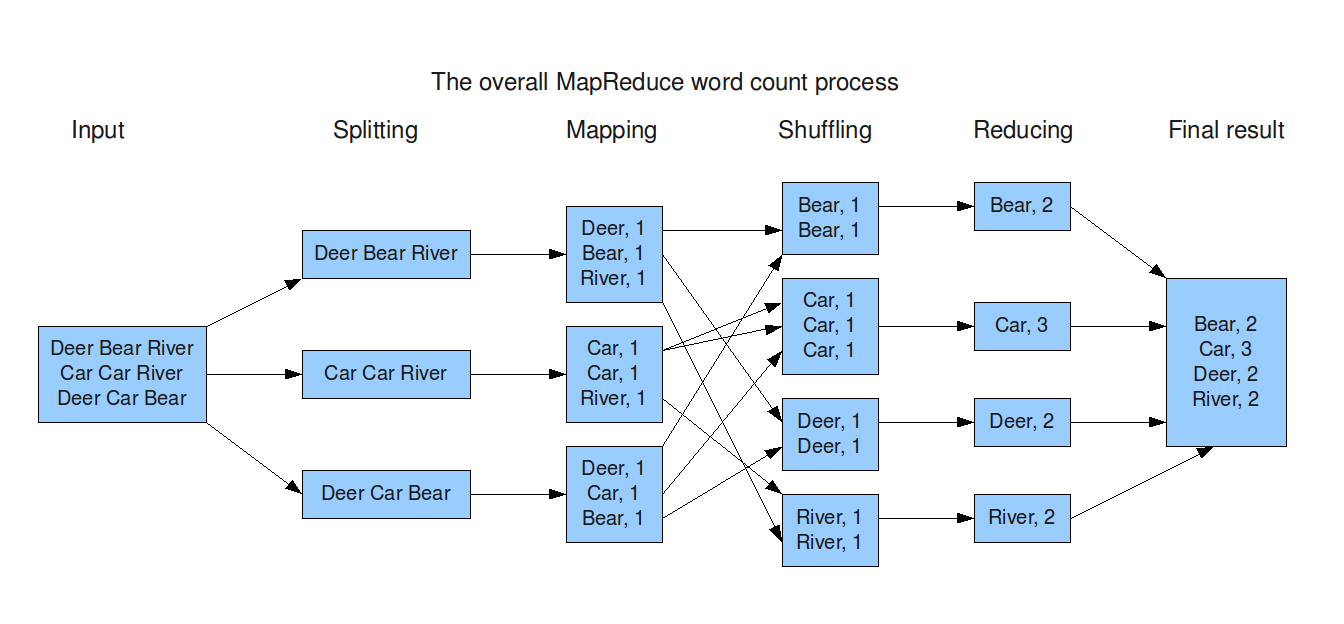
Como realiza el procesamiento con MapReduce
Existen 2 fases: El Map y Reduce.
Pero esto es una abstracción para los desarrolladores.
Los desarrolladores 'solo' programan un map y un reduce.
El framework trabaja por nosotros:

10TB = 10.485.760 MB
10.485.760 MB / 128 MB por Map = 81.920 ~ 82.000 Maps
Para tener 100 maps por nodo,
82.000 maps / 100 maps por nodo = 820 nodos
Como trabaja MapReduce [GAR,2013]


Pig: Lenguaje de alto nivel para análisis de datasets
Hive: Para DataWarehouse
HBase: Base de datos distribuida
Cassandra: NoSQL Database
Muchos mas...
Comunidades muy activas
general@hadoop.apache.org -> Lista de correo de anuncios
user@hadoop.apache.org -> Lista de usuarios de hadoop
StackOverflow: Suscripcion a los Tags
"Hadoop", "Hadoop 2", "Map Reduce"
Blogs, sitios, Cloudera, Hortonworks...
[HAD,2014]: Apache Hadoop Official Web. Enlace.
[CLO,2011]: Amr Awadallah. "Introducing Apache Hadoop: The Modern Data Operating System".
Stanford EE380 Computer Systems Colloquium. 2011. Enlace.
[HAL,2009]: A. Halevy et al, “The Unreasonable Effectiveness of Data”, IEEE Intelligent Systems, March 2009. Enlace.
[HOR,2014]: Hortonworks Project. YARN.
[LAM,2011]: Evert Lammerts. "Large-Scale Data Storage and Processing for Scientists in The Netherlands". NBIC BioAssist Programmers Day. 2011. Enlace.
[DRO,2008]: Isabel Drost. "Apache Hadoop. Large Scale data processing". 2008.
[DEA,2004]: Dean, J. Et. all. "MapReduce: Simplified Data Processing on Large Clusters". OSDI. 2004. Enlace.
[GHE,2003]: Ghemawat, S. Et. all. "The Google File System". ACM. 2003. Enlace.
[MCT,2011]: McTaggart, C. "Hadoop MapReduce". CSCI 5448 Course. 2011. Enlace.
[ROT,2014]: Rotem-gal-oz, A. "Is there a future for Map/Reduce?". DZone.com. 2014. Enlace.
[GAR,2013]: Garcia, M. "Hadoop 1.X vs Hadoop 2". Hortonworks. 2013. Enlace.
[SHV,2010]: Shvachko, K. Et. all. "The Hadoop Distributed File System". IEEE. 2010.
[WHI,2012]: T. White, Hadoop: The definitive guide, 2012.
[BON,2015]: Marko Bonaci. The history of Hadoop. Medium. 2015. Enlace.
By Tomas Delvechio
Presentación introductoria a HADOOP




