

Trang Le
#math graduate. Postdoc fellow with Jason Moore.
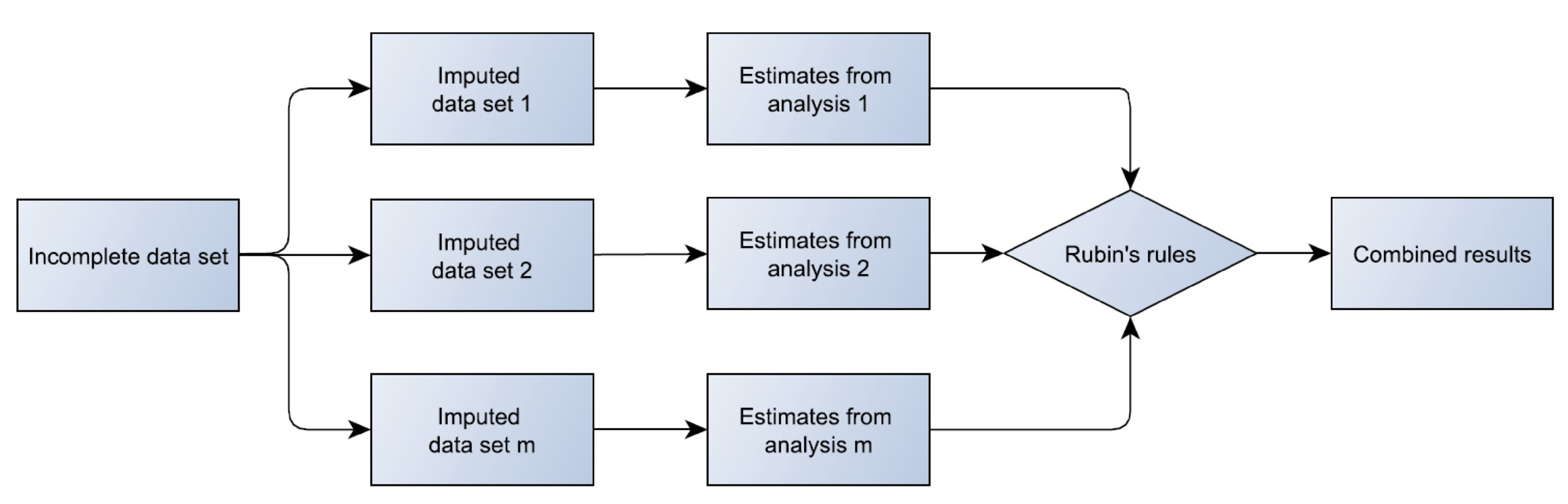
multiple imputation:
multiple copies of a data set
Step 1: Naively impute missing data points of each variable (e.g., with mean value)
Step 2: Put NAs back in the age variable where it was missing.
Step 3: Train age on income and gender (linear regression) with available data
Step 4 Use the fitted model to predict the missing age values.
Step 5: Repeat Steps 2–4 separately for each variable that has missing data, namely income and gender.
age, gender, income
for each cycle:
\(f(t_i)\) have a joint Gaussian distribution
locality constraint
closer time points have more similar measurement values
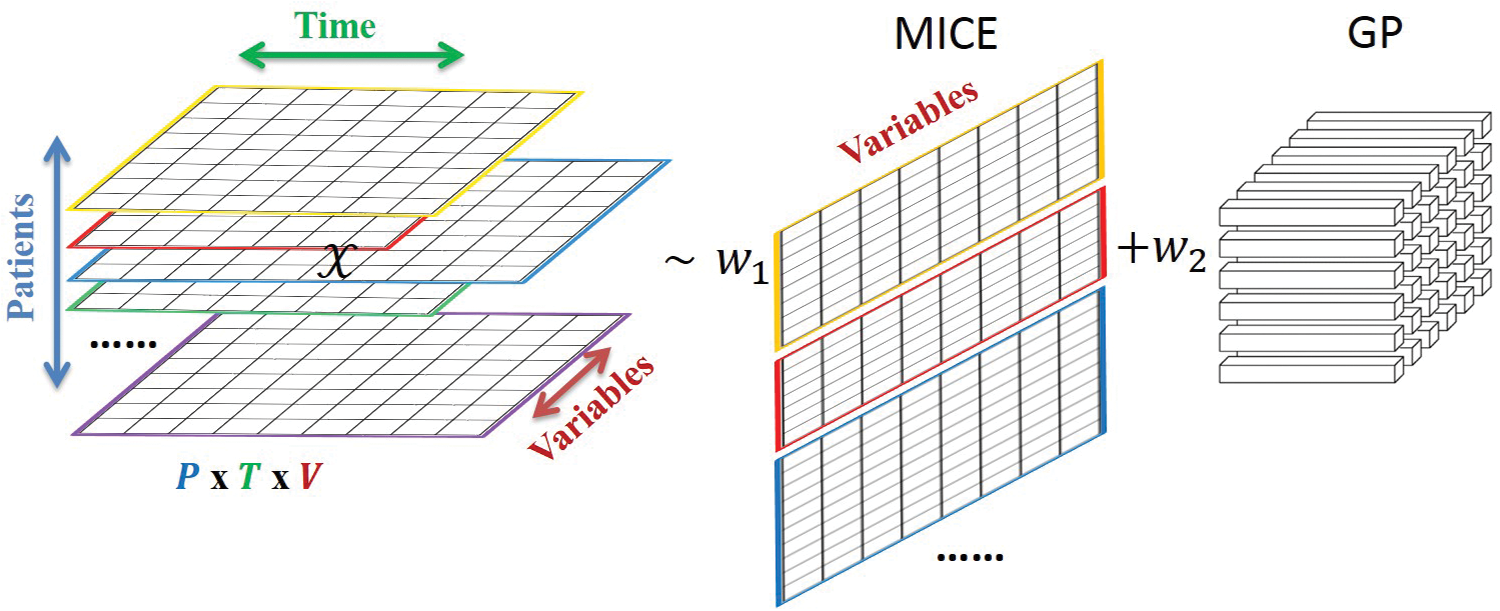
Step 1: extract separate univariate time series for each patient and variable
Step 2: GPfit: MLE over \(\alpha\) and \(l\)
Step 3: infer values at unobserved time points
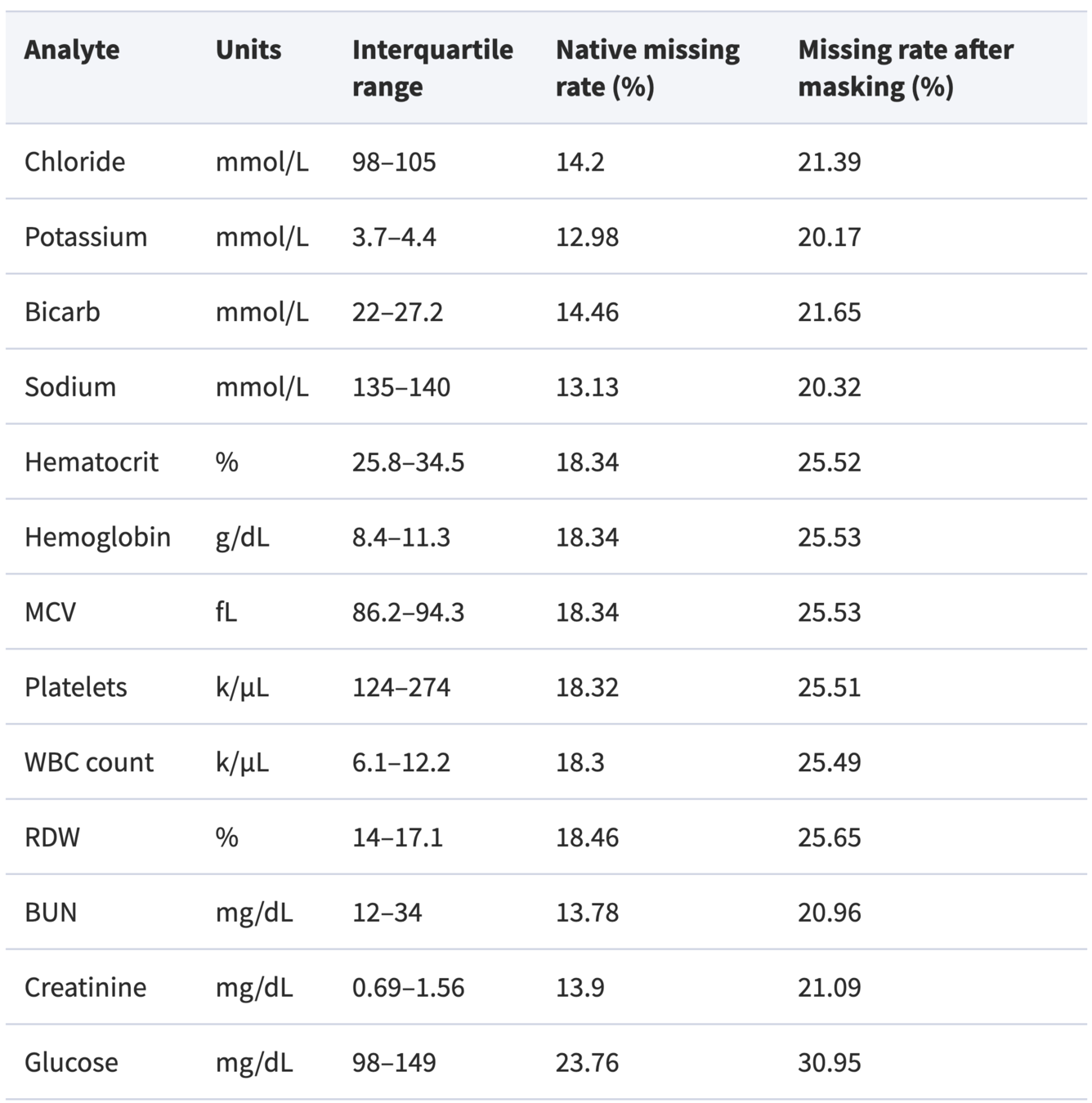
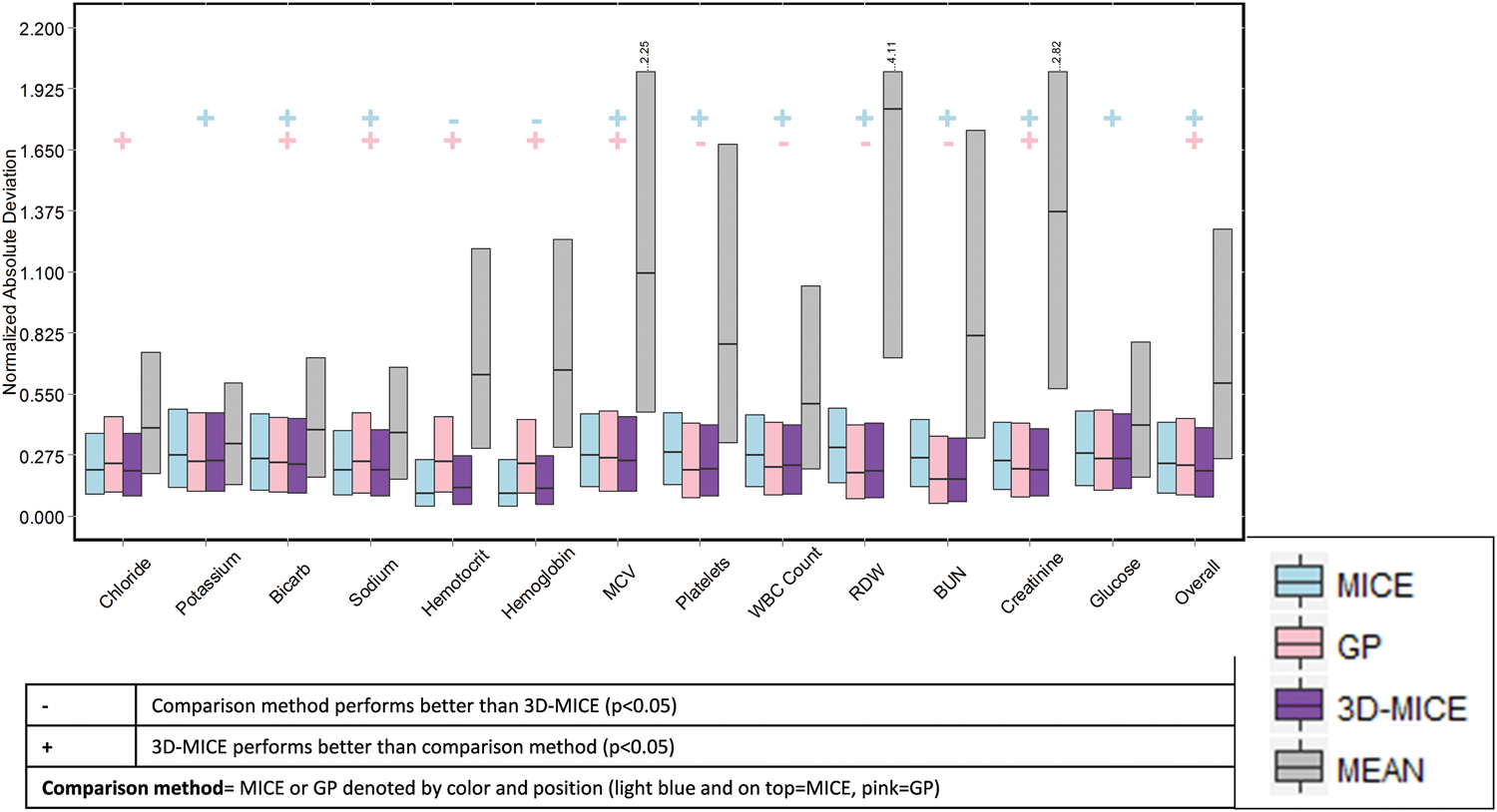
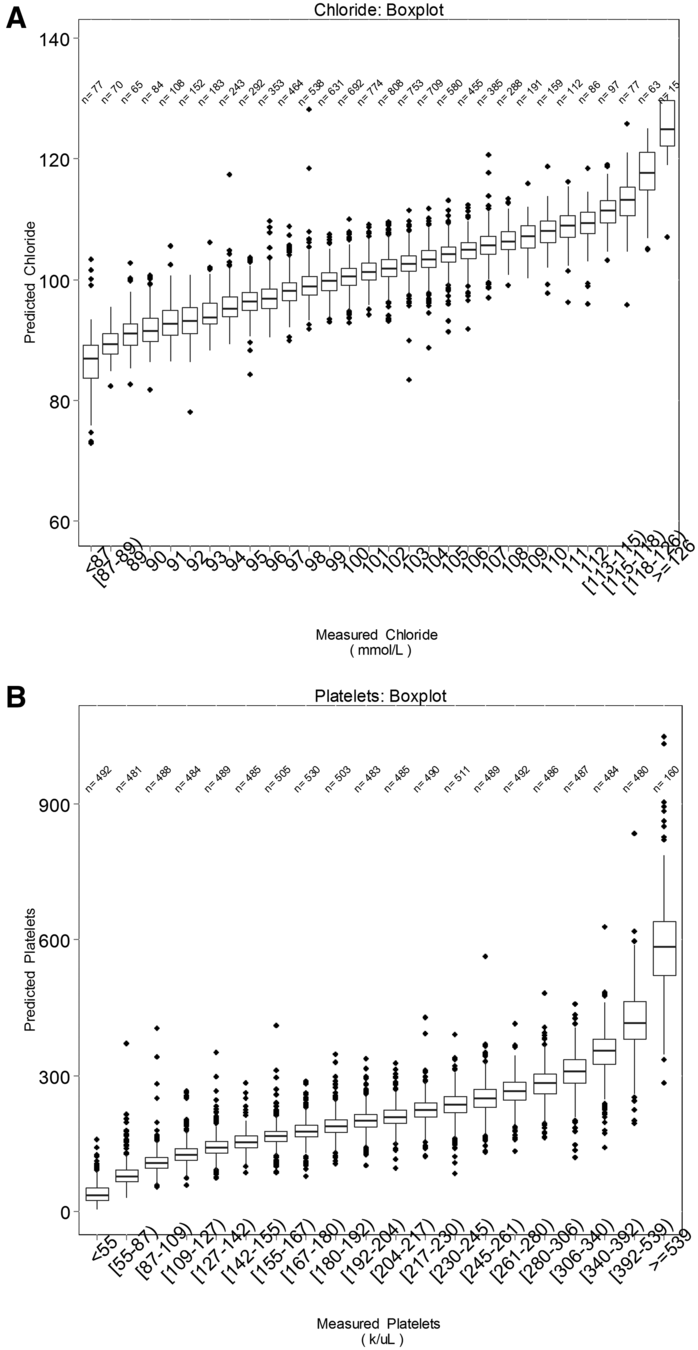
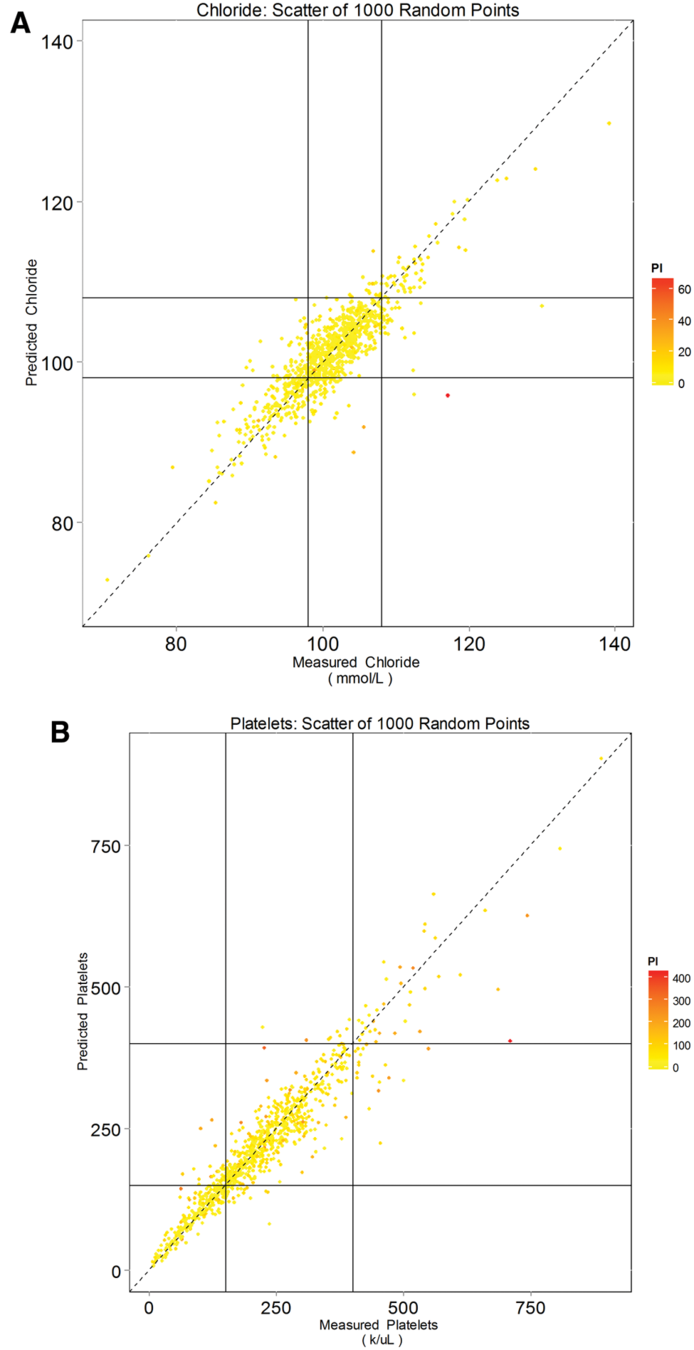
mask one result per analyte per patient
patient \(p\)
analyte \(a\)
time index \(i\)
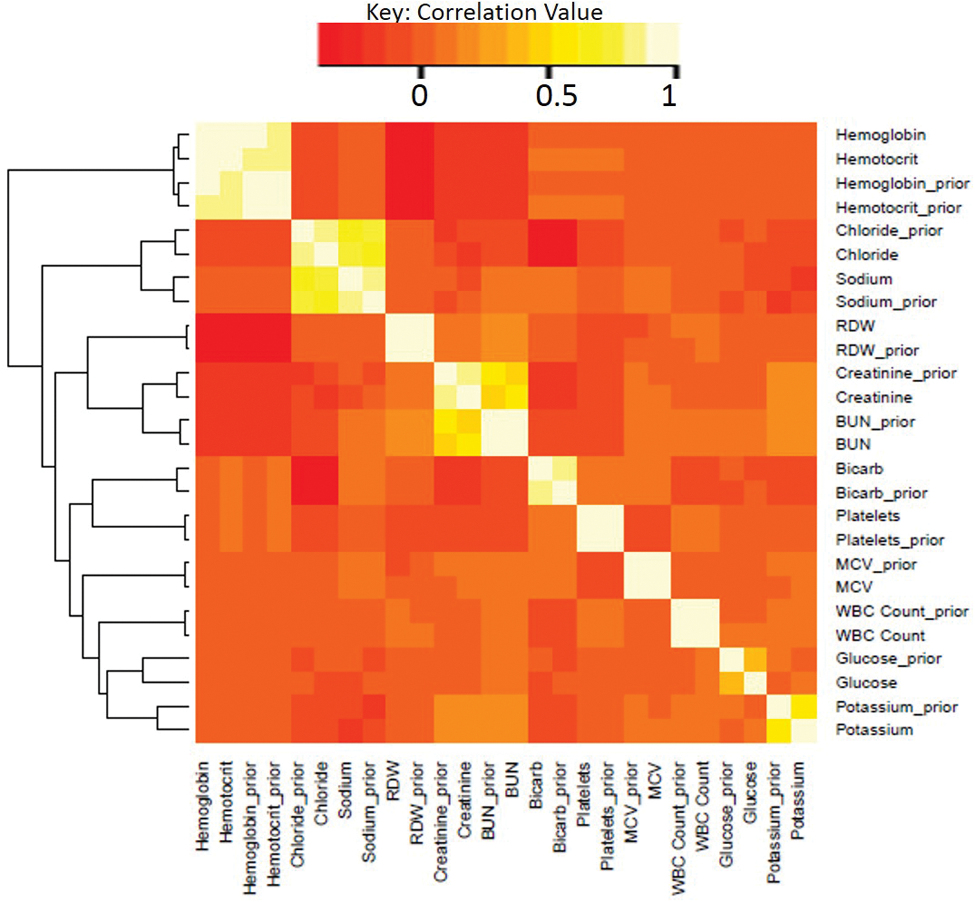
correlation between analytes and
between current and prior values for each analyte
By Trang Le
Kim lab journal club, 2020-12-10




