


Trang Le
#math graduate. Postdoc fellow with Jason Moore.
Disclaimer: I'll present a lot of suggestions from the paper, but I'll also discuss other points surrounding this topic and share my personal experience/opinionated practices.
already doing a lot of computation in their research/
software developers
new to scientific computing
2019-08-22
2020-06-11_good-enough-practices.pdf
2020-06-10_paper-thumbnail.png
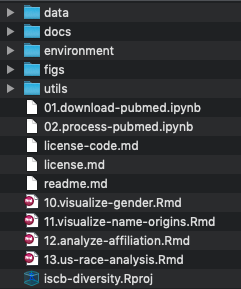
01.download-data.ipynb 02.process-data.ipynb 03.visualize-data.ipynb
#!/bin/bash
FILES=$(ls reformatted-data/train/hibachi*)
for fname in $FILES; do
echo "Processing $fname file..."
# run mbmdr on each file
for dimension in 1D 2D 3D; do
./mbmdr-4.4.1-mac-64bits.out \
--binary \
-d $dimension \
-o "${fname%.*}_output_$dimension.txt" \
-o2 "${fname%.*}_model_$dimension.txt" \
"$fname" > /dev/null 2>&1
done
done
mv -f reformatted-data/train/*_1D.txt results/
mv -f reformatted-data/train/*_2D.txt results/
mv -f reformatted-data/train/*_3D.txt results/
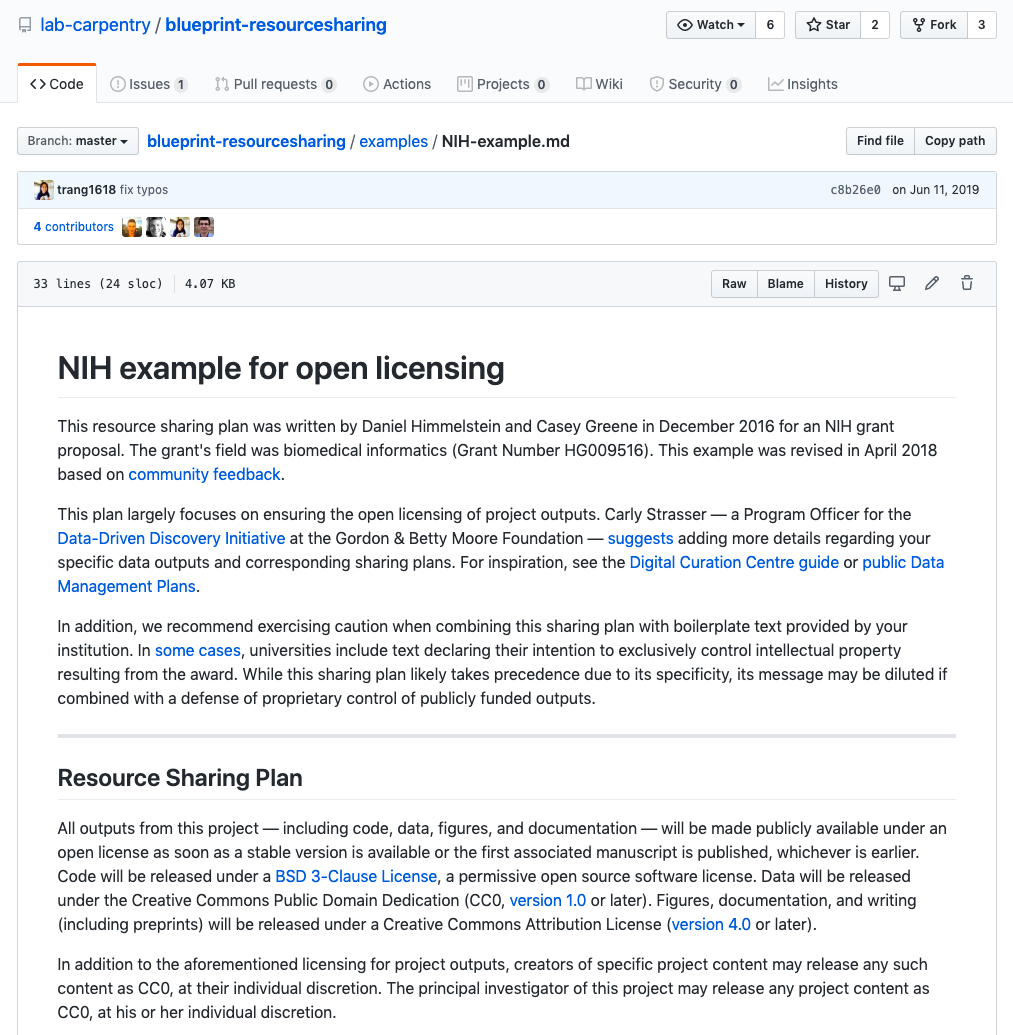
I use CC0
readable
reusable
testable
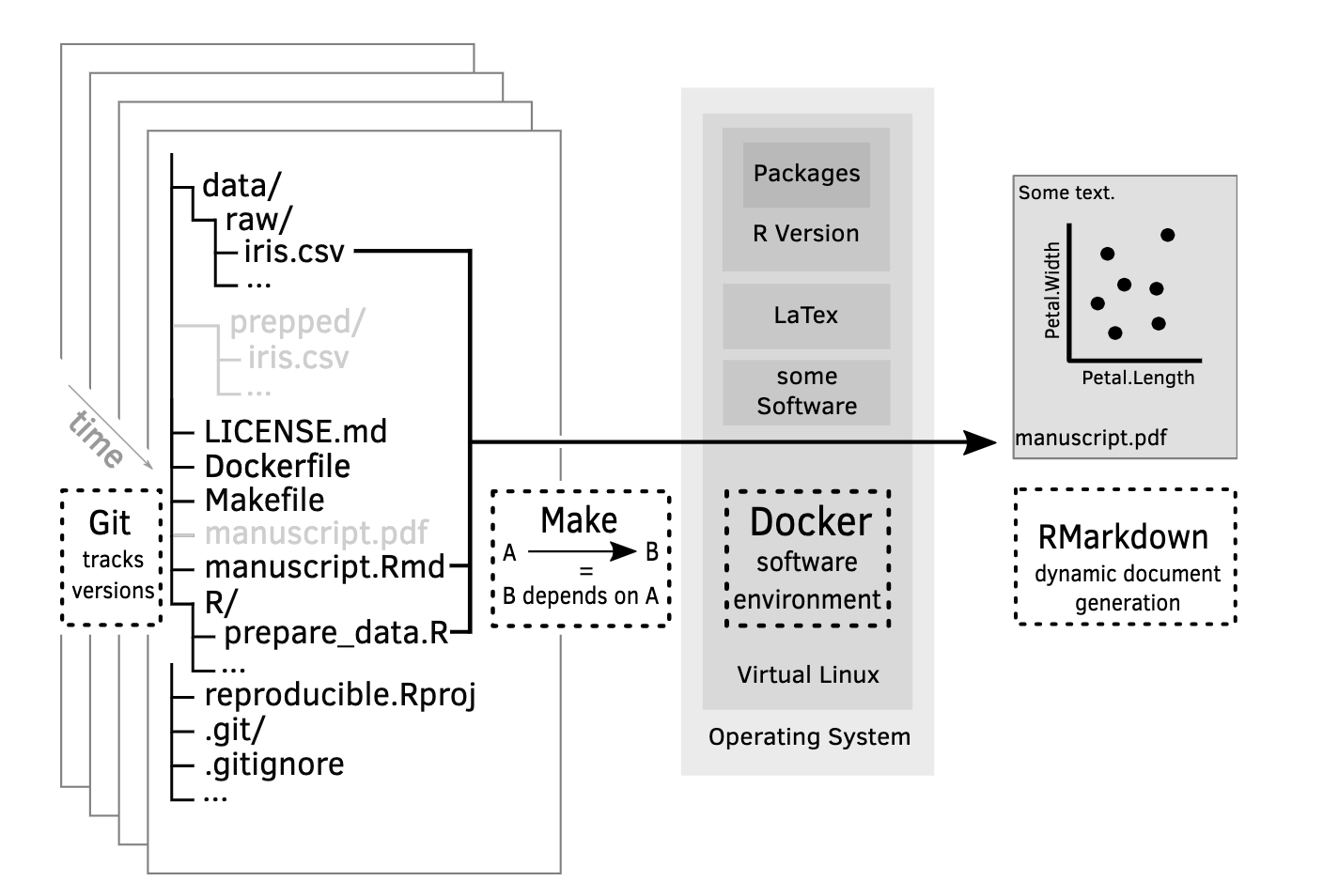
.svg, .png, .eps
.html
.R, .py
Dockerfile
raw/ processed/ metadata/
can be under
src/ scripts/
etc.
Copy the entire project whenever a significant change has been made.
1Tb hard drive = $50
50 Gigabytes < $5
(many advantages in Box 4)
I still do!!!
I still do!!!
I still do!!!
But be aware of the changes (or at least the size of the changes) you're making!
Doing the research is the first 90% of any project; writing up is the other 90%.
…try to explain the notion of compiling a document to an overworked physician you collaborate with. Oh, but before that, you have to explain the difference between plain text and word processing. And text editors. And Markdown/LaTeX compilers. And BiBTeX. And Git. And GitHub. Etc. Meanwhile, he/she is getting paged from the OR…
Google Docs excels at easy sharing, collaboration, simultaneous editing, commenting, and reply-to-commenting. Sure, one can approximate these using text-based systems and version control. The question is why anyone would like to…
The goal of reproducible research is to make sure one can reproduce… computational analyses. The goal of version control is to track changes to source code. These are fundamentally distinct goals, and while there is some overlap, version control is merely a tool to help achieve that and comes with so much overhead and baggage that it is often not worth the effort.
Stephen Turner
Arjun Raj
This is a sentence with 5 citations [ @doi:10.1038/nbt.3780; @pmid:29424689; @pmcid:PMC5938574; @arxiv:1407.3561; @url:https://greenelab.github.io/meta-review/ ].
This is a sentence with 5 citations [1,2,3,4,5].
CC-BY 4.0
Use archive services:
By Trang Le
Kim lab journal club, 2020-06-11



