




Trang Le
#math graduate. Postdoc fellow with Jason Moore.
Michael Kearns and Aaron Roth
2019
Cathy O'Neil
2016
Algorithms are currently deployed in
If we strictly adhere to ‘save the most lives’ principle, we will be treating more white people, more men, more wealthy people.
A metaanalysis of 20 years of published research found that
Black patients were 22% less likely than
white patients to get any pain medication and
29% less likely to be treated with opioids.
In minority communities, racial discrimination is thought to increase the magnitude of existing stigma against substance users, creating a “double stigma.” Add to all that the common characterization of “innocent white victims” of over-prescribing by health-care providers, which can create the misimpression that black patients who do develop opioid use disorder are more to blame than white patients. Thus a third layer of stigma is created.
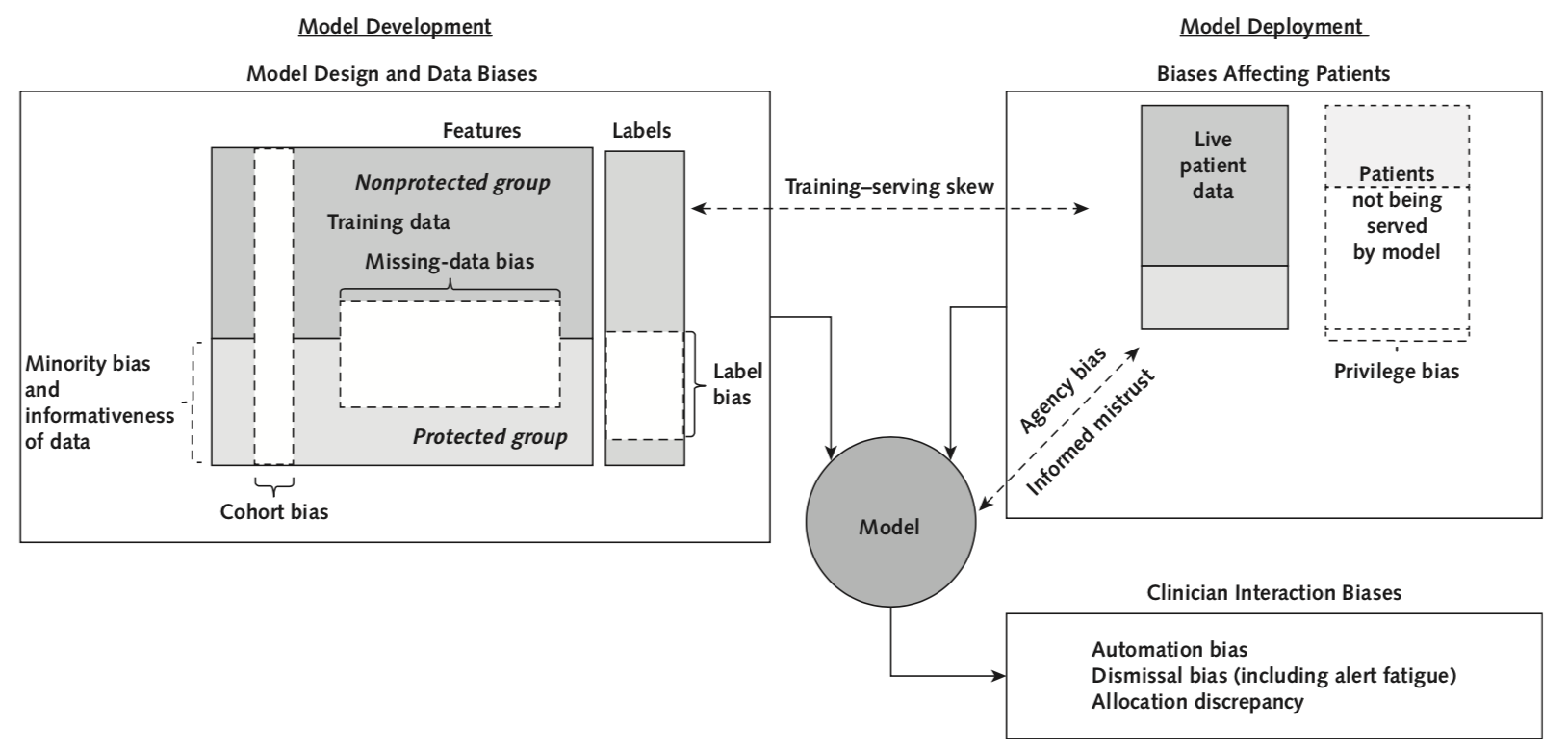
Potential issue: too few Black patients
→ Within this protected group:
automation bias
dismissal bias
Potential issue: patients in predominantly Black neighborhoods are predicted to have longer stays
→ resource allocated away from these patients
issue: less accurate on people of color
(measurement are systematically inaccurate)
The MDRD equation underestimates the prevalence of chronic kidney disease among blacks and overestimates the prevalence of CKD among whites compared to the CKD-EPI equation
If race is excluded, more black patients could also be falsely labeled as having kidney disease or having a more advanced stage of disease, potentially leading to anxiety or unnecessary treatment.
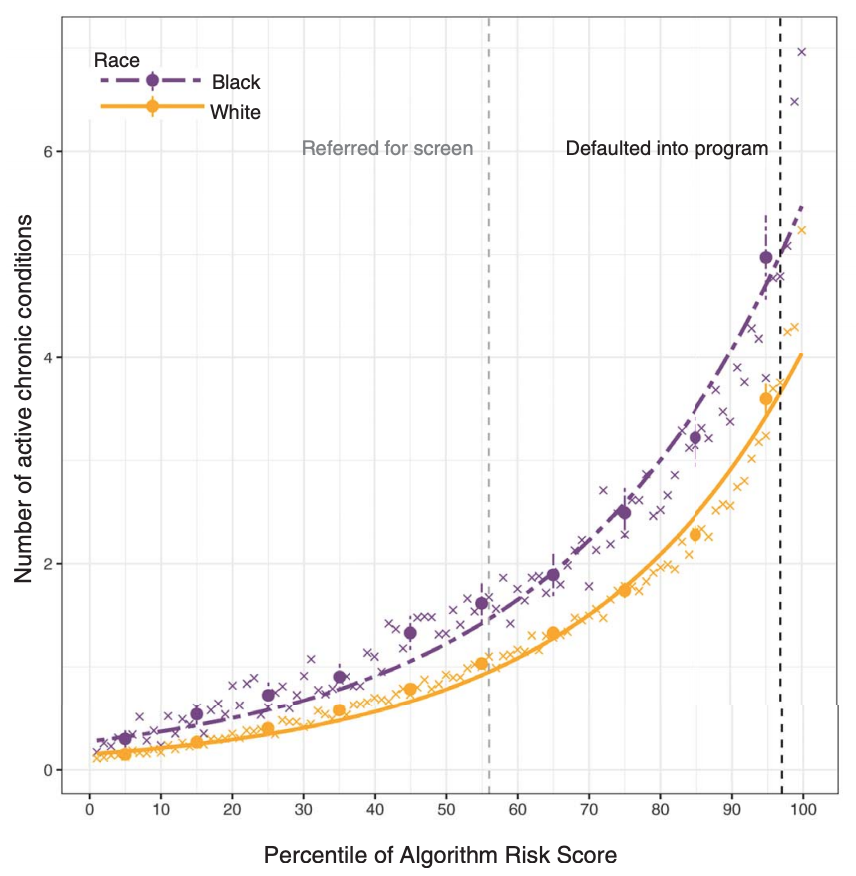
use health care expense as a proxy for sickness level
but Black patients received less health care for a given sickness level
La Cava & Moore, GECCO 2020
Recent results show that the problems of both learning and auditing classifiers for rich subgroup fairness are computationally hard.
Train a model taking into account the fairness goals.
Evaluate whether a model should be launched with all stakeholders, including representatives from the protected group.
Scientists are some of the most dangerous people in the world because we have this illusion of objectivity
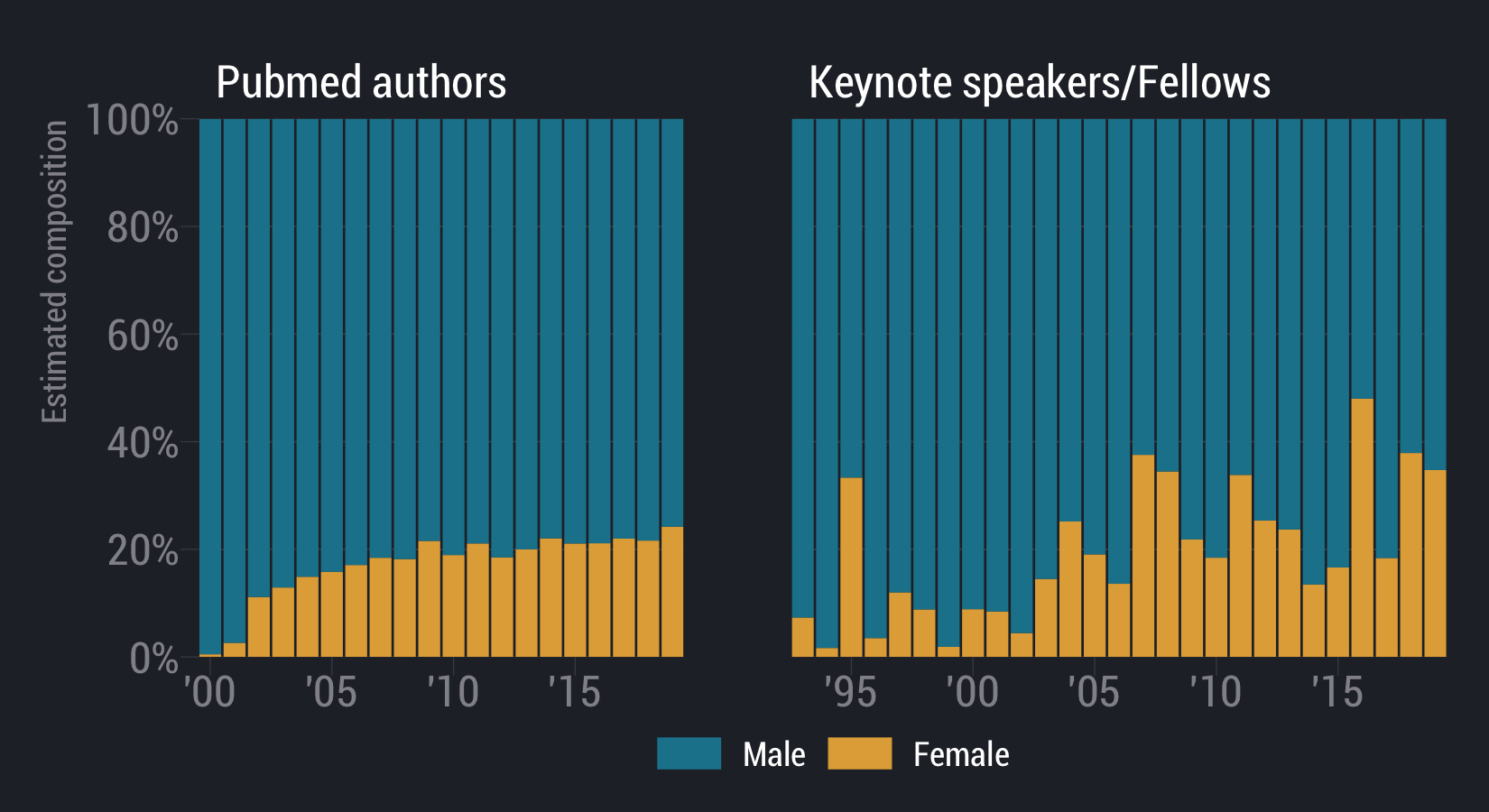
Le et al. 2020, bioRxiv
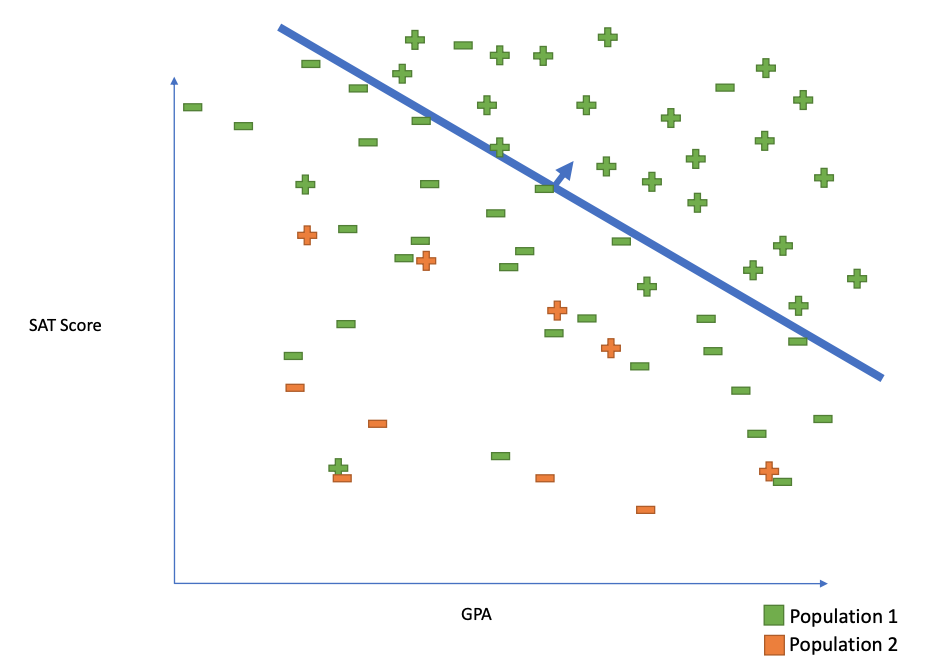
Individual fairness
similar individuals treated similarly
Statistical Parity
Ask for equivalent error rates across protected attributes (e.g. race, sex, income)
Subgroup Fairness
ask for equivalent error rates intersections/conjunctions of groups
By Trang Le
Kim lab journal club, 2020-08-27




